本文基于 hashicorp/raft
v1.3.11版本进行源码分析
本文按照下面流程分析 raft 日志复制的实现原理.
- 调用上层 Apply 接口写数据.
- leader 向 follower 同步日志.
- follower 接收日志.
- leader 确认提交日志, 并且应用到状态机.
- follower 确认提交日志.
golang hashicorp raft 原理系列
- 源码分析 hashicorp raft election 选举的设计实现原理
- 源码分析 hashicorp raft replication 日志复制的实现原理
- 源码分析 hashicorp raft 持久化存储的实现原理
- 源码分析 hashicorp raft snapshot 快照的实现原理
Apply 是 hashicorp raft 提供的给上层写数据的入口, 当使用 hashicorp/raft 构建分布式系统时, 作为 leader 节点承担了写操作, 这里写就是调用 api 里的 Apply 方法.
Apply 入参的 cmd 为业务需要写的数据, 只支持 []byte, 如是 struct 对象则需要序列化为 []byte, timeout 为写超时, 这里的写超时只是把 logFuture 插入 applyCh 的超时时间, 而不是推到 follower 的时间.
Apply 其内部流程是先实例化一个定时器, 然后把业务数据构建成 logFuture 对象, 然后推到 applyCh 队列. applyCh 缓冲队列的大小跟 raft 的并发吞吐有关系的, hashicorp raft 里 applyCh 默认长度为 64.
代码位置: github.com/hashicorp/raft/api.go
// 写日志
func (r *Raft) Apply(cmd []byte, timeout time.Duration) ApplyFuture {
return r.ApplyLog(Log{Data: cmd}, timeout)
}
// 写日志
func (r *Raft) ApplyLog(log Log, timeout time.Duration) ApplyFuture {
var timer <-chan time.Time
// 如果有配置超时时间, 则实例化定时器.
if timeout > 0 {
timer = time.After(timeout)
}
// 实例化 logFuture 对象, 暂不配置 term 和 index.
logFuture := &logFuture{
log: Log{
Type: LogCommand, // 命令类型
Data: log.Data, // 业务数据
Extensions: log.Extensions, // 扩展, 这里为空
},
}
// 实例化 errCh, 业务层可通过 Error() 监听其输出.
logFuture.init()
select {
case <-timer:
// 触发超时, 等 timer 为 nil 时, select 忽略该 case.
return errorFuture{ErrEnqueueTimeout}
case <-r.shutdownCh:
// 关闭退出
return errorFuture{ErrRaftShutdown}
case r.applyCh <- logFuture:
// 把日志塞入 applyCh 管道中.
return logFuture
}
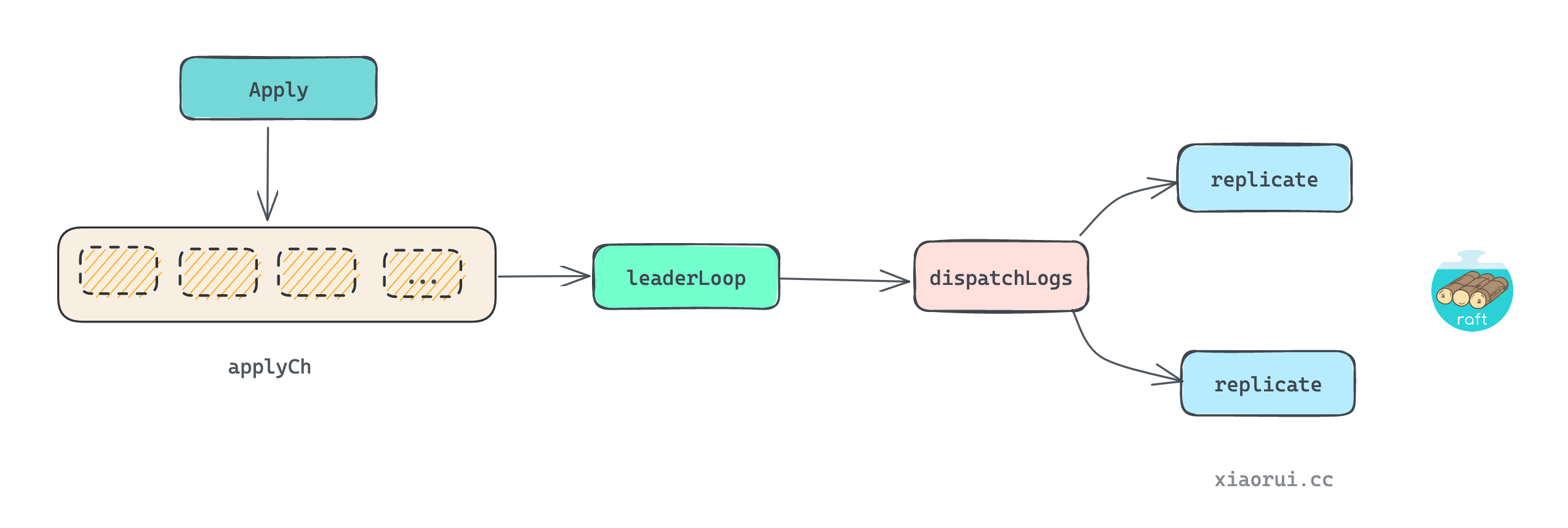
}leaderLoop 会监听 applyCh 管道, 该管道的数据是由 hashicorp/raft api 层的 Apply 方法推入, leaderLoop 在收到 apply 日志后, 调用 dispatchLogs 来给 replication 调度通知日志.
代码位置: github.com/hashicorp/raft/raft.go
func (r *Raft) leaderLoop() {
for r.getState() == Leader {
select {
case ...:
case newLog := <-r.applyCh:
// ...
// 日志的组提交, 所谓的组提交就是日志按批次提交, 这是 raft 工程上优化.
ready := []*logFuture{newLog}
GROUP_COMMIT_LOOP:
// 尝试凑齐 MaxAppendEntries 数量的日志
for i := 0; i < r.config().MaxAppendEntries; i++ {
select {
case newLog := <-r.applyCh:
ready = append(ready, newLog)
default:
// applyCh 为空, 中断循环.
break GROUP_COMMIT_LOOP
}
}
// ...
