By: Hila Chefer (Tel-Aviv University and Google) and Sayak Paul (Hugging Face) (with Ron Mokady as a guest speaker)
Holds code for our CVPR'23 tutorial: All Things ViTs: Understanding and Interpreting Attention in Vision. We leverage 🤗 transformers, 🧨 diffusers, timm, and PyTorch for the code samples.
- Website
- Virtual website on the CVPR portal
- Interactive demos (no setup required)
- Slides (Ron's slides are here)
- Video recording
We provide all the code samples as Colab Notebooks so that no setup is needed locally to execute them.
We divide our tutorial into the following logical sections:
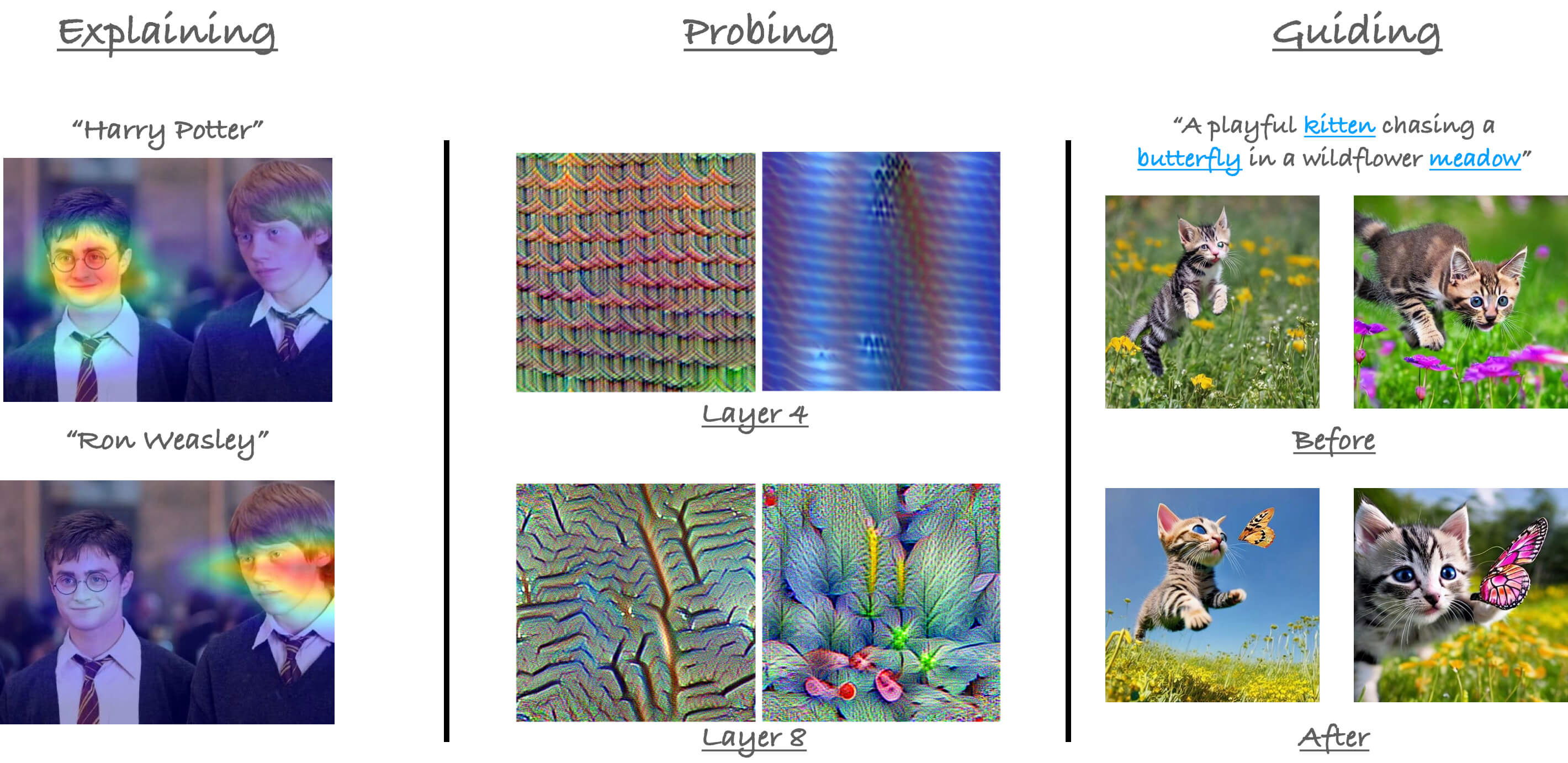
explainability: has the notebooks that show how to generate explanations from attention-based models (such as Vision Transformers) on the basis of their predictions.CLIP_explainability.ipynbComparative_Transformer_explainability.ipynbTransformer_explainability.ipynb
probing: has notebooks the probe into the representations learned by the attention-based models (such as Vision Transformers).dino_attention_maps.ipynbmean_attention_distance.ipynb
Below we provide links to all the Colab Notebooks:
| Section | Notebook Name | Colab Notebook |
|---|---|---|
explainability |
CLIP_explainability.ipynb |
|
Comparative_Transformer_explainability.ipynb |
|
|
Transformer_explainability.ipynb |
|
|
probing |
dino_attention_maps.ipynb |
|
mean_attention_distance.ipynb |
|
The following notebooks were taken from their original repositories with the authors being aware of this: