团队写了一个 api 网关服务,需要我进行并发和稳定性压测。一说压测大家会想起ab, wrk工具。 apache的ab性能有点差强人意,虽然事件用的也是epoll,奈何是单线程,不能泡满cpu。wrk是个好东西,基于redis ae_event封装的事件池,另外可以多线程模式和lua脚本。
但如果压测的逻辑比较复杂,那么lua就不好搞了,尤其需要第三方模块引入的时候。 作为两三年经验的gopher来说,自然会使用golang写压力测试脚本。
进行压测的时候,我们发现一个go性能问题,不管是http压测客户端还是api服务端,都存在cpu利用率不高的问题。不管你的协程加到多大,cpu总是跑不满,利用率不高。top看每个cpu核心的idle空闲不少,软中断也没有问题,内核日志也没有报错,网络的全连接和半连接也没有异常,网络带宽更不是问题。
注:5000个协程跟10000个协程,http压测场景下,他的cpu表现是一样的
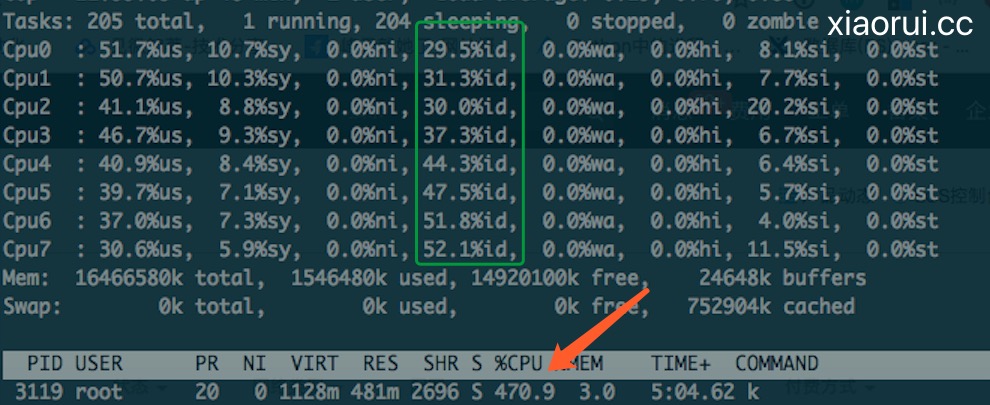
当我们把服务端的api转发功能关闭,只保留web功能。使用wrk压测可以看到服务端的cpu是可以被打满的。压测的客户端是http请求,api网关也是http请求,存在共性。那是不是可以猜测go net/http请求存在瓶颈?
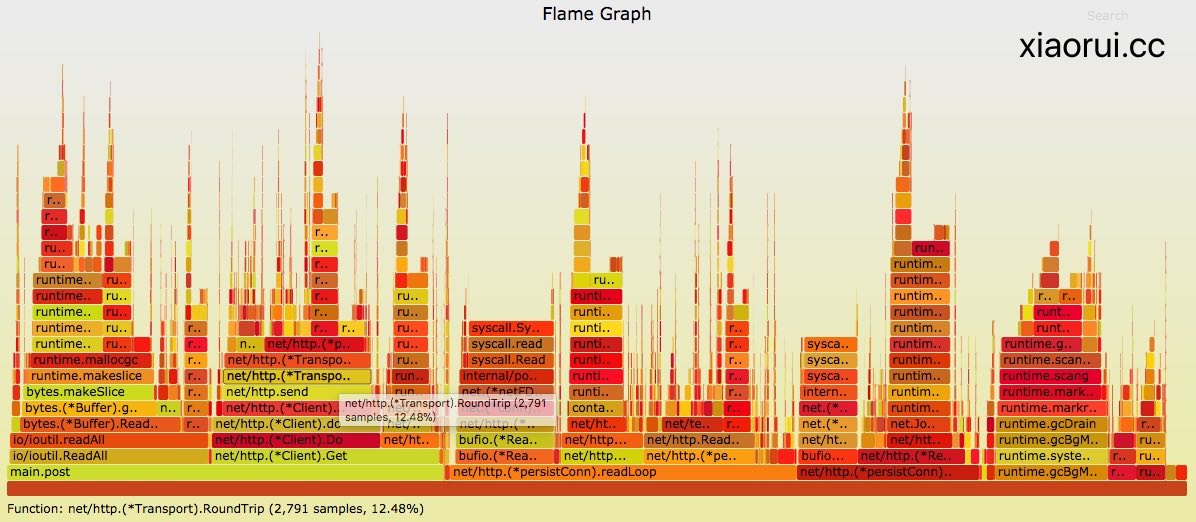
下面是我们通过go tool pprof的分析报告。发现net/http transport的耗时有点大,transport只是个net/http的连接池,按道理应该很快。这里耗时相对大的有两个方法,tryPutIdleConn用来塞回连接,roundTrip用来获取连接。下面我们分析下net/http transport的源码。
