上篇主要介绍了 rosedb 的 string 和 list 数据结构在 bitcask 存储模型下的实现原理。本文讲解 hash、set、zset (sorted set) 的实现原理。
golang bitcask rosedb 存储引擎实现原理系列的文章地址 (更新中)
https://github.com/rfyiamcool/notes#golang-bitcask-rosedb
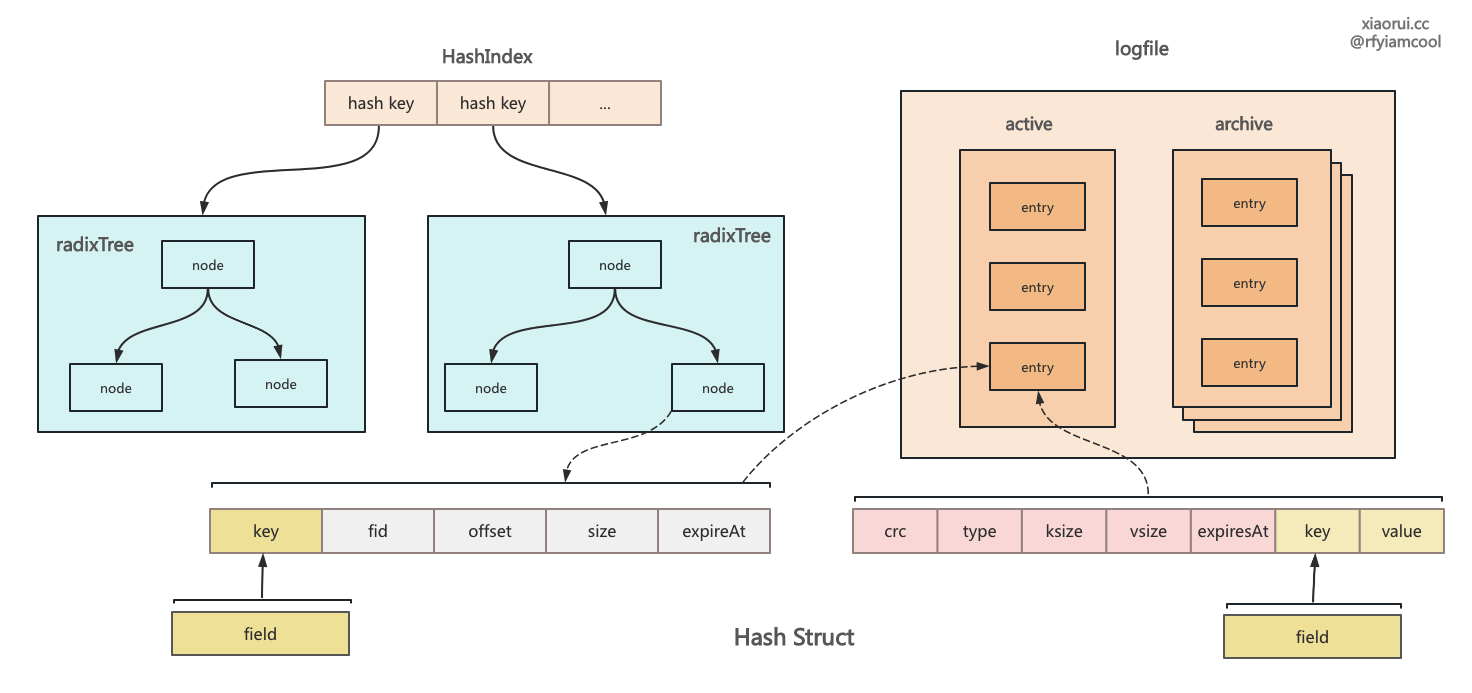
HSet 用来实现插入和更新 hash 字典,构建一个 entry 结构对象,然后该对象写到 logfile 里,entry 的 key 是由 key 和 field 编码生成的,目的在于启动恢复时通过 entry 的 key 值还原出 hash key 和 filed 两个字段。 最后在 radixTree 索引里添加 member 和 valuePos 的映射。
func (db *RoseDB) HSet(key []byte, args ...[]byte) error {
// 只对 hash 结构进行加锁
db.hashIndex.mu.Lock()
defer db.hashIndex.mu.Unlock()
// 参数为 0,或者 args 为单数则说明参数异常
if len(args) == 0 || len(args)&1 == 1 {
return ErrWrongNumberOfArgs
}
// 获取 hash key 的 radixTree 索引, rosedb 除了 string 共用一个索引外,其他容器类的数据结构,每个 key 都有一个独立索引。
if db.hashIndex.trees[string(key)] == nil {
// 新 key 则需要创建
db.hashIndex.trees[string(key)] = art.NewART()
}
// 获取 hash key 关联的 radixtree 索引
idxTree := db.hashIndex.trees[string(key)]
// 成对遍历 args 数组
for i := 0; i < len(args); i += 2 {
// 赋值 field 和 value
field, value := args[i], args[i+1]
// key + field 构建 hashkey
hashKey := db.encodeKey(key, field)
// 构建 entry
entry := &logfile.LogEntry{Key: hashKey, Value: value}
// 把 entry 写入到 logfile 日志里
valuePos, err := db.writeLogEntry(entry, Hash)
if err != nil {
return err
}
// 再构建一个 entry 对象,这里的 key 为 filed 字段.
ent := &logfile.LogEntry{Key: field, Value: value}
_, size := logfile.EncodeEntry(entry)
valuePos.entrySize = size
// 把 entry 添加到 radixtree 索引上
err = db.updateIndexTree(idxTree, ent, valuePos, true, Hash)
