golang 社区里使用 bitcask 模型设计的 kv 存储有不少,比较突出的主要有 rosedb 和 nutsdb。这两个项目有很多的公共点,首先都是基于 bitcask 设计的,然后都在 kv 存储的基础上封装了 redis 数据结构,更利于上层的使用。还有这俩项目还都是国人开发的。😅 现在国内的不少数据库在社区很有影响力的,像 tidb,tikv,databend 等产品。
由于 nutsdb 在社区中已经有人讲过了,所以选择通过 rosedb 分析下, 如何基于 bitcask 模型实现 redis 结构存储引擎的实现原理。
本篇主要分析 rosedb 的 string 和 list 数据结构的实现原理,还有 bitcask 存储模型里索引和文件的映射关系。
golang bitcask rosedb 存储引擎实现原理系列的文章地址 (更新中)
https://github.com/rfyiamcool/notes#golang-bitcask-rosedb
这里的 string 跟 redis string 是一样的,就是最简单的 kv 用法,Set 是写入 kv,Get 为读取 kv,Delete 为删除 kv。 当然 rosedb 也实现了 redis string 结构里大部分的命令。
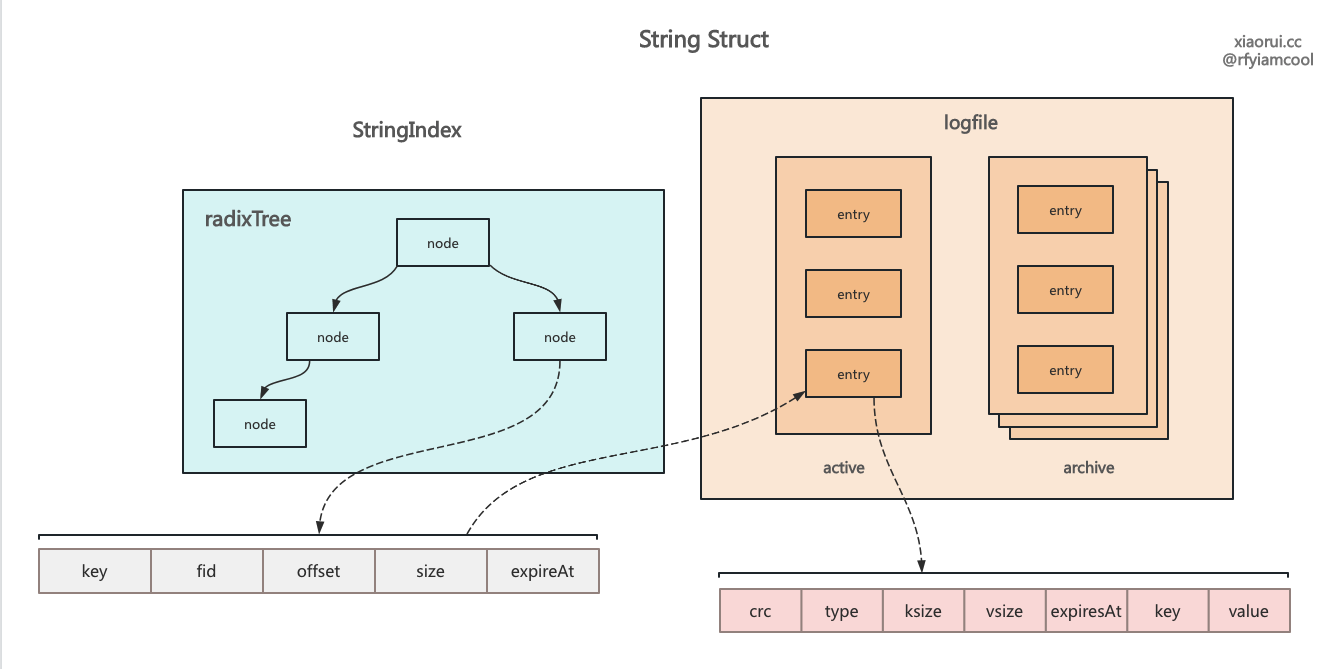
Set 是 rosedb 的写数据的方法, 该 Set 用法是跟 redis set 命令对齐的. 其内部实现较为简单, 构建一个 logEntry 对象, 把数据写到活跃的 logfile 里并返回 valuePos 结构, valuePos 里面有 kv 在 file 的偏移量信息. 最后把 key 和 valuePos 写到 string 类型的 radixTree 基数索引里。 如果是内存模式,需要在索引里保存完整的 kv,而存储模式则需要在索引 index 只需要保存 key 和 valuePos。
// 记录 key 在 logfile 的位置信息, fid 是文件序号名, offset 为偏移量, entrySize 为 entry 的长度.