// 派发日志, 批量发.
r.dispatchLogs(ready)
case ...:
}
}
}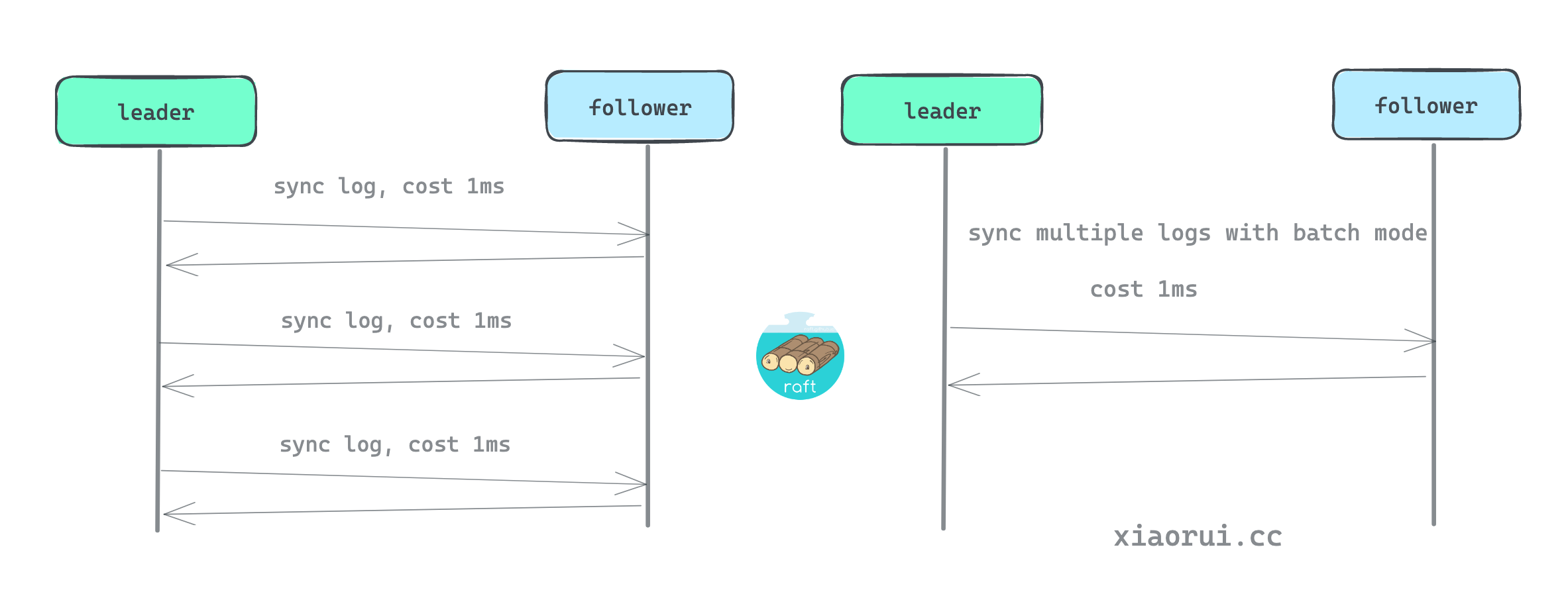
开启批量是很有必要的, 大大提高了 raft 日志数据同步的效率. 首先 hashicorp raft 当前只支持单个 leader, 又不支持乱序并发算法, 所有的写操作日志都是串行方式来同步, 所谓串行同步就是顺序同步. 如果每次发送单条日志, 那么网络的时延相当的可观, 比如两个主机之间的日志同步的 RTT 为 1ms, 多条日志就是 1ms * N. 但由于内网环境下网络带宽吞吐很高, 所以完全可以单次一个批次的日志, 节省过多的网络 RTT 开销.
dispatchLogs 用来记录本地日志以及派发日志给所有的 follower.
- 把日志先写到本地里.
- commitment.match 来计算各个 server 的 matchIndex, 计算出 commit 提交索引.
- 记录当前的日志的信息.
- 把请求的日志通知给所有的 replication 同步副本.
func (r *Raft) dispatchLogs(applyLogs []*logFuture) {
// 获取当前最新的 term 任期和日志索引.
term := r.getCurrentTerm()
lastIndex := r.getLastIndex()
n := len(applyLogs)
logs := make([]*Log, n)
for idx, applyLog := range applyLogs {
applyLog.dispatch = now
lastIndex++
// raft log index 是全局单调递增的, 所以对遍历的日志加一.
applyLog.log.Index = lastIndex
applyLog.log.Term = term
applyLog.log.AppendedAt = now
logs[idx] = &applyLog.log
r.leaderState.inflight.PushBack(applyLog)
}
// 把日志写到本地存储里 storage, 先写到本地, 再发给其他 follower.
if err := r.logs.StoreLogs(logs); err != nil {
r.logger.Error("failed to commit logs", "error", err)
for _, applyLog := range applyLogs {
// 遍历返回错误
applyLog.respond(err)
}
// 如果写本地日志失败, 则直接切换状态为 follower.
r.setState(Follower)
return
}
// 计算 matchIndex
r.leaderState.commitment.match(r.localID, lastIndex)
// 记录当前的日志的信息.
r.setLastLog(lastIndex, term)
// 把请求的日志通知给所有的 replication 同步副本.