if err != nil {
return err
}
}
return nil
}HGet 用来获取 hash 结构里 field 的 value,其内部的流程是这样,先获取 hash key 对应的 radixtree 索引,radixtree 索引上的 key 是 hash 的 field 字段,所以先从索引获取 field 对应的 valuePos,继而再从 logfile 里获取指定偏移的数据。
// HGet returns the value associated with field in the hash stored at key.
func (db *RoseDB) HGet(key, field []byte) ([]byte, error) {
// 加锁
db.hashIndex.mu.RLock()
defer db.hashIndex.mu.RUnlock()
// 判空
if db.hashIndex.trees[string(key)] == nil {
return nil, nil
}
// 获取 hash key 对应的 radixtree 索引
idxTree := db.hashIndex.trees[string(key)]
// radixtree 索引上的 key 是 hash 的 field 字段,所以先从索引获取 filed 对应的 valuePos,继而再从 logfile 里获取指定偏移的数据。
val, err := db.getVal(idxTree, field, Hash)
if err == ErrKeyNotFound {
return nil, nil
}
return val, err
}HDel 用来删除 hash 结构里的数据,删除流程就两步,追加写一条带 delete 标记的数据到 logfile 日志文件里,然后在索引里剔除该 field。
func (db *RoseDB) HDel(key []byte, fields ...[]byte) (int, error) {
db.hashIndex.mu.Lock()
defer db.hashIndex.mu.Unlock()
// 判空
if db.hashIndex.trees[string(key)] == nil {
return 0, nil
}
// 获取 hash key 相关的 radixtree
idxTree := db.hashIndex.trees[string(key)]
var count int
for _, field := range fields {
// 编码 key 和 field 获取新的 hashkey
hashKey := db.encodeKey(key, field)
// 写入一条有删除标记的数据到 logfile 日志文件里.
entry := &logfile.LogEntry{Key: hashKey, Type: logfile.TypeDelete}
valuePos, err := db.writeLogEntry(entry, Hash)
if err != nil {
return 0, err
}
// 从索引中删除.
val, updated := idxTree.Delete(field)
if updated {
count++
}
// 通知要删除数据到 discard.