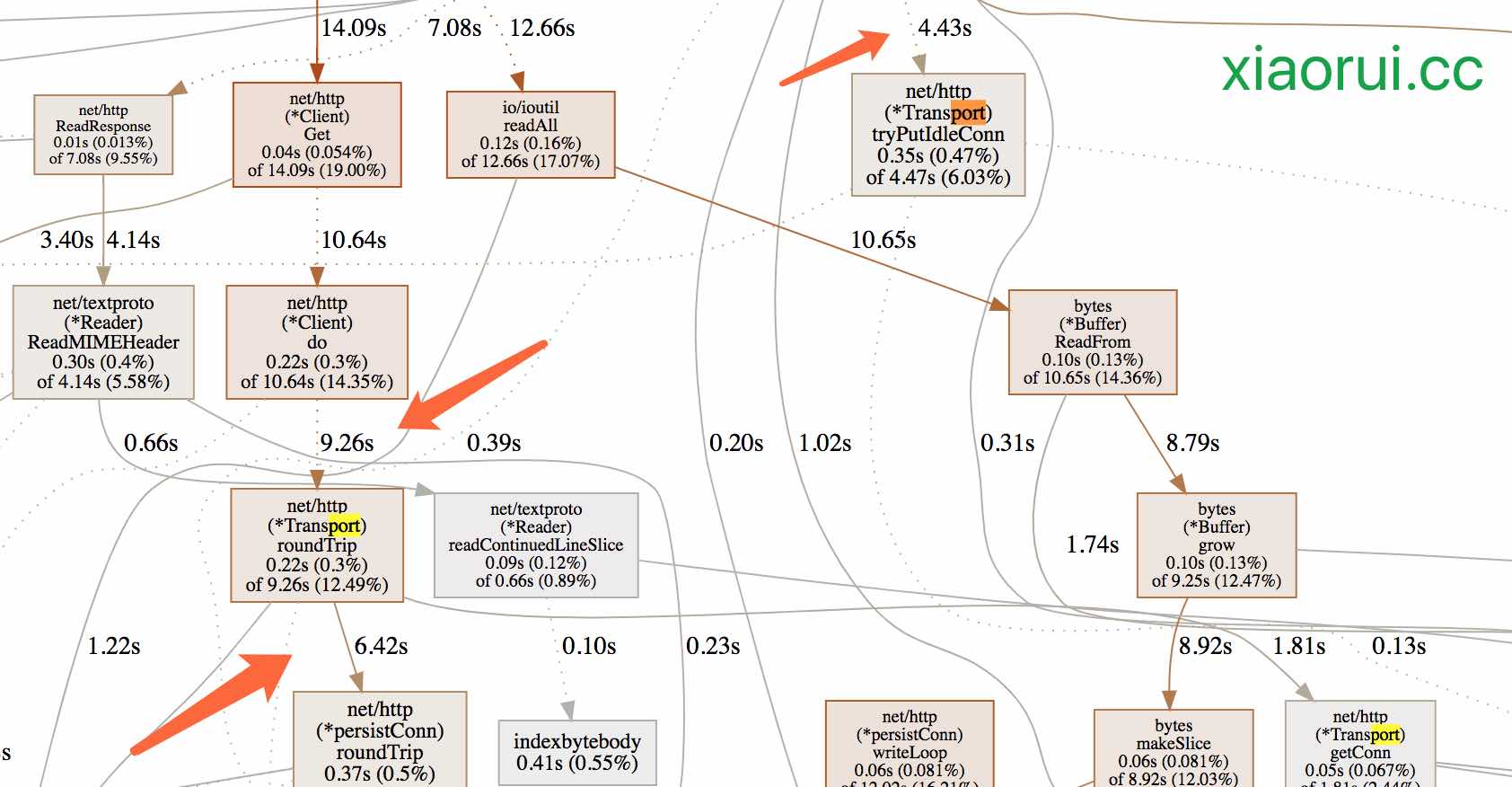
先说下net/http transport连接池的数据结构,最直观的感受是锁多。
// xiaorui.cc
type Transport struct {
idleMu sync.Mutex
wantIdle bool // user has requested to close all idle conns
idleConn map[connectMethodKey][]*persistConn
idleConnCh map[connectMethodKey]chan *persistConn
reqMu sync.Mutex
reqCanceler map[*Request]func()
altMu sync.RWMutex
altProto map[string]RoundTripper // nil or map of URI scheme => RoundTripper
//Dial获取一个tcp 连接,也就是net.Conn结构,你就记住可以往里面写request, 然后从里面搞到response就行了
Dial func(network, addr string) (net.Conn, error)
}继续看下golang net/http是如何从连接池里获取可用连接的,入口是RoundTrip方法。
// xiaorui.cc
func (t *Transport) RoundTrip(req *Request) (resp *Response, err error) {
...
