SqlWorkload
SqlWorkload is a command line tool to start workload collection, analyze the collected data and replay the workload to a target machine.
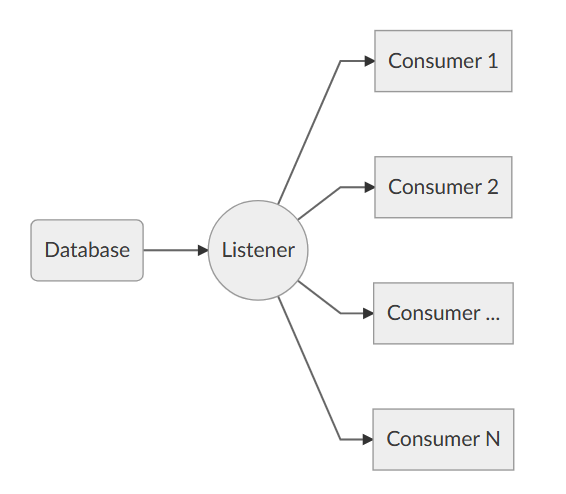
The main concepts in SqlWorkload are two: Listeners and Consumers.
Listeners allow SqlWorkload to capture workload events from a source and publish them to a list of consumers. An instance of SqlWorkload can make use of a single listener, but it can publish the events to multiple consumers at the same time.
SqlWorkload accepts two command line switches:
--Log Path to the log file
--File Path to the .JSON configuration file
In fact, SqlWorkload supports a multitude of parameters and specifying them all in the command line can become really tedious. For this reason, SqlWorkload supports .JSON configuration files.
A typical .JSON file looks like this:
{
// This section is fixed
"Controller": {
// The Listener section describes how to capture the events.
// There is always one listener and zero or more consumers
"Listener":
{
// The main parameter here is the class type of the Listener
// At the moment, four Listener types are supported
// - ExtendedEventsWorkloadListener
// - SqlTraceWorkloadListener
// - ProfilerWorkloadListener
// - FileWorkloadListener
"__type": "ExtendedEventsWorkloadListener",
// Each Listener type has its own set of Properties
// that you can set on the .JSON file
// See the documentation of each listener type
// for the list and description of the supported Properties.
// The ConnectionInfo describes how to connect the Listener
// Many (but not all) listener types support this property
"ConnectionInfo":
{
"ServerName": "SQLDEMO\\SQL2014",
// If you omit the UserName/Password, Windows authentication
// will be used
"UserName": "sa",
"Password": "P4$$w0rd!"
},
// Filters for the workload
// These are not mandatory, you can omit them
// if you don't need to filter.
// Prepend the '^' character to exclude the value
"DatabaseFilter": "DS3",
"ApplicationFilter" : "SomeAppName",
"HostFilter" : "MyComputer",
"LoginFilter": "sa"
},
// This section contains the list of the consumers
// The list can contain 0 to N consumers of different types
"Consumers":
[
{
// This is the type of the consumer
// Four types are available at the moment:
// - ReplayConsumer
// - AnalysisConsumer
// - WorkloadFileWriterConsumer
"__type": "ReplayConsumer",
// The same considerations for ConnectionInfo
// valid for the Listener apply here as well
// See the documentation of the individual
// Consumer type for the list of the supported properties
"ConnectionInfo":
{
"ServerName": "SQLDEMO\\SQL2016",
"DatabaseName": "DS3",
"UserName": "sa",
"Password": "P4$$w0rd!"
}
},
{
// Here is another example with the AnalysisConsumer
"__type": "AnalysisConsumer",
// ConnectionInfo
"ConnectionInfo":
{
"ServerName": "SQLDEMO\\SQL2016",
"DatabaseName": "DS3",
// This "SchemaName" parameter is important, because it
// decides where the analysis data is written to
"SchemaName": "baseline",
"UserName": "sa",
"Password": "P4$$w0rd!"