for _, f := range r.leaderState.replState {
asyncNotifyCh(f.triggerCh)
}
}
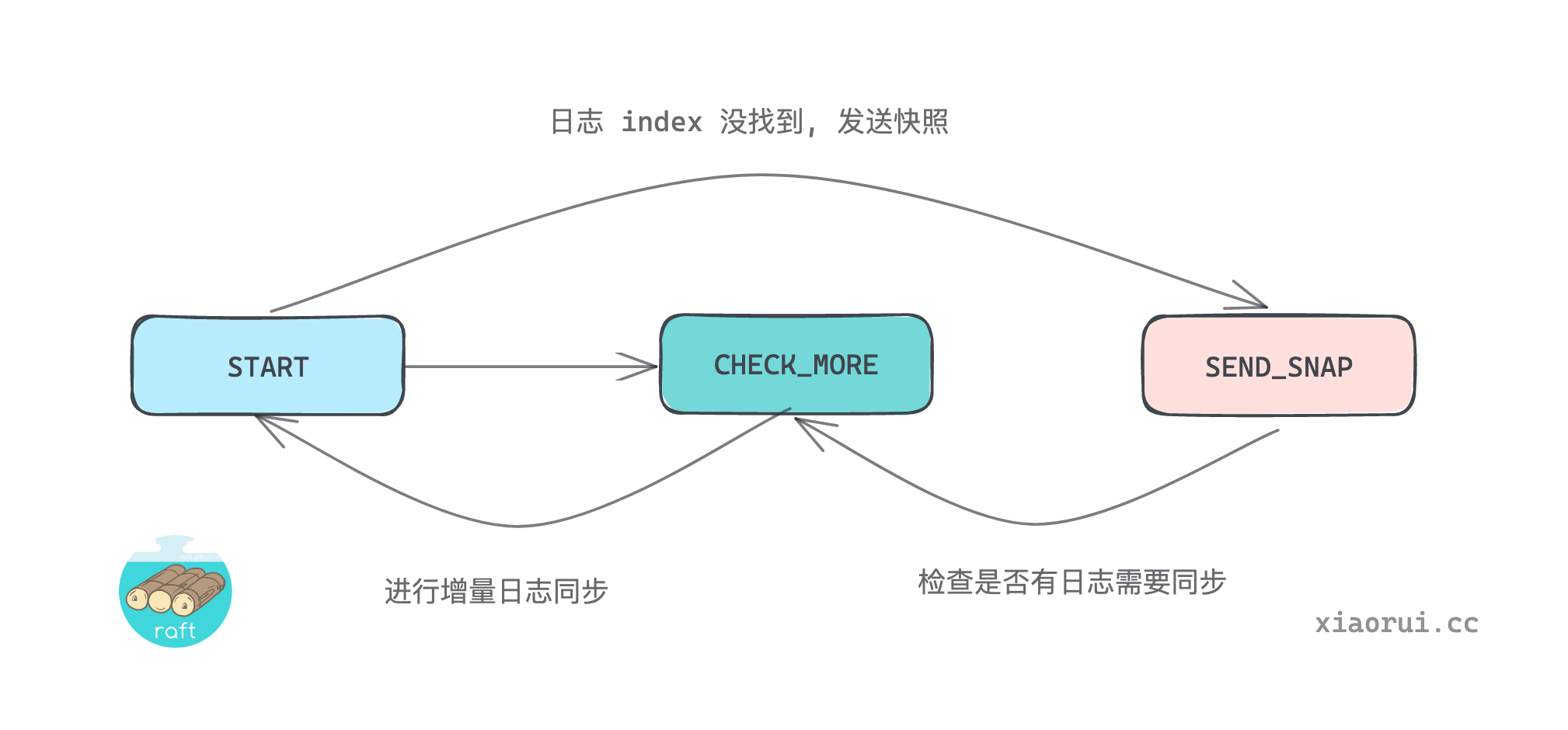
当节点确认成为 leader 时, 会为每个 follower 启动 replication 对象, 并启动两个协程 replicate 和 heartbeat.
replicate 其内部监听 triggerCh 有无发生通知时, 当有日志需要同步给 follower 调用 replicateTo. 另外 replicate 每次还会创建一个随机 50ms - 100ms 的定时器, 当定时器触发时, 也会尝试同步日志, 主要用来同步 commitIndex 提交索引.
func (r *Raft) replicate(s *followerReplication) {
// Start an async heartbeating routing
stopHeartbeat := make(chan struct{})
defer close(stopHeartbeat)
r.goFunc(func() { r.heartbeat(s, stopHeartbeat) })
RPC:
shouldStop := false
for !shouldStop {
select {
case maxIndex := <-s.stopCh:
// 当收到退出时, 尝试把未同步的日志推到 follower 端.
if maxIndex > 0 {
r.replicateTo(s, maxIndex)
}
return
// ...
case deferErr := <-s.triggerDeferErrorCh:
// ...
case <-s.triggerCh:
// 获取当前最新日志 index
lastLogIdx, _ := r.getLastLog()
// 调用 replicateTo 同步日志
shouldStop = r.replicateTo(s, lastLogIdx)
case <-randomTimeout(r.config().CommitTimeout):
// See https://github.com/hashicorp/raft/issues/282.
// 创建一个随机 50ms - 100ms 的定时器.
// 当定时器触发超时, 则尝试进行一波数据副本同步.
lastLogIdx, _ := r.getLastLog()
shouldStop = r.replicateTo(s, lastLogIdx)
}
// 每次在 replicateTo 执行成功后会开启 pipeline.