type valuePos struct {
fid uint32
offset int64
entrySize int
}
func (db *RoseDB) Set(key, value []byte) error {
// 加锁,rosedb 里每个 redis 类型都有一把锁,其目的在于减少锁竞争, 分化唯一锁的竞争压力.
db.strIndex.mu.Lock()
defer db.strIndex.mu.Unlock()
// 构建 entry
entry := &logfile.LogEntry{Key: key, Value: value}
// 把 entry 写到 log file 里
valuePos, err := db.writeLogEntry(entry, String)
if err != nil {
return err
}
// 把 entry 的信息插入到 string 类型的 index 索引上, 这里的 index 使用 radixTree 实现的.
// 如果是内存模式,需要在 index 保存 kv,而存储模式在 index 只需要保存 key 和 valuePos.
err = db.updateIndexTree(db.strIndex.idxTree, entry, valuePos, true, String)
return err
}writeLogEntry 用来把数据写到日志文件里,其内部流程如下。
- 尝试初始化 logfile ;
- 获取传入 DateType 类型的 activeLogFile, rosedb 里每个类型是分别存储的 ;
- 编码 entry 为 bytes 字节数组 ;
- 如果当前 logfile 的 size 跟 entry 相加大于 512MB 阈值,则需要构建一个新的 logfile 日志文件 ;
- 将编码后的数据写到当前活跃的 logfile 日志文件里 ;
- 如果开启实时同步,则需要调用 sync 同步刷盘.
- 返回 valuePos 结构,该结构记录了 kv 的磁盘文件信息.
func (db *RoseDB) writeLogEntry(ent *logfile.LogEntry, dataType DataType) (*valuePos, error) {
// 尝试初始化 logfile
if err := db.initLogFile(dataType); err != nil {
return nil, err
}
// 获取传入 DateType 类型的 activeLogFile, rosedb 里每个类型是分别存储的.
activeLogFile := db.getActiveLogFile(dataType)
if activeLogFile == nil {
// 如果为空, 则说明异常.
return nil, ErrLogFileNotFound
}
opts := db.opts
// 编码 entry 为 bytes 字节数组.
entBuf, esize := logfile.EncodeEntry(ent)
// 如果当前 logfile 的 size 跟 entry 相加大于阈值,则需要构建一个新的 logfile 日志文件.
// 阈值默认为 512MB
if activeLogFile.WriteAt+int64(esize) > opts.LogFileSizeThreshold {
// 把 page cache 的数据同步刷到磁盘
if err := activeLogFile.Sync(); err != nil {
return nil, err
}
db.mu.Lock()
// 把当前的 activeLogFile 放到归档集合里.
activeFileId := activeLogFile.Fid
if db.archivedLogFiles[dataType] == nil {
db.archivedLogFiles[dataType] = make(archivedFiles)
}
db.archivedLogFiles[dataType][activeFileId] = activeLogFile
// 生成一个新的 log file 文件对象.
ftype, iotype := logfile.FileType(dataType), logfile.IOType(opts.IoType)
lf, err := logfile.OpenLogFile(opts.DBPath, activeFileId+1, opts.LogFileSizeThreshold, ftype, iotype)
if err != nil {
db.mu.Unlock()
return nil, err
}
// 跟踪记录 discards
db.discards[dataType].setTotal(lf.Fid, uint32(opts.LogFileSizeThreshold))
// 加入到活跃文件集合里.
db.activeLogFiles[dataType] = lf
activeLogFile = lf
db.mu.Unlock()
}
// 把编码后的数据写到 logFile 里。
writeAt := atomic.LoadInt