db.sendDiscard(val, updated, Hash)
_, size := logfile.EncodeEntry(entry)
node := &indexNode{fid: valuePos.fid, entrySize: size}
select {
case db.discards[Hash].valChan <- node:
default:
logger.Warn("send to discard chan fail")
}
}
return count, nil
}HScan 用来实现 hash 数据的扫描,但 rosedb 实现的 hcan 跟 redis hash hscan 不同,redis hscan 是有实现 cursor 游标。
func (db *RoseDB) HScan(key []byte, prefix []byte, pattern string, count int) ([][]byte, error) {
// 加锁
db.hashIndex.mu.RLock()
defer db.hashIndex.mu.RUnlock()
// 判空
if db.hashIndex.trees[string(key)] == nil {
return nil, nil
}
// 获取 hash key 对应的索引对象
idxTree := db.hashIndex.trees[string(key)]
// 前缀扫描,获取 count 数量的字段
fields := idxTree.PrefixScan(prefix, count)
if len(fields) == 0 {
return nil, nil
}
// 遍历正则解析器
var reg *regexp.Regexp
if pattern != "" {
var err error
if reg, err = regexp.Compile(pattern); err != nil {
return nil, err
}
}
values := make([][]byte, 2*len(fields))
var index int
for _, field := range fields {
// 忽略不匹配正则规则的数据
if reg != nil && !reg.Match(field) {
continue
}
// 从 logfile 里获取数据
val, err := db.getVal(idxTree, field, Hash)
if err != nil && err != ErrKeyNotFound {
return nil, err
}
// 成对赋值
values[index], values[index+1] = field, val
index += 2
}
return values, nil
}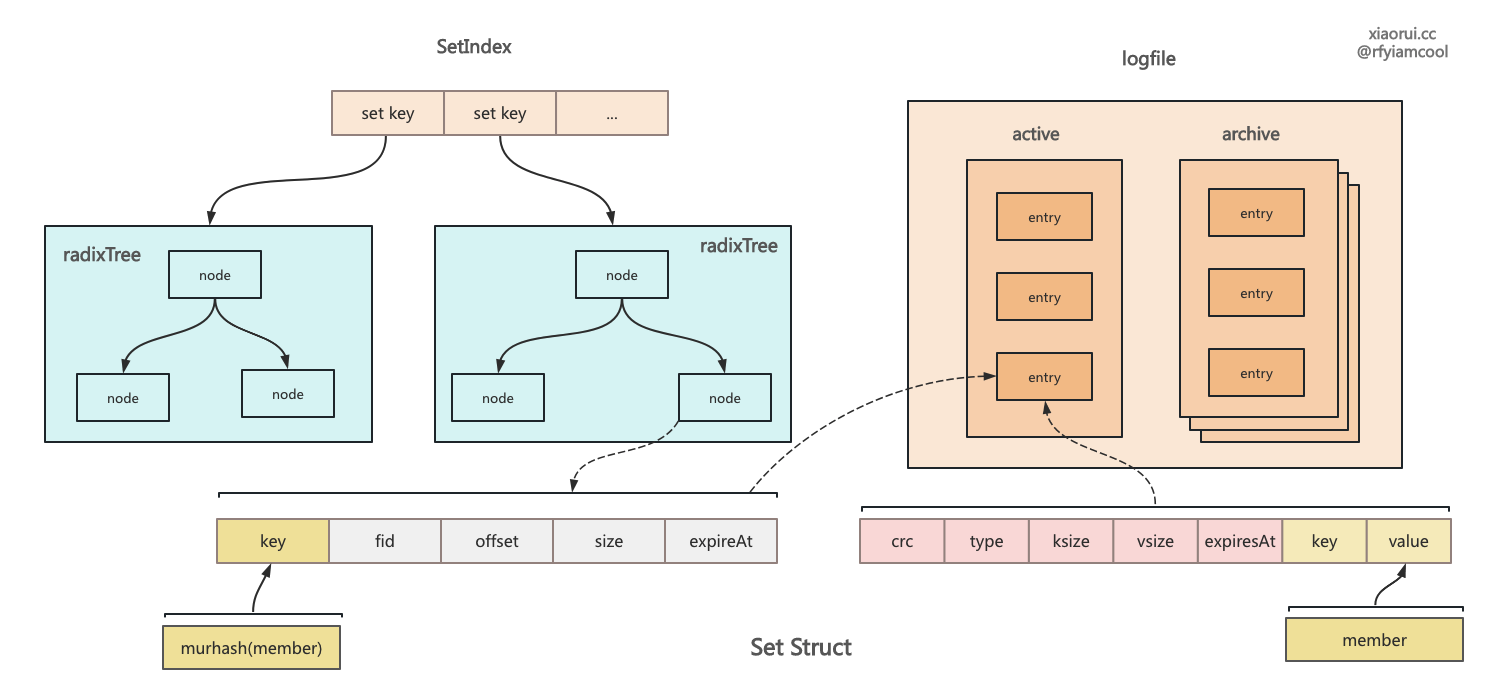
SAdd 用来把 member 成员插入到 set 集合里,其实现流程如下。
- 获取 set key 关联的 radixtree 索引,为空则实例化一个 radixtree 索引对象 ;
- 遍历需要写入的 members 列表 ;
- 计算 member 成员的哈希码,重置该 hash 计算器, 整个 set 集合共用一个 hash 计算对象,入口方法有锁保证其线程安全 ;
- 构建 entry 对象,并写到忽略 logfile 日志里 ;