if !shouldStop && s.allowPipeline {
goto PIPELINE
}
}
return
PIPELINE:
// 每次关闭
s.allowPipeline = false
if err := r.pipelineReplicate(s); err != nil {
if err != ErrPipelineReplicationNotSupported {
s.peerLock.RLock()
peer := s.peer
s.peerLock.RUnlock()
}
}
// 执行完毕后再跳到 RPC
goto RPC
}
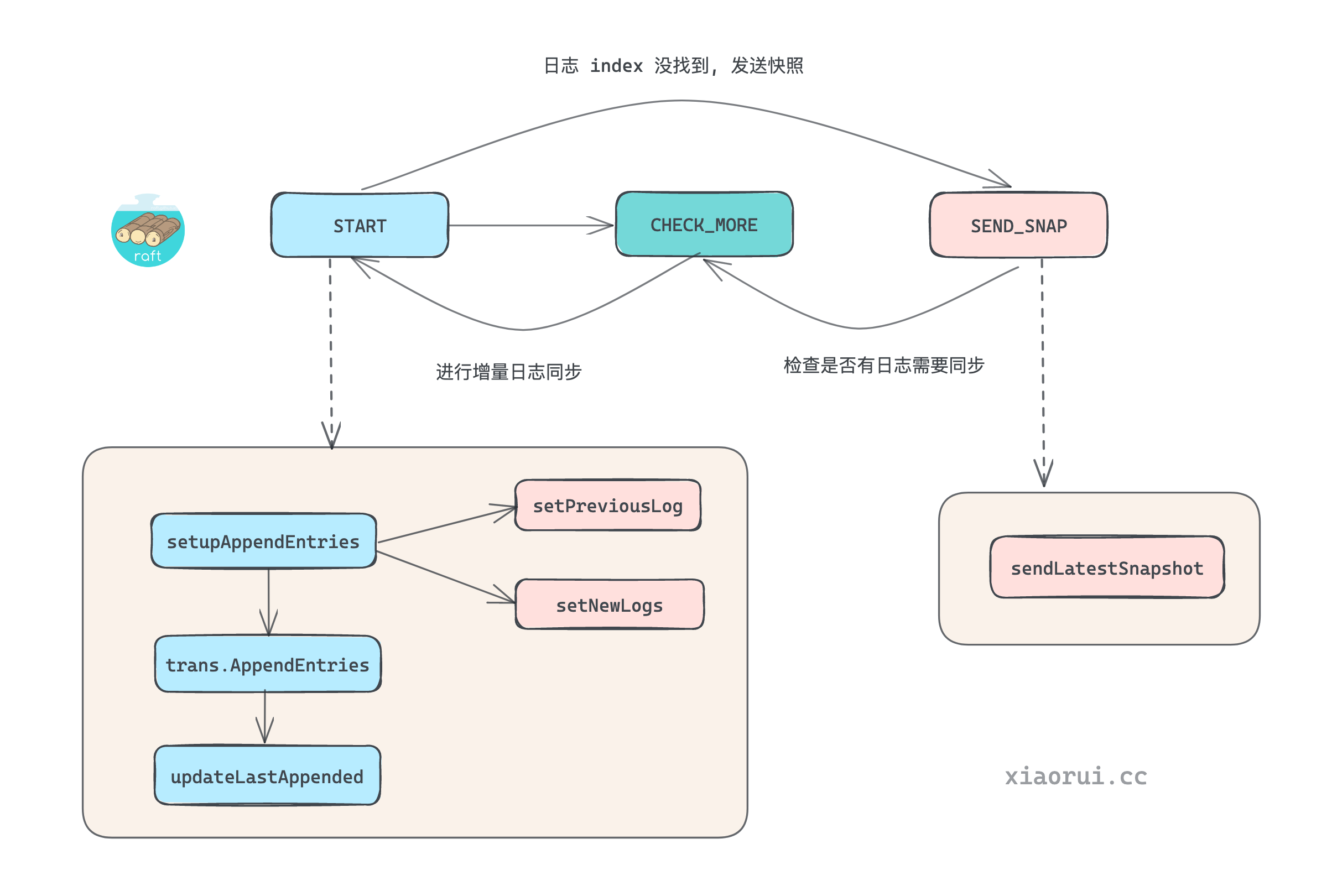
replicateTo 用来真正的把日志数据同步给 follower.
- 首先调用
setupAppendEntries装载请求同步的日志, 这里需要装载上一条日志及增量日志. - 然后使用 transport 给 follower 发送请求, 之后更新状态.
- 如果装载日志时, 发现 log index 不存在, 则需要发送快照文件.
- 在发完快照文件后, 需要判断是否继续发送快照点之后的增量日志, 如含有增量则 goto 切到 1.
func (r *Raft) replicateTo(s *followerReplication, lastIndex uint64) (shouldStop bool) {
// Create the base request
var req AppendEntriesRequest
var resp AppendEntriesResponse
var peer Server
START:
// 防止过多的 retry, 每次失败需要等待更多的退避时间.
if s.failures > 0 {
select {
case <-time.After(backoff(failureWait, s.failures, maxFailureScale)):
case <-r.shutdownCh:
}
}
s.peerLock.RLock()
peer = s.peer
s.peerLock.RUnlock()
// 把需要同步给 follower 的日志装载到 req 对象中.
if err := r.setupAppendEntries(s, &req, atomic.LoadUint64(&s.nextIndex), lastIndex); err == ErrLogNotFound {
// 如果 log index 已经不存在, 则发送基础数据的快照.
goto SEND_SNAP
} else if err != nil {
return
}
// 发送请求
start = time.Now()
if err := r.trans.AppendEntries(peer.ID, peer.Address, &req, &resp); err != nil {
// 发生失败, 退出
s.failures++
return
}
// 如果发现更新的 term 任期, 则退出.
if resp.Term > req.Term {
r.handleStaleTerm(s)
return true
}
// 更新跟 follower 的交互时间
s.setLastContact()
// 如果成功同步日志
if resp.Success {
// 更新 replication 状态
updateLastAppended(s, &req)
// 清空
s.failures = 0
s.allowPipeline = true
} else {
// 失败则退回先前的 nextIndex 位置.
atomic.StoreUint64(&s.nextIndex, max(min(s.nextIndex-1, resp.LastLog+1), 1))
// ...
}
CHECK_MORE:
select {
case <-s.stopCh:
return true
default:
}
// 发送完底量快照后, 检查是否有增量日志, 有则跳到 START.
if atomic.LoadUint64(&s.nextIndex) <= lastIndex {
goto START
}
return
// SEND_SNAP is used when we fail to get a log, usually because the follower
// is too far behind, and we must ship a snapshot down instead
SEND_SNAP:
// 发送最近的快照文件
if stop, err := r.sendLatestSnapshot(s); stop {
return true
} else if err != nil {
return
}
// 跳到 check_more, 检查是否有增量日志更新.
goto CHECK_MORE
}setupAppendEntries 方法会把日志数据和其他元数据装载到 AppendEntriesRequest 对象里.
下面是 AppendEntriesRequest 的数据结构.
type AppendEntriesRequest struct {
// rpc proto 和 leader 信息.
RPCHeader
// 当前 leader 的日志索引值.
Term uint64
// 上一条 log 值的 index 和 term, follower 会利用这两个值校验缺失和冲突.
PrevLogEntry uint64
PrevLogTerm uint64
// 同步给 follower 的增量的日志
Entries []*Log
// 已经在 leader 提交的日志索引值
LeaderCommitIndex uint64
}setupAppendEntries 用来构建 AppendEntriesRequest 对象, 这里不仅当前节点的最新 log 信息, 还有 follower nextIndex 的上一条 log 日志数据, 还有新增的 log 日志数据.