},
// This decides how often the metrics are aggregated and
// written to the target database
"UploadIntervalSeconds": 60
}
// I could add more consumer definitions here...
]
}
}More examples can be found throughout the documentation and in the /WorkloadTools/Config folder in the sources.
WorkloadTools includes listeners to collect workload events from a number of sources, depending on your needs. You have listeners to collect events from SqlTrace, Extended Events or from a saved workload file.
Here is the complete list:
-
ExtendedEventsWorkloadListener: can capture events from an extended events session, using the streaming API or reading the .XEL files in the output folder in an incremental fashion. This is the recommended listener for capturing workloads from a live SQL Server instance.
-
FileWorkloadListener: reads workload events from a saved workload file
-
ProfilerWorkloadListener: can capture events from a SQL Server instance by leveraging the profiler API from Microsoft. This listener only works in the 32 bit implementation (the API is only available through a 32 bit DLL) and can have a severe performance impact on the server.
-
SqlTraceWorkloadListener: captures the workload events by reading the rollover files of a server-side SqlTrace in an incremental fashion. This is the safer and more performant way to work with SqlTrace in older versions of SqlServer
All workload listeners also capture additional metrics about the source system (live SQL Server instance or workload file) and inject these metrics in the workload, in order to better describe the state of the system being observed. These are the metrics collected:
- cpu usage
- wait statistics
In the following section, you will find the detailed description of each listener type, with all the available properties. Each of these properties can be set from the .json configuration file, depending on the listener type that you are using.
For each property, you will find the property type and the property name (e.g. string ServerName).
Optional properties are enclosed in square brackets [] (e.g. [string Source])
Defaults are appended to optional properties (e.g. [int TraceRolloverCount = 30])
All listener types inherit from this abstract class. It contains the definition of all the Properties common to every listener type.
Available properties:
-
SqlConnectionInfo ConnectionInfo
Describes how to connect to the SQL Server instance that you want to observe.
Collectively, theConnectionInfoproperty can be set by nesting it inside the .JSON configuration file as shown in the example above. TheSqlConnectionInfoobject is comprised of many attributes:-
string ServerName
Name of the server to connect to -
[string DatabaseName]
Name of the database to open -
[string SchemaName]
Name of the schema to which database objects (tables) are written. Applies toAnalysisConsumer. -
[string UserName]
User Name to connect to the database using SQL Server authentication. When omimtted or whenUseIntegratedSecurityis set toTrue, Windows authentication is used instead. -
[string Password]
Password to authenticate to the SQL Server instance. Ignored when using Windows authentication -
[bool UseWindowsAuthentication]
Instructs SqlWorkload to use Windows authentication when connecting to the database server. Is implicitly set toTruewhenUserNameis not set. -
[string ApplicationName]
Application Name to use when connecting to the database server.
-
-
[string Source]
Depending on the listener type, it can have different meanings. It could be the path to the .sql script that defines how to create the XE session or the SqlTrace or it could be the path to the .sqlite database that contains the events to read. Please refere to the documentation of the individual listener type for more information. -
[string ApplicationFilter]
Specifies an application filter for the events captured by the listener. Specify here a value to include when matched exactly (e.g.MyApplication) or prepend the^sign to specify a value to exclude when matched exactly (e.g.^MyApplication) -
[string DatabaseFilter]
Fiter to appy to the Database Name field. -
[string HostFilter]
Fiter to appy to the Host Name field. -
[string LoginFilter]
Fiter to appy to the Login Name field. -
[int StatsCollectionIntervalSeconds = 60]Listeners can collect performance metrics (performance counters and wait statistics) while collecting execution events. This property controls how often those metrics are collected. The default is 60 seconds. -
[DateTime StartAt = DateTime.Now]
Sets a time when collection starts. SqlWorkload will sit waiting for the time indicated here. Please use a safe date/time format likeyyyy-MM-dd HH:mm:ss -
[int TimeoutMinutes = 0]
Defines how long the capture needs to last before shutting it down. When set to 0, it captures indefinitely.
The ExtendedEventsWorkloadListener reads the events from an Extended Events session. There are two flavours of this listener, that behave in two different ways.
The first type reads the events directly from the stream of the XE session, using the streaming API. This type is the default when working with on-premises instances of SQL Server and whenever the property FileTargetPath is not set.
The second type reads the events from a file target in an incremental manner, keeping track of the last rollover file visited and the offset inside the file. The events are read using the function sys.fn_xe_file_target_read_file, which is notoriously CPU intensive, even if specifying which file to read from and the offset inside the file can contribute taming the hunger for CPU cycles of this function.
This type of ExtendedEventsWorkloadListener is the default for Azure SqlDatabase and whenever the property FileTargetPath is set.
Available properties:
-
[string Source]
Path to the .sql script that defines how to create the XE session. You can refer to the file/Listener/ExtendedEvents/sqlworkload.sqlunder the installation folder to see what a typical script looks like. The numeric placeholders {0},{1},{2} are replaced with the following values:- {0} : filters
- {1} : session type (
DATABASE|SERVER) - {2} : principal type (
username|server_principal_name)
-
[string FileTargetPath]
When specified, instructs the listener to read events from the XE file target associated with the session. This is mandatory for Azure SqlDatabase and must be set to the http URL of the blob storage container where the XE data is written to. This information can be configured in the Azure portal, as described in this article https://blogs.msdn.microsoft.com/azuresqldbsupport/2018/03/13/extended-events-capture-step-by-step-walkthgrough/ .
When working with a full instance of SQL Server (on-premises instance or Azure VM), this Property can be set to the path of a filesystem folder where the XE file target files are placed.
When omitted and not working with Azure SqlDatabase, the streaming API is used to pull the events from the session. -
[string SessionName = sqlworkload]
Name of the XE session. When specifying a custom script to create your own session, this name and the name in the script must match.
A FileWorkloadListener reads the events from a saved workload file. This is particularly useful when the goal is to replay the same exact workload against a target environment under different conditions, in order to compare the benchmarks.
Available properties:
-
[string Source]
Path to the .sqlite database that contains the events to read. -
[bool SynchronizationMode = true]
When set totrue, it instructs the listener to raise the events using the same wait times found in your workload. When set tofalse, it does not interpone any wait time between the queries, running them as fast as possible.
This listener type uses the Profiler API to create a trace and attach to it to read the events. As pointed out multiple times, the Profiler API is 32 bit only, so it won't work on x64 versions of SqlWorkload. It is not recommended to use this listener type, because the Profiler API can put a non-negligible load on the server.
Available properties:
-
[string Source]
Path to the .tdf trace template to create the trace.
This listener type uses a server-side trace to capture the events. Instead of reading the events directly from the file using the API (again, 32 bit only), it uses the T-SQL function fn_trace_gettable to read the contents of the trace files directly from the server, without accessing its filesystem. The trace is configured to use rollover files of the size specified in the property TraceSizeMB, up to a maximum of rollover files specified by the property TraceRolloverCount. The goal is to keep the rollover files as small as possible, so that the listener can query the files without having to scan huge amounts of trace events.
Available properties:
-
[string Source]
Path to the .sql script to create the trace. You can refer to the file/Listener/Trace/sqlworkload.sqlunder the installation folder to see what a typical script looks like. The numeric placeholders {0},{1},{2},{3} are replaced with the following values:- {0} : trace file size in MB
- {1} : trace rollover file count
- {2} : path to the trace file
- {3} : filters For the sake of your own sanity, while you can include these placeholders in a custom trace creation script, it is advised to either use the default script (by omitting the property altogether) or use a custom script that already contains all the values explicitly.
