[Paper] [Project Page] [Sample Data]
To set up the conda environment for CAGE, we provide a minimal package requirement list for training & inference (See CAGE.yaml), as well as a full environment export (CAGE_full.yaml) for reproducibility reference.
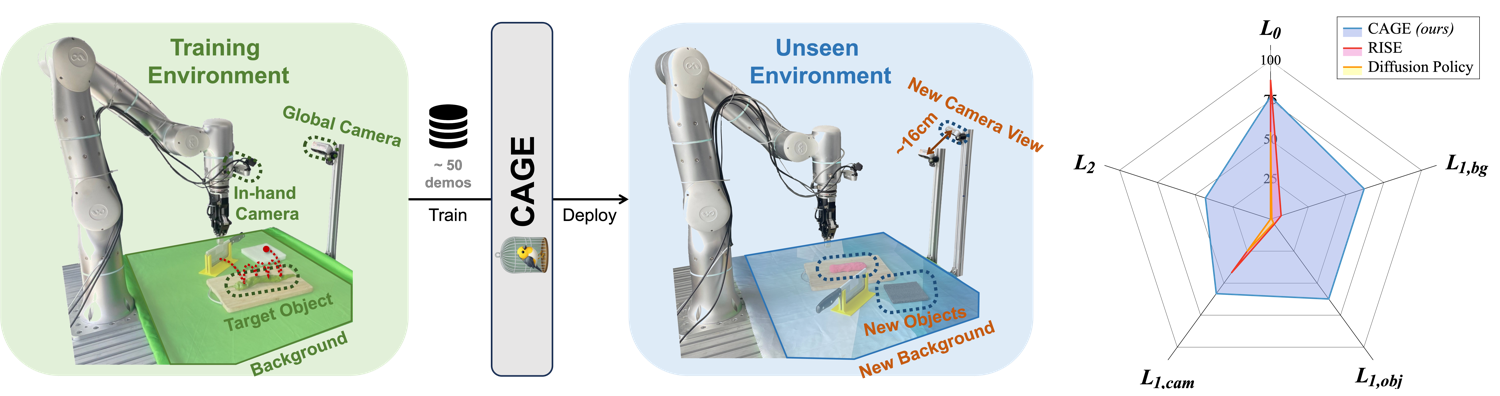
conda env create -f CAGE.yamlWe apply the same data collection process as described in RH20T: The robotic arm is equipped with an in-hand camera and faces directly to a fixed camera. A haptic device is then used to collect expert demonstrations. Since CAGE utilizes only RGB images, no calibration is required.
We provide the sample data for each task on Google Drive and Baidu Netdisk (code: vwxq).
We adopt accelerate and deepspeed for configurable single-GPU / multi-GPU training. The main training script is train_cage.py. Its config file is located in configs with cage prefix. (e.g. cage-rh20t.yaml is used for training CAGE on the RH20T dataset)
An example of the training command is as follows:
accelerate launch \
--num_machines=1 \
--num_processes=4 \
--gpu_ids=0,1,2,3 \
-m train_cage \
--tag [real|rh20t] \
[--test] \
[--resume PATH] \
[other parameters defined in the config file (e.g. batch_size=16 dataset.obs_horizon=2)]
To train on single GPU, you can simply set --num_processes=1 and --gpu_ids=0.
With a batch size of 16, CAGE takes around 60 GB of VRAM on each GPU. To reduce the memory usage, you can use a smaller batch size combined with gradient accumulation (e.g., batch_size=8 with gradient_accumulation_steps=2) to fit the model on your GPUs.
Checkpoints are automatically saved each checkpoint_steps and after each epoch. Once the training is done, a final_ckpt will be saved for evaluation.
If you want to evaluate the policy from an intermediate checkpoint, you should first extract model.bin from DeepSpeed states using the provided script under each checkpoint directory:
cd [path_to_checkpoint] && python zero_to_fp32.py . model.binSince model.bin is directly exported from the training states, frozen parameters of DINOv2 is also embedded. To further reduce the file size, you can use the following command to store only trainable parameters:
python merge_weight.py --unmerge --ckpt [path_to_model.bin] --config [path_to_config.yaml]Running inference on CAGE is as simple as:
import os
from agent import CAGEAgent
from omegaconf import OmegaConf
conf = OmegaConf.load(os.path.join('configs', 'eval-cage.yaml'))
# create the inference agent from config file
agent = CAGEAgent(conf)
# each list is a sequence of observations in order of time
# (the last element is the most recent one)
# 'proprio' is a list of end-effector pose of the robot
# If the model is trained without proprioception,
# the current pose of the robot is still required
# for relative action calculation. (length should be 1)
obs_dict = {
'global_cam': [...], # [PIL.Image] * obs_horizon
'wrist_cam': [...], # [PIL.Image] * obs_horizon
'proprio': [...], # [np.ndarray] * obs_horizon or 1
}
# get next 8 actions based on current observations
xyz, rot, w = agent(obs_dict, act_horizon=8)For advanced usage, please refer to agent/cage.py, agent/generic.py and eval.py for more details.