- 构建一个索引的 entry 对象,key 使用 hashcode, 并把该 entry 更新到 radixtree 索引里。
其实 set 集合可以在 rosedb 的 hash 基础上封装下即可。相比 hash 字典来说,rosedb set 会 member 成员计算了 hash 值,radixTree 索引内部的 key 使用 hash 值, value 则还是 valuePos 文件偏移信息,有趣的是写到 logfile 里的 entry 格式有些奇怪,key 为 set 集合的 key,而 value 为 member 成员对象。rosedb 其他的数据结构的 key 有做处理的,要么跟 seq 一起编码,要么跟 field 一起编码。 这要求 rosedb 在启动阶段时对 set 结构的 logfile 做特殊处理,区别于其他结构。
set 和 zset 都使用 murmru hash 算法计算哈希值,其目的在于节省 member 在内存中的占用,经过哈希计算后最大占用 16 个字节。其实 murmur 相比 fnv hash 来说,性能是差点意思。
func (db *RoseDB) SAdd(key []byte, members ...[]byte) error {
// 老规矩,加锁
db.setIndex.mu.Lock()
defer db.setIndex.mu.Unlock()
// 为空则实例化一个 radixtree 索引对象
if db.setIndex.trees[string(key)] == nil {
db.setIndex.trees[string(key)] = art.NewART()
}
// 获取 set key 关联的 radixtree 索引
idxTree := db.setIndex.trees[string(key)]
// 遍历需要写入的 members 列表
for _, mem := range members {
if len(mem) == 0 {
continue
}
// 计算 members 的 hash code 哈希码.
if err := db.setIndex.murhash.Write(mem); err != nil {
return err
}
sum := db.setIndex.murhash.EncodeSum128()
// 重置该 hash 计算器, 整个 set 集合共用一个 hash 计算对象,入口方法有锁保证其线程安全.
db.setIndex.murhash.Reset()
// 构建 entry 对象,写到 logfile 日志里.
ent := &logfile.LogEntry{Key: key, Value: mem}
valuePos, err := db.writeLogEntry(ent, Set)
if err != nil {
return err
}
// 构建一个待插入索引的 entry 对象,key 使用 hashcode。
entry := &logfile.LogEntry{Key: sum, Value: mem}
_, size := logfile.EncodeEntry(ent)
valuePos.entrySize = size
// 更新索引
if err := db.updateIndexTree(idxTree, entry, valuePos, true, Set); err != nil {
return err
}
}
return nil
}SRem 用来删除 set 集合里的 member 成员.