// setupAppendEntries is used to setup an append entries request.
func (r *Raft) setupAppendEntries(s *followerReplication, req *AppendEntriesRequest, nextIndex, lastIndex uint64) error {
// 赋值 rpc header
req.RPCHeader = r.getRPCHeader()
// 赋值当前的 term 任期号
req.Term = s.currentTerm
// 赋值 leader 信息
req.Leader = r.trans.EncodePeer(r.localID, r.localAddr)
// 赋值 commit index 提交索引值
req.LeaderCommitIndex = r.getCommitIndex()
// 获取 nextIndex 之前的 log term 和 index.
if err := r.setPreviousLog(req, nextIndex); err != nil {
// 错误则跳出, 如果 ErrLogNotFound 错误, 走发送快照逻辑
return err
}
// 获取 nextIndex 到 lastIndex 之间的增量数据, 最大超过 MaxAppendEntries 个.
if err := r.setNewLogs(req, nextIndex, lastIndex); err != nil {
return err
}
return nil
}setPreviousLog 用来获取 follower 的 nextIndex 的上一条数据, 如果在快照临界点, 则使用快照记录的 index 和 term, 否则其他情况调用 LogStore 存储的 GetLog 获取上一条日志.
需要注意一下, 如果上一条数据的 index 在 logStore 不存在, 那么就需要返回错误, 后面走发送快照逻辑了.
func (r *Raft) setPreviousLog(req *AppendEntriesRequest, nextIndex uint64) error {
// 获取快照文件中最大日志的 index 和 term.
lastSnapIdx, lastSnapTerm := r.getLastSnapshot()
// 如果 nextIndex 等于 1, 那么 prev 必然为 0.
if nextIndex == 1 {
req.PrevLogEntry = 0
req.PrevLogTerm = 0
} else if (nextIndex - 1) == lastSnapIdx {
// 如果 -1 等于 快照数据的最大 index, 则 prev 使用快照的值.
req.PrevLogEntry = lastSnapIdx
req.PrevLogTerm = lastSnapTerm
} else {
var l Log
// 从 LogStore 存储获取上一条日志数据.
// 关于 raft LogStore 的具体实现, 后面专门讲解其实现原理.
if err := r.logs.GetLog(nextIndex-1, &l); err != nil {
// 如果日志不存在, 说明是在 snapshot 快照文件中.
return err
}
// 进行赋值.
req.PrevLogEntry = l.Index
req.PrevLogTerm = l.Term
}
return nil
}setNewLogs 用来获取 nextIndex 到 lastIndex 之间的增量数据, 为避免一次传递太多的数据, 这里限定单次不能超过 MaxAppendEntries 条日志.
// setNewLogs is used to setup the logs which should be appended for a request.
func (r *Raft) setNewLogs(req *AppendEntriesRequest, nextIndex, lastIndex uint64) error {
maxAppendEntries := r.config().MaxAppendEntries
req.Entries = make([]*Log, 0, maxAppendEntries)
// 单词批量发送不能超过 maxAppendEntries 条的日志.
// 如果增量的数据不到 maxAppendEntries, 那么就发送 nextIndex > lastIndex 之间的数据.
maxIndex := min(nextIndex+uint64(maxAppendEntries)-1, lastIndex)
for i := nextIndex; i <= maxIndex; i++ {
oldLog := new(Log)
if err := r.logs.GetLog(i, oldLog); err != nil {
return err
}
req.Entries = append(req.Entries, oldLog)
}
return nil
}updateLastAppended 用来更新记录 follower 的 nextIndex 值, 另外还会调用 commitment.match 改变 commit 记录, 并通知让状态机应用.
每个 follower 在同步完数据后, 都需要调用一次 updateLastAppended, 不仅更新 follower nextIndex, 更重要的是更新 commitIndex 提交索引值, commitment.match 内部检测到 commit 发生变动时, 向 commitCh 提交通知, 最后由 leaderLoop 检测到 commit 通知, 并调用状态机 fsm 应用.
在本地提交后, 当下次 replicate 同步数据时, 自然会携带更新后的 commitIndex, 在 follower 收到且经过判断对比后, 把数据更新自身的状态机里.
func updateLastAppended(s *followerReplication, req *AppendEntriesRequest) {
// Mark any inflight logs as committed
if logs := req.Entries; len(logs) > 0 {
last := logs[len(logs)-1]
atomic.StoreUint64(&s.nextIndex, last.Index+1)
s.commitment.match(s.peer.ID, last.Index)
}
// Notify still leader
s.notifyAll(true)
}🔥 重点:
在 leader 里找到绝大数 follower 都满足的 Index 作为 commitIndex 进行提交, 先本地提交, 随着下次 replicate 同步日志时, 通知其他 follower 也提交日志到本地.
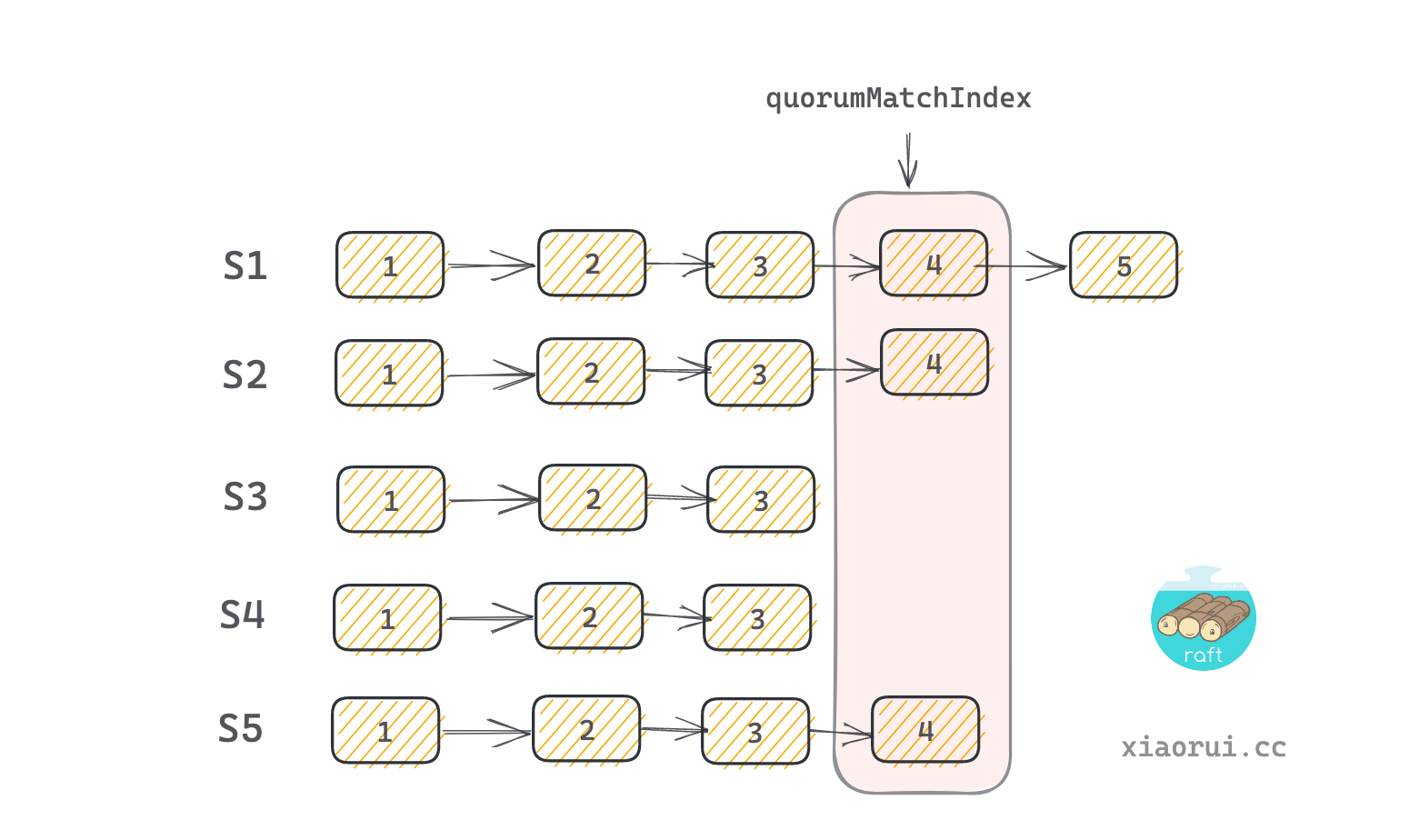
match 通过计算各个 server 的 matchIndex 计算出 commitIndex. commitIndex 可以理解为法定的提交索引值. 对所有 server 的 matchIndex 进行排序, 然后使用 matched[(len(matched)-1)/2] 值作为 commitIndex. 这样比 commitIndex 小的 log index 会被推到 commitCh 管道里. 后面由 leaderLoop 进行消费, 然后调用 fsm 状态机进行应用日志.
func (c *commitment) match(server ServerID, matchIndex uint64) {
c.Lock()
defer c.Unlock()
// 如果传入的 server 已投票, 另外 index 大于上一个记录的 index, 则更新 matchIndex.
if prev, hasVote := c.matchIndexes[server]; hasVote && matchIndex > prev {
c.matchIndexes[server] = matchIndex
// 重新计算
c.recalculate()
}
}
func (c *commitment) recalculate() {
// 需要重计算, 但还未初始化 matchIndex 数据时, 直接退出.
if len(c.matchIndexes) == 0 {
return
}
// 构建一个容器存放各个 server 的 index.
matched := make([]uint64, 0, len(c.matchIndexes))
for _, idx := range c.matchIndexes {
matched = append(matched, idx)
}
// 对整数切片进行排序, 从小到大正序排序
sort.Sort(uint64Slice(matched))
// 找到 quorum match index 点. 比如 [1 2 3 4 5], 那么 2 为 quorumMatchIndex 法定判断点.
quorumMatchIndex := matched[(len(matched)-1)/2]
// 如果法定判断点大于当前的提交点, 并且法定点大于 first index, 则更新 commitIndex 和通知 commitCh.
if quorumMatchIndex > c.commitIndex && quorumMatchIndex >= c.startIndex {
c.commitIndex = quorumMatchIndex
// 给 commitCh 发送通知, 该 chan 由 leaderLoop 来监听处理.
asyncNotifyCh(c.commitCh)
}
}hashicorp transport 层是使用 msgpack rpc 实现的, 其实现原理没什么可说的.
func (n *NetworkTransport) AppendEntries(id ServerID, target ServerAddress, args *AppendEntriesRequest, resp *AppendEntriesResponse) error {
return n.genericRPC(id, target, rpcAppendEntries, args, resp)
}
// genericRPC 为通用的 rpc 请求方法
func (n *NetworkTransport) genericRPC(id ServerID, target ServerAddress, rpcType uint8, args interface{}, resp interface{}) error {
// 获取连接对象
conn, err := n.getConnFromAddressProvider(id, target)
if err != nil {
return err
}
// 配置超时
if n.timeout > 0 {
conn.conn.SetDeadline(time.Now().Add(n.timeout))
}
// 封装请求报文, 发送请求
if err = sendRPC(conn, rpcType, args); err != nil {
return err
}
// decode 数据到 resp 结构对象中
canReturn, err := decodeResponse(conn, resp)
if canReturn {
n.returnConn(conn)
}
return err
}msgpack rpc 的协议报文格式如下.