We provide a sample script eval.py for evaluation on our platform (Flexiv Rizon 4 robotic arm + Dahuan AG-95 gripper) with the following command:
python eval.py \
--config [path_to_config_file] \
--ckpt [path_to_model_ckpt] \
--ctrl_freq 10 \
--pred_interval 4 \
--t_ensemble
To evaluate on the platform with the same setup as ours, extra python libraries are required:
pip install pyserial modbus_tk pyrealsense2And you also need to install the Flexiv RDK for robot control. Specifically, download FlexivRDK v0.9 and copy lib_py/flexivrdk.cpython-310-[arch].so to hardware/robot directory.
For other platforms, you should modify the codes in hardware/ and the evaluation script to adapt to your own configuration.
As the level of distribution shift increases, the performance of selected 2D/3D baselines drops significantly, while CAGE maintains a stable performance, even when evaluating in a completely new environment.
In similar environments, CAGE offers an average of 42% increase in task completion rate. While all baselines fail to execute the task in unseen environments, CAGE manages to obtain a 43% completion rate and a 51% success rate in average.
L0 Evaluation Results.

L1 Evaluation Results.
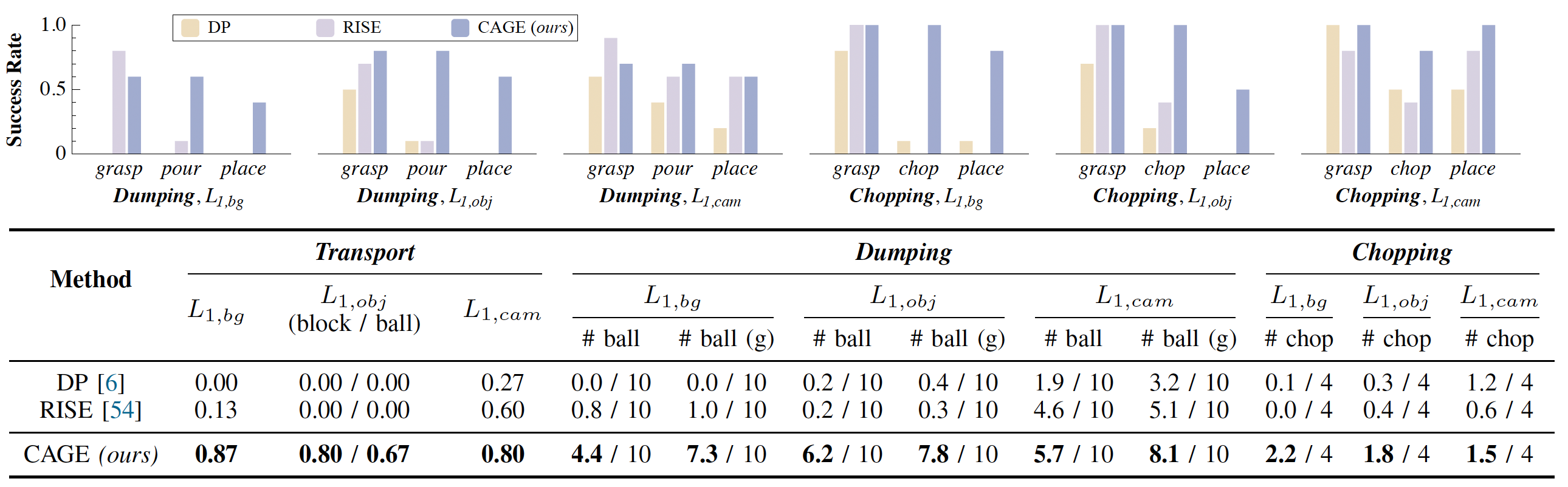
L2 Evaluation Results.

- Our diffusion module is adapted from Diffusion Policy. This part is under MIT License.
- Our real-world evaluation code is adapted from RISE. This part is under CC-BY-NC-SA 4.0 License.
@article{
xia2024cage,
title = {CAGE: Causal Attention Enables Data-Efficient Generalizable Robotic Manipulation},
author = {Xia, Shangning and Fang, Hongjie and Lu, Cewu and Fang, Hao-Shu},
journal = {arXiv preprint arXiv:2410.14974},
year = {2024}
}CAGE (including data and codebase) by Shangning Xia, Hongjie Fang, Cewu Lu, Hao-Shu Fang is licensed under CC BY-NC-SA 4.0