func (db *RoseDB) SRem(key []byte, members ...[]byte) error {
db.setIndex.mu.Lock()
defer db.setIndex.mu.Unlock()
// 判空
if db.setIndex.trees[string(key)] == nil {
return nil
}
// 遍历 members 对象列表
for _, mem := range members {
// 删除 member
if err := db.sremInternal(key, mem); err != nil {
return err
}
}
return nil
}sremInternal 用来删除 set 集合里的 member 成员对象。其内部实现是计算 member 的 hash 值,然后从 radixTree 索引中剔除 key 为 hash 值的数据,然后在 logfile 里写一篇有 delete 标记的 entry 写入到 logfile 文件里,等待 rosedb 在 compact gc 时把数据给清理掉。
func (db *RoseDB) sremInternal(key []byte, member []byte) error {
// 获取 set key 对应的 radixtree 索引对象
idxTree := db.setIndex.trees[string(key)]
// 计算出 member 的 hashcode
if err := db.setIndex.murhash.Write(member); err != nil {
return err
}
sum := db.setIndex.murhash.EncodeSum128()
// 重置对象
db.setIndex.murhash.Reset()
// 在索引中删除
val, updated := idxTree.Delete(sum)
if !updated {
return nil
}
// 把一条有 delete 标记 entry 写到 logfile 日志文件里.
entry := &logfile.LogEntry{Key: key, Value: sum, Type: logfile.TypeDelete}
pos, err := db.writeLogEntry(entry, Set)
if err != nil {
return err
}
// 通知 discard 做统计
db.sendDiscard(val, updated, Set)
_, size := logfile.EncodeEntry(entry)
node := &indexNode{fid: pos.fid, entrySize: size}
select {
case db.discards[Set].valChan <- node:
default:
}
return nil
}zset 是 rosedb 里最为复杂的数据结构了,其实在 redis 里除了 stream 外,zset 也是最复杂的那个。zset 是有序集合,不仅要实现有序,而且要做到去重集合的特性,单纯有序且去重的话,找个 avl, rbtree 都可以做到,java 的 hashmap 在触发阈值下也会从链表优化成红黑树。zset 的有序不是针对 member 排序,而是对关联的 score 分值做排序。