pconn, err := t.getConn(req, cm)
if err != nil {
t.setReqCanceler(req, nil)
req.closeBody()
return nil, err
}
return pconn.roundTrip(treq)
}Transport会先调用getConn获取连接,继而调用persistConn的roundTrip方法,各种channel的select。
// xiaorui.cc
func (t *Transport) getConn(req *Request, cm connectMethod) (*persistConn, error) {
if pc := t.getIdleConn(cm); pc != nil {
t.setReqCanceler(req, func() {})
return pc, nil
}
type dialRes struct {
pc *persistConn
err error
}
dialc := make(chan dialRes)
prePendingDial := prePendingDial
postPendingDial := postPendingDial
....
cancelc := make(chan struct{})
t.setReqCanceler(req, func() { close(cancelc) })
// 启动了一个goroutine, 这个goroutine 获取里面调用dialConn搞到
// persistConn, 然后发送到上面建立的channel dialc里面,
go func() {
pc, err := t.dialConn(cm)
dialc <- dialRes{pc, err}
}()
idleConnCh := t.getIdleConnCh(cm)
select {
case v := <-dialc:
// dialc 我们的 dial 方法先搞到通过 dialc通道发过来了
return v.pc, v.err
case pc := <-idleConnCh:
// 这里代表其他的http请求用完了归还的persistConn通过idleConnCh channel发送来的
handlePendingDial()
return pc, nil
case <-req.Cancel:
handlePendingDial()
return nil, errors.New("net/http: request canceled while waiting for connection")
case <-cancelc:
handlePendingDial()
return nil, errors.New("net/http: request canceled while waiting for connection")
}
}最后分析下tryPutIdleConn返回连接的方法,当请求完毕后,根据各种条件来选择是塞回idle管道还是直接关闭。
// xiaorui.cc
func (t *Transport) tryPutIdleConn(pconn *persistConn) error {
...
t.idleMu.Lock()
defer t.idleMu.Unlock()
waitingDialer := t.idleConnCh[key]
select {
case waitingDialer <- pconn:
return nil
default:
if waitingDialer != nil {
delete(t.idleConnCh, key)
}
}
if t.wantIdle {
return errWantIdle
}
if t.idleConn == nil {
t.idleConn = make(map[connectMethodKey][]*persistConn)
}
idles := t.idleConn[key]
if len(idles) >= t.maxIdleConnsPerHost() {
return errTooManyIdleHost
}
for _, exist := range idles {
if exist == pconn {
log.Fatalf("dup idle pconn %p in freelist", pconn)
}
}
t.idleConn[key] = append(idles, pconn)
t.idleLRU.add(pconn)
if t.MaxIdleConns != 0 && t.idleLRU.len() > t.MaxIdleConns {
oldest := t.idleLRU.removeOldest()
oldest.close(errTooManyIdle)
t.removeIdleConnLocked(oldest)
}
if t.IdleConnTimeout > 0 {
if pconn.idleTimer != nil {
pconn.idleTimer.Reset(t.IdleConnTimeout)