-
[int TraceSizeMB = 10]Size in MB of the trace rollover files -
[int TraceRolloverCount = 30]Maximum number of trace rollover files
The workload events captured by the listener are then passed to all the consumers registered to it. The consumers are designed to implement the typical activities that take place during a benchmarking session: saving the workload to a file for later replay, analyzing the workload, replaying the events to a target SQL Server instance (on-premises or in the cloud).
These are the available consumer types:
-
AnalysisConsumer: processes the events to extract information about the workload. Can “normalize” the batches (strips away parameters and constants) and calculates execution metrics like cpu time, duration, reads and writes. The data is then available for display or for comparison with another analyzed workload.
-
ReplayConsumer: executes all the batches from the captured workload to a target machine
-
WorkloadFileWriterConsumer: writes all the events to a target file, so that it can be later used as a source for a replay or for workload analysis.
This consumer type takes care of normalizing queries and aggregating the performance data (reads, writes, cpu, duration, number of executions) for each normalized query inside an interval.
Intervals are defined by the property UploadIntervalSeconds, which controls how often the normalized queries and their performance data are aggregated and written to the destination database.
Query normalization consists in replacing all literals with placeholders, in order to aggregate performance metrics for queries that are not identical, but differ only on the literal values. This happens a lot with ad-hoc workloads, especially when the application fails to parameterize correctly.
Here is an example:
-- Query 1:
-- reads: 112, writes: 0, cpu: 8, duration: 32
SELECT Id FROM Customers WHERE Name LIKE 'Constructions%'
-- Query 2:
-- reads: 118, writes: 0, cpu: 9, duration: 33
SELECT Id FROM Customers WHERE Name LIKE 'Financial%'
-- Query 3:
-- reads: 126, writes: 0, cpu: 11, duration: 38
SELECT Id FROM Customers WHERE Name LIKE 'Consulting%'If we replace the literal values with a placeholder, we can consider all three queries as if they were the same:
-- Normalized Query
-- avg reads: 118, avg writes: 0, avg cpu: 9, avg duration: 34
SELECT Id FROM Customers WHERE Name LIKE {STR}The syntax for placeholders and the rules for normalization are the same found in ClearTrace, so if you know that tool and are used to its way of normalizing queries, this will not be a new concept for you.
AnalysisConsumer also takes care of calculating a query hash based on the text of the normalized query. The hashing algorithm is different from the one used by SQL Server internally (it is not documented) and produces a 64 bit integer number (bigint if you prefer). This query hash can be used to aggregate the performance data inside each interval and correlate with other intervals.
Every UploadIntervalSeconds, the data gets written to the analysis database. The schema of the analysis database can be found here. Basically, for each benchmark that we capture, we use a different schema in the same analysis database or in a different database. Each schema will contain all the tables that hold the benchmark data and we can point the analysis tools provided with WorkloadTools (WorkloadViewer and the PowerBI dashboard) to those schemas, in order to compare different benchmarks.
The AnalysisConsumer does not extract performance data only from the normalized queries, but it also reads additional performance metrics from the listener, such as performance counters and wait statistics. These metrics are written to the analysis database too, using the same logic of aggregation based on intervals.
Available properties:
-
SqlConnectionInfo ConnectionInfo
Describes how to connect to the SQL Server instance where you want to write the analysis data.
TheSqlConnectionInfoobject is comprised of many attributes:-
string ServerName
Name of the server to connect to -
string DatabaseName
Name of the database to open -
string SchemaName
Name of the schema to which database objects (tables) are written. -
[string UserName]
User Name to connect to the database using SQL Server authentication. When omimtted or whenUseIntegratedSecurityis set toTrue, Windows authentication is used instead. -
[string Password]
Password to authenticate to the SQL Server instance. Ignored when using Windows authentication -
[bool UseWindowsAuthentication]
Instructs SqlWorkload to use Windows authentication when connecting to the database server. Is implicitly set toTruewhenUserNameis not set. -
[string ApplicationName]
Application Name to use when connecting to the database server.
