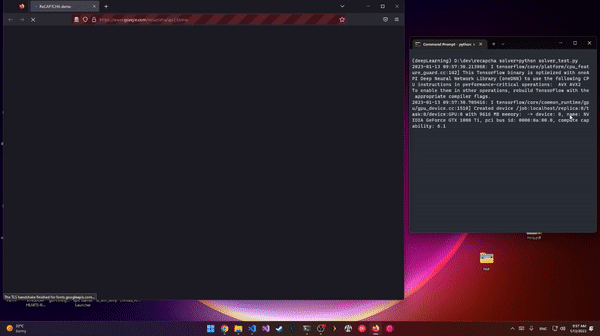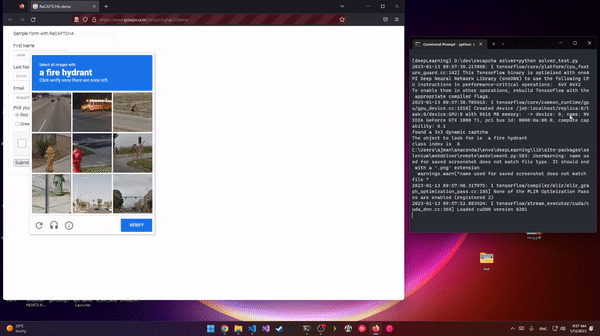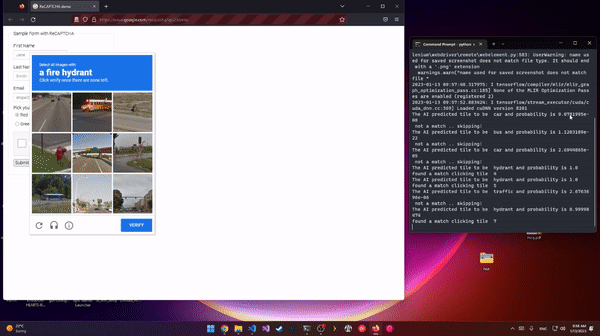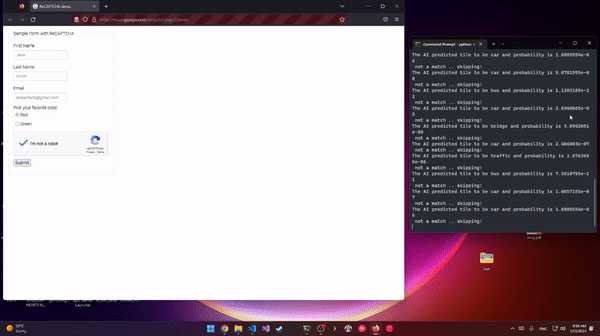
Deep-reCaptcha is a recaptcha solver built using python and selenium. It uses deep learning to predict the captcha in action and click it. Deep-reCaptcha uses a pretrained model, efficientNet v2, the M variant used for the balance between size and accurecy. This project is made for educational purposes.
python 3.9 is used. It should work with other versions though. Packages installed are tensorflow 2.10, numpy, selenium and pillow. The script will check for the model first and download it if not present from github, then will launch the reCaptcha demo page and solve it. the 4x4 captcha type is skipped for now as I have not implemented
As for selenium, I am using firefox. download the last version of gecko driver
The model was trained on a combination of datasets but mainly on brian-the-dev recaptcha dataset found on github. A model built up by first fitting the model without any training paramaters and then fine tune it multiple time to achieve the best accurecy with minimal val loss.
Classes in the model are:
CLASSES = [
"bicycle",
"bridge",
"bus",
"car",
"chimney",
"crosswalk",
"hydrant",
"motorcycle",
"other",
"palm",
"stairs",
"traffic_light"
]an ImageDataGenerator used to increase the training size with augementations
train_datagen = ImageDataGenerator( preprocessing_function=preprocess_input ,
validation_split=0.2,
rotation_range = 30,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True,
)
test_datagen = ImageDataGenerator( preprocessing_function=preprocess_input,
validation_split=0.2,
)A baseline fit with no trainable params was excuted with around 20 epochs with early stop to avoid overfitting. after that a loop of training was made with incrementel increase in trainable params.
#finetuning
n_epochs = 5
batch_size = 50
nb_finetune_samples = nb_train_samples
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(
monitor="val_loss",
factor=0.1,
patience=1,
verbose=0,
mode="auto",
min_delta=0.00001,
cooldown=0,
min_lr=0,
)
early_stop = tf.keras.callbacks.EarlyStopping(
monitor="val_loss",
patience=10,
verbose=0,
mode="auto",
restore_best_weights=True,
)
checkpoint = tf.keras.callbacks.ModelCheckpoint('checkpoint.h5',monitor='val_loss', save_best_only=True)
percentage_to_not_train = 100
for _ in range(7):
percentage_to_not_train = percentage_to_not_train - 10
ltt = len(base_model.layers) // percentage_to_not_train
base_model.trainable = True
for layer in base_model.layers[:int(ltt)]:
base_model.trainable = False
model.compile(optimizer=tf.keras.optimizers.Adam(0.00001),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=["accuracy"],
)
training = model.fit(train_generator,
steps_per_epoch=nb_finetune_samples//batch_size,
validation_data=validation_generator,
validation_steps=nb_validation_samples//batch_size,
epochs=n_epochs,
callbacks=[reduce_lr, checkpoint, early_stop])At the end, an accurecy of 74% was reached which is more than enough for a captcha in my opinion (those can be daunting even for humans).
Pull requests are welcome. For major changes, please open an issue first to discuss what you would like to change.
Please make sure to update tests as appropriate.