} else {
pconn.idleTimer = time.AfterFunc(t.IdleConnTimeout, pconn.closeConnIfStillIdle)
}
}
pconn.idleAt = time.Now()
return nil
}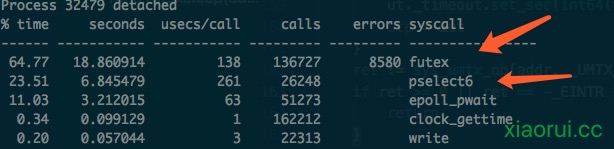
系统调用的统计里,我们发现futex和pselect6特别的多。futex是锁的系统调用,pselect6是高精度的休眠,他可以休眠微妙,纳秒。毫无疑问,不管你啥精度休眠都会线程的。
我们分析net/nttp transport源码发现其内部有各种的共享的channel和mutex,channel内部也有锁。我以前写过一篇文章阐述过golang锁竞争带来的问题,一方面syscall过多,另一方面出现cpu不饱和、利用率低的情况。
为啥cpu不饱和,你都sleep了还上哪去跑cpu,因没有触发handoffp,所以线程不会新增,已有的线程都在跑pselect6系统调用了,好了,直接贴runtime代码。
注: 朋友问了我一个问题,当runtime sleep的时候,为什么sysmon没有发生retake(),sysmon的代码里有说,当超过10ms的时候,才会发生抢占,继而handoffp,后startm ! futexsleep的sleep也就几微秒,不会发出抢占调度,当在for循环里多次拿不到锁,他会yield切出去。
// xiaorui.cc
func lock(l *mutex) {
...
// wait is either MUTEX_LOCKED or MUTEX_SLEEPING
// depending on whether there is a thread sleeping
// on this mutex. If we ever change l->key from
// MUTEX_SLEEPING to some other value, we must be
// careful to change it back to MUTEX_SLEEPING before
// returning, to ensure that the sleeping thread gets
// its wakeup call.
wait := v
for {
// Try for lock, spinning.
for i := 0; i < spin; i++ {
for l.key == mutex_unlocked {
if atomic.Cas(key32(&l.key), mutex_unlocked, wait) {
return
}
}
procyield(active_spin_cnt)
}
...
futexsleep(key32(&l.key), mutex_sleeping, -1)
}
}
// xiaorui.cc
func futexsleep(addr *uint32, val uint32, ns int64) {
var ts timespec
// Some Linux kernels have a bug where futex of
// FUTEX_WAIT returns an internal error code
// as an errno. Libpthread ignores the return value
// here, and so can we: as it says a few lines up,
// spurious wakeups are allowed.
if ns < 0 {
futex(unsafe.Pointer(addr), _FUTEX_WAIT_PRIVATE, val, nil, nil, 0)
return
}
if sys.PtrSize == 8 {
ts.set_sec(ns / 1000000000)
ts.set_nsec(int32(ns % 1000000000))
} else {
ts.tv_nsec = 0
ts.set_sec(int64(timediv(ns, 1000000000, (*int32)(unsafe.Pointer(&ts.tv_nsec)))))
}
futex(unsafe.Pointer(addr), _FUTEX_WAIT_PRIVATE, val, unsafe.Pointer(&ts), nil, 0)
}问题的原因是锁竞争造成的,怎么减少net/http的锁竞争?多开几个net/http transport连接池不就行了。 然后针对连接池做轮询算法。这个轮询算法不要加锁 !!! 加锁又产生锁竞争了 ! 压测客户端和api网关改进调优的思路是一样的。
那么多开Transport连接池会有什么问题? 连接数明显多了起来,另外前期预热期间会不断的new新连接,三次握手较多,请求会稍微慢一点,后面就ok了。另外http连接也会参与tcp的心跳检查,当然这类交互在内核层,上层无须关心。
// xiaorui.cc
var (
clientList = []*http.Client{}
...