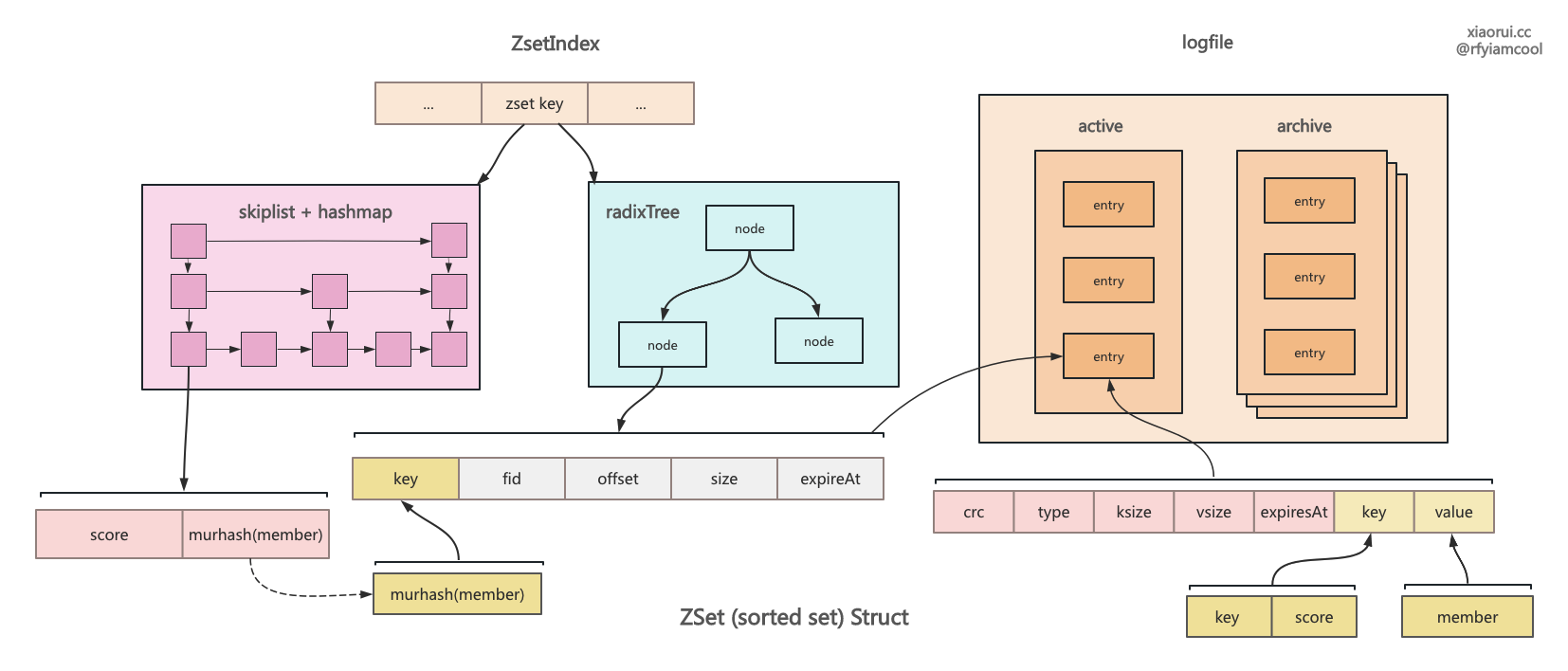
redis 的 zset 是使用 hashmap 和 skiplist 两个结构实现的,而 rosedb 则对每个 zset key 使用了两组数据结构,一个是 radixTree,一个是 hashmap + skiplist 组成的 sortedSet 结构。 radixTree 的 key 为 member 的哈希值,value 为 valuePos 值。 而 sortedSet 内的跳表使用 score 字段来排序,其每个 skiplist node 的 key 为 score 分值,而 value 为 memebr 的哈希值,另外 sortedSet 里的 hashmap 的 key 为 member 哈希值,则 value 是含有 member、score 的 skiplist node 节点。
rosedb zset 结构的实现有些冗余,其实直接使用 sortedset 就可以了,在 skiplist node 里增加 valuePos 字段即可。按照 zset 的实际应用场景,member 通常为一些标记字段,如数据库的 id 或分布式 id 等,其实无需计算成 16 字节的哈希值,还使用哈希值关联 logfile。其实直接把 member 原始值保存在内存索引中也没什么问题。
func (db *RoseDB) ZAdd(key []byte, score float64, member []byte) error {
// 常规加锁
db.zsetIndex.mu.Lock()
defer db.zsetIndex.mu.Unlock()
// 计算出添加 member 的哈希值
if err := db.zsetIndex.murhash.Write(member); err != nil {
return err
}
sum := db.zsetIndex.murhash.EncodeSum128()
db.zsetIndex.murhash.Reset()
// 获取 zset key 对应的 radixtree 索引对象
if db.zsetIndex.trees[string(key)] == nil {
// 无,则实例化新的 radixtree 对象
db.zsetIndex.trees[string(key)] = art.NewART()
}
idxTree := db.zsetIndex.trees[string(key)]
// 转化 score 分值为字节数组
scoreBuf := []byte(util.Float64ToStr(score))
// 使用 key 和 socre 编码生成一个 zset key
zsetKey := db.encodeKey(key, scoreBuf)
// 构建一个 entry 对象, key 为 zsetkey, value 为 member, 写入到 logfile 日志文件里.