-
-
int UploadIntervalSeconds
Controls how often the performance data is aggregated and written to disk. There is no default for this property: choose wisely what is best in your environment. It could vary wildly, from 60 seconds to 3600 seconds: just keep in mind that the individual events are kept in memory until the moment they are aggregated and written to the analysis database. If you have a very busy workload, writing to the analysis database more often (every 60 seconds, for instance) does not only give a more accurate description of the workload itself, but it also allows using less memory to store the events before the aggregation occurs. -
[int MaximumWriteRetries]
Number of retries when writing to the analysis database. SqlWorkload will stop trying to write the analysis data for the current interval when this number of retries is exceeded. -
[bool SqlNormalizerTruncateTo4000 = false]
When true, truncates the normalized query text at 4000 characters. -
[bool SqlNormalizerTruncateTo1024 = false]
When true, truncates the normalized query text at 1024 characters.
This consumer type takes the events received from the listener and replays them to a target database.
It uses multiple threads to execute the replay, one thread for each SPID found in the source workload. Each SPID is assigned to a ReplayWorker, that runs in its own thread and replays all the events for the source SPID.
Available properties:
-
SqlConnectionInfo ConnectionInfo
Describes how to connect to the SQL Server instance where you want to replay the workload. TheSqlConnectionInfoobject is comprised of many attributes:-
string ServerName
Name of the server to connect to -
string DatabaseName
Name of the database to open -
[string UserName]
User Name to connect to the database using SQL Server authentication. When omitted or whenUseIntegratedSecurityis set toTrue, Windows authentication is used instead. -
[string Password]
Password to authenticate to the SQL Server instance. Ignored when using Windows authentication -
[bool UseWindowsAuthentication]
Instructs SqlWorkload to use Windows authentication when connecting to the database server. Is implicitly set toTruewhenUserNameis not set. -
[string ApplicationName]
Application Name to use when connecting to the database server. When not specified, the default is "SqlWorkload", but it can be set to mimic the original application name. -
[string MaxPoolSize]
Maximum size of the connection pool to the database. The default is 500.
-
-
[bool DisplayWorkerStats = true]
Controls whether status information get written to the output and log at regular intervals. The messages look like this:Worker [##] - ## commands executed. Worker [##] - ## commands pending. Worker [##] - ## commands per second. -
[bool ConsumeResults = true]
Controls whether the result sets of the queries get consumed or discarded. This is particularly important when the application reads a lot of rows or columns for each command (ORMs anyone?) and the time it takes to move that data form the server to the client is a non negligible part of the overall duration of the queries.
Another scenario where turning on this setting is useful is when the target database resides on a different network from the application (example: you want to move the database to the cloud but keep the application on-premises). In those cases, the network latency is a crucial aspect of the migration and has to be taken into account thoroughly. -
[bool QueryTimeoutSeconds = 30]
Query timeout, in seconds. When exceeded, queries will be recorded as failed. -
[int WorkerStatsCommandCount = 1000]
Used in conjunction withDisplayWorkerStats: the statistics are displayed (if activated) after replaying the number of commands specified by this property. -
[bool MimicApplicationName = false]
If set to true, tries to replay the events to the target database using the same application name captured by the listener. When set to false,SqlWorkloadwill be used instead. -
[Dictionary<string,string> DatabaseMap]
When populated, it can redirect the commands from the original database to a database of your choice. Add to the dictionary one entry for each database to redirect.
This consumer type writes all the events received from the listener to a workload file, that can be used as a source for a FileWorkloadListener at a later moment.
The workload file is a SqLite database that contains a table with all the events captured from the listener. Additional tables are available for storing the performance counters and the wait stats captured by the listener.
Available properties:
-
string OutputFile
Path to the output file. If the file exists, it will be reused and the new events appended to it. -
[string CACHE_SIZE = 1000]
Size of the in-memory cache that holds the events temporarily before flushing them to the output file.