Horovod core principles are based on the MPI concepts size, rank, local rank, allreduce, allgather, broadcast, and alltoall. These are best explained by example. Say we launched a training script on 4 servers, each having 4 GPUs. If we launched one copy of the script per GPU:
- Size would be the number of processes, in this case, 16.
- Rank would be the unique process ID from 0 to 15 (size - 1).
- Local rank would be the unique process ID within the server from 0 to 3.
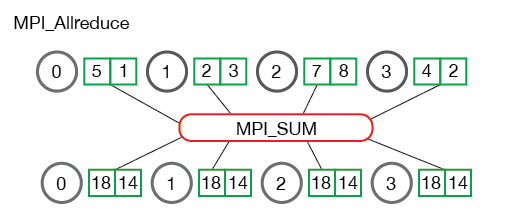
- Allreduce is an operation that aggregates data among multiple processes and distributes results back to them. Allreduce is used to average dense tensors. Here's an illustration from the MPI Tutorial:
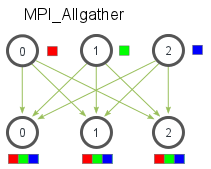
- Allgather is an operation that gathers data from all processes on every process. Allgather is used to collect values of sparse tensors. Here's an illustration from the MPI Tutorial:
Broadcast is an operation that broadcasts data from one process, identified by root rank, onto every other process. Here's an illustration from the MPI Tutorial:
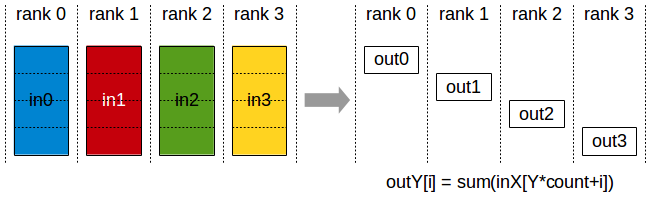
Reducescatter is an operation that aggregates data among multiple processes and scatters the data across them. Reducescatter is used to average dense tensors then split them across processes. Here's an illustration from the Nvidia developer guide:
Alltoall is an operation to exchange data between all processes. Alltoall may be useful to implement neural networks with advanced architectures that span multiple devices.