entry := &logfile.LogEntry{Key: zsetKey, Value: member}
pos, err := db.writeLogEntry(entry, ZSet)
if err != nil {
return err
}
_, size := logfile.EncodeEntry(entry)
pos.entrySize = size
// 构建一个在内存索引中使用的 entry 对象, key 为哈希值, value 为 member 成员.
ent := &logfile.LogEntry{Key: sum, Value: member}
// 更新到 radix tree 索引中
if err := db.updateIndexTree(idxTree, ent, pos, true, ZSet); err != nil {
return err
}
// rosedb 写的 radixtree 索引用来获取 member 数据,无法实现排序和数值间的范围查询.
// 所以这里使用一个 skiplist 跳表实现 redis zset 结构的复杂查询.
db.zsetIndex.indexes.ZAdd(string(key), score, string(sum))
return nil
}ZScore 用来获取 member 的 socre 分值。rosedb 没通过 zset 的 radixTree 来查询 valuePos,继而在到 logfile 里查询到 socre 分值。 其实 zset 内部通过跳表和hashmap 实现了类 redis 的 zset,分值的查询是依赖这个 zset 实现的。
zset 数据结构的代码位置: rosedb/ds/zset/zset.go
func (db *RoseDB) ZScore(key, member []byte) (ok bool, score float64) {
db.zsetIndex.mu.RLock()
defer db.zsetIndex.mu.RUnlock()
if err := db.zsetIndex.murhash.Write(member); err != nil {
return false, 0
}
sum := db.zsetIndex.murhash.EncodeSum128()
db.zsetIndex.murhash.Reset()
return db.zsetIndex.indexes.ZScore(string(key), string(sum))
}func (db *RoseDB) ZRem(key, member []byte) error {
db.zsetIndex.mu.Lock()
defer db.zsetIndex.mu.Unlock()
// 计算获取 member 的哈希值
if err := db.zsetIndex.murhash.Write(member); err != nil {
return err
}
sum := db.zsetIndex.murhash.EncodeSum128()
db.zsetIndex.murhash.Reset()
// 从 zset 索引中删除数据
ok := db.zsetIndex.indexes.ZRem(string(key), string(sum))
if !ok {
return nil
}
if db.zsetIndex.trees[string(key)] == nil {
db.zsetIndex.trees[string(key)] = art.NewART()
}
idxTree := db.zsetIndex.trees[string(key)]
// 接着从 radixtree 删除数据
oldVal, deleted := idxTree.Delete(sum)
// 把删除操作通知给 discard
db.sendDiscard(oldVal, deleted, ZSet)
// 写一条带有 delete 标记的数据到 logfile 日志文件里.
entry := &logfile.LogEntry{Key: key, Value: sum, Type: logfile.TypeDelete}
pos, err := db.writeLogEntry(entry, ZSet)
if err != nil {
return err
}
// ...
return nil
}到此,关于 rosedb 里 string、list、hash、set 和 zset 的数据结构的实现分析完了。 相比那些基于 lsmtree 封装的 redis 结构来说,基于 bitcask 实现这类结构还是相对简单不少,在 logfile 里写入 entry 数据,怎么写都可以,只需要再次启动时可以还原构建出索引即可,反而重点是如何在内存里构建 redis 的哪些数据结构。
string 是个简单的 kv,实现最简单,也最基础。list 是个链表结构,需要存储一个 metadata 记录了当前头尾的序号,后面的增删改查都依赖这个序号。hash 是个字典结构,radixtree 索引中记录 field 和 valuePos 的关系,而 logfile 的 key 为 key 和 field 的组合。 set 是个集合结构,radixtree 索引中记录了 member 的哈希值,而 logfile 记录了完整的 kv。zset 是 rosedb 里最为复杂的结构,其内部使用 sortedset 和 radixtree 来实现。
rosedb 里 hash 字典结构的设计
rosedb 里 set 集合结构的设计
rosedb 里 zset 有序集合结构的设计