)
func makeClientList(count int) []*http.Client {
clientList := make([]*http.Client, count, count)
for index := 0; index < count; index++ {
clientList[index] = newClient()
}
return clientList
}
func getClient() *http.Client {
return clientList[rand.Int()%len(clientList)]
}看下客户端在多开transport的cpu表现情况,cpu的利用率明显上来了。另外QPS吞吐也到了6W左右。
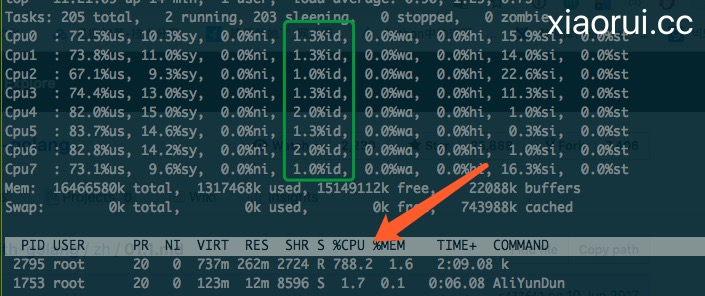
这时候我们再来看下go pprof cpu耗时图,发现 transport的耗时缩短了不少,不管是RoundTrip获取连接和tryPutIdleConn返回连接。
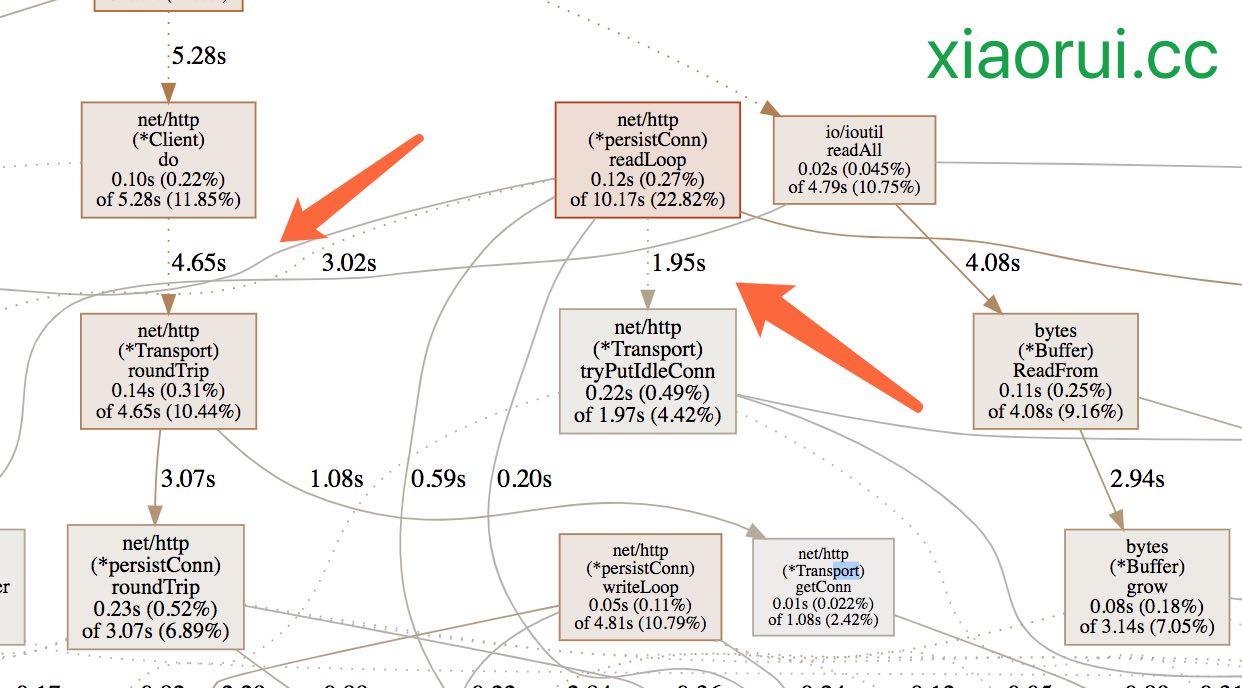
通过火焰图看到不少比net/http transport更加耗时的地方,比如readLoop和writeLoop耗时更大,分析这两个方法的源代码,各种的channel横飞,就现在来说没得优化,这两个方法是net/http最核心的读写逻辑,这个cpu消耗可以接受。还有一个io/ioutil.ReadAll的消耗,ReadAll内部不断的在makeSlice空间,也增加gc的消耗,后面可以加个sync.Pool缓冲池。
这是我遇第三次遇到因为golang锁调度的问题,导致cpu利用率上不去,起先还天真以为是golang的协程调度的瓶颈。 去年在写cdn服务网关时,也遇到一个奇葩问题,cpu利用率也上不去,但是top的sys消耗比较大,通过strace抽样分析futex调用数高的吓人,最后跟分析原因是map的锁竞争引起的,改进成map分段锁解决。