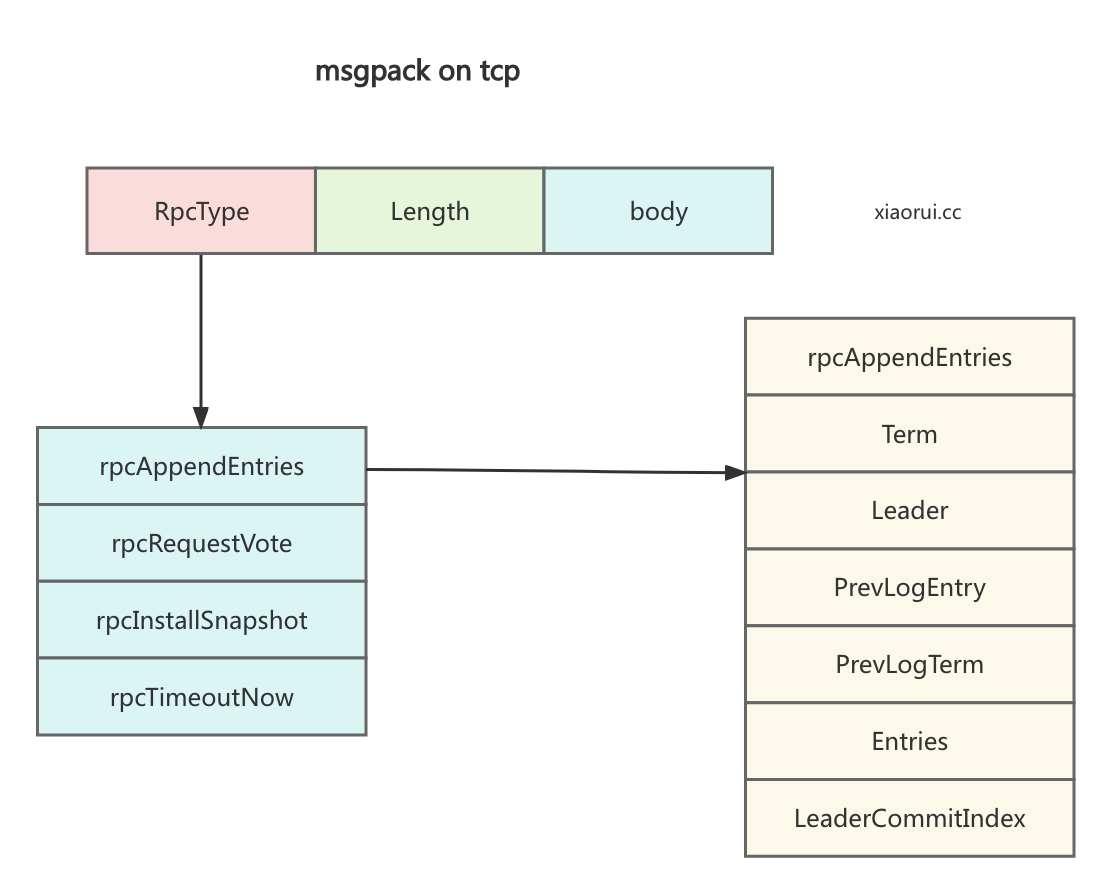
appendEntries() 是用来处理来自 leader 发起的 appendEntries 请求. 其内部首先判断请求的日志是否可以用, 能用则保存日志到本地, 然后调用 processLogs 来通知 fsm 状态机应用日志.
如果请求的上条日志跟本实例最新日志不一致, 则返回失败. 而 leader 会根据 follower 返回结果, 获取 follower 最新的 log term 及 index, 然后再同步给 follower 缺失的日志. 另外当 follower 发现冲突日志时, 也会以 leader 的日志为准来覆盖修复产生冲突的日志.
简单说 appendEntries() 同步日志是 leader 和 follower 不断调整位置再同步数据的过程.
func (r *Raft) appendEntries(rpc RPC, a *AppendEntriesRequest) {
// 实例化返回结构
resp := &AppendEntriesResponse{
RPCHeader: r.getRPCHeader(),
Term: r.getCurrentTerm(),
LastLog: r.getLastIndex(),
Success: false, // 默认为失败, 只有最后才赋值为 true.
NoRetryBackoff: false,
}
var rpcErr error
defer func() {
rpc.Respond(resp, rpcErr)
}()
// 如果请求的 term 比当前的小, 则直接忽略.
if a.Term < r.getCurrentTerm() {
return
}
// 如果请求的 term 比当前 term 大或者当前不是 follower 状态, 则切到 follower 角色. 并且更新当前 term.
if a.Term > r.getCurrentTerm() || (r.getState() != Follower && !r.candidateFromLeadershipTransfer) {
r.setState(Follower)
r.setCurrentTerm(a.Term)
resp.Term = a.Term
}
// 在当前节点保存 leader 信息.
if len(a.Addr) > 0 {
r.setLeader(r.trans.DecodePeer(a.Addr), ServerID(a.ID))
} else {
r.setLeader(r.trans.DecodePeer(a.Leader), ServerID(a.ID))
}
// 检查对比请求的上一条 prev 日志跟本地日志的 index 和 term 是否一样,
// 不一致, 则说明缺失了多条日志.
if a.PrevLogEntry > 0 {
lastIdx, lastTerm := r.getLastEntry()
var prevLogTerm uint64
if a.PrevLogEntry == lastIdx {
prevLogTerm = lastTerm
} else {
var prevLog Log
if err := r.logs.GetLog(a.PrevLogEntry, &prevLog); err != nil {
return
}
prevLogTerm = prevLog.Term
}
// 如果请求体中上次 term 跟当前 term 不一致, 则直接写失败.
if a.PrevLogTerm != prevLogTerm {
return
}
}
// 把日志持久化到本地
if len(a.Entries) > 0 {
// ...
// 清理冲突的日志
// 保存日志到本地
}
// 如果有新日志, 则把日志持久化到本地
if len(a.Entries) > 0 {
start := time.Now()
// 删除发生冲突的日志
// 获取当前最后日志的 index
lastLogIdx, _ := r.getLastLog()
var newEntries []*Log
// 遍历 req.Entries 中的日志
for i, entry := range a.Entries {
// 如果发现 index 比最后一条日志 index 大, 则重新赋值并中断.
// 正常 case 下, 新日志必然要比最后一条日志大.
if entry.Index > lastLogIdx {
newEntries = a.Entries[i:]
break
}
// 如果日志 index 在 LogStore 不存在, 则退出.
var storeEntry Log
if err := r.logs.GetLog(entry.Index, &storeEntry); err != nil {
r.logger.Warn("failed to get log entry",
"index", entry.Index,
"error", err)
return
}
// 如果遍历到的 entry term 跟 LogStore 中不一致, 则尝试进行清理冲突.
if entry.Term != storeEntry.Term {
// 调用 LogStore 的范围删除 DeleteRange 方法进行范围删除.
if err := r.logs.DeleteRange(entry.Index, lastLogIdx); err != nil {
return
}
if entry.Index <= r.configurations.latestIndex {
r.setLatestConfiguration(r.configurations.committed, r.configurations.committedIndex)
}
newEntries = a.Entries[i:]
break
}
}
// 上面是删除冲突的日志, 下面是保存新增的日志.
if n := len(newEntries); n > 0 {
// 保存日志
if err := r.logs.StoreLogs(newEntries); err != nil {
r.logger.Error("failed to append to logs", "error", err)
return
}
// 更新日志配置
for _, newEntry := range newEntries {
if err := r.processConfigurationLogEntry(newEntry); err != nil {
rpcErr = err
return
}
}
// 更新 LastLog
last := newEntries[n-1]
r.setLastLog(last.Index, last.Term)
}
}
// 更新并提交日志到 FSM
if a.LeaderCommitIndex > 0 && a.LeaderCommitIndex > r.getCommitIndex() {
// 求最小
idx := min(a.LeaderCommitIndex, r.getLastIndex())
r.setCommitIndex(idx)
// 把 commitIndex 之前的日志提交到状态机 FSM 进行应用日志.
r.processLogs(idx, nil)
}
// 日志同步成功
resp.Success = true
r.setLastContact()
return
}不管是 Leader 和 Follower 都会调用状态机 FSM 来应用日志. 其流程是先调用 processLogs 来打包批量日志, 然后将日志推到 fsmMutateCh 管道里, 最后由 runFSM 协程来监听该管道, 并把日志应用到状态机里面.
func (r *Raft) processLogs(index uint64, futures map[uint64]*logFuture) {
lastApplied := r.getLastApplied()
if index <= lastApplied {
return
}
// 匿名函数, 把 batch 日志推到队列 fsmMutateCh 中.
applyBatch := func(batch []*commitTuple) {
select {
case r.fsmMutateCh <- batch:
case <-r.shutdownCh:
// ...
}
}
// 打包的单个批次最多 maxAppendEntries 条日志, 这根 replicate 一样.
maxAppendEntries := r.config().MaxAppendEntries
batch := make([]*commitTuple, 0, maxAppendEntries)
for idx := lastApplied + 1; idx <= index; idx++ {
var preparedLog *commitTuple
future, futureOk := futures[idx]
if futureOk {
preparedLog = r.prepareLog(&future.log, future)
} else {
l := new(Log)
if err := r.logs.GetLog(idx, l); err != nil {
r.logger.Error("failed to get log", "index", idx, "error", err)
panic(err)
}
preparedLog = r.prepareLog(l, nil)
}
switch {
case preparedLog != nil:
// 把 preparedLog 推到 batch 切片里.
batch = append(batch, preparedLog)
// 如果满足了 maxAppendEntries 单条最大限制, 直接调用 applyBatch.
if len(batch) >= maxAppendEntries {
applyBatch(batch)
// 新建一个新的 batch 对象, 这里不能单单把旧 batch len 重置.
batch = make([]*commitTuple, 0, maxAppendEntries)
}
case futureOk:
future.respond(nil)
}
}
// 进行收尾, 把 batch 剩余的日志也都扔到队列中.
if len(batch) != 0 {
applyBatch(batch)
}
// 更新最后的 apply log 的 index 和 term.
r.setLastApplied(index)
}runFSM 用来监听需要提交的日志, 并把日志交给状态机应用. 当 type 为 restoreFuture, 则需要恢复由 leader 发送过来的快照文件.
关于 raft snapshot 快照和日志的具体实现原理, 后面会专门出一篇来分析.
func (r *Raft) runFSM() {
var lastIndex, lastTerm uint64
batchingFSM, batchingEnabled := r.fsm.(BatchingFSM)
configStore, configStoreEnabled := r.fsm.(ConfigurationStore)
applySingle := func(req *commitTuple) {
var resp interface{}
...
switch req.log.Type {
case LogCommand:
// 调用 fsm 接口进行提交.
resp = r.fsm.Apply(req.log)
case LogConfiguration:
// 更新配置
configStore.StoreConfiguration(req.log.Index, DecodeConfiguration(req.log.Data))
}
// 更新 index 和 term
lastIndex = req.log.Index
lastTerm = req.log.Term
}
applyBatch := func(reqs []*commitTuple) {
// 如果用户实现了 BatchingFSM 接口, 则说明允许批量应用日志.
// 没实现, 则说明没开启该功能.
if !batchingEnabled {
for _, ct := range reqs {
// 只用单次接口调用状态机应用日志
applySingle(ct)
}
return
}
var lastBatchIndex, lastBatchTerm uint64
sendLogs := make([]*Log, 0, len(reqs))
for _, req := range reqs {
// 批量打包
}
var responses []interface{}
if len(sendLogs) > 0 {
start := time.Now()
// 调用 fsm 批量应用接口
responses = batchingFSM.ApplyBatch(sendLogs)
// ...
}
// 更新 index.
lastIndex = lastBatchIndex
lastTerm = lastBatchTerm
for _, req := range reqs {
// 返回通知
if req.future != nil {
req.future.response = resp
req.future.respond(nil)
}
// ...
}
}
restore := func(req *restoreFuture) {
// 根据 request id 获取已保存本地的快照文件
meta, source, err := r.snapshots.Open(req.ID)
if err != nil {
return
}
defer source.Close()
// 尝试恢复快照数据
if err := fsmRestoreAndMeasure(snapLogger, r.fsm, source, meta.Size); err != nil {
return
}
// Update the last index and term
// 更新当前最近的日志的 index 和 term.
lastIndex = meta.Index
lastTerm = meta.Term
req.respond(nil)
}
snapshot := func(req *reqSnapshotFuture) {
// ...
}
for {
select {
case ptr := <-r.fsmMutateCh:
switch req := ptr.(type) {
case []*commitTuple:
// 进行状态机提交
applyBatch(req)
case *restoreFuture:
// 恢复 snapshot 快照文件
restore(req)
default:
// 其他情况直接 panic
panic(fmt.Errorf("bad type passed to fsmMutateCh: %#v", ptr))
}
case req := <-r.fsmSnapshotCh:
snapshot(req)
}
}
}hashicorp raft 的同步就是这样了. 其实过程简单说, 上层写日志, leader 同步日志, follower 接收日志, leader 确认提交日志, follower 跟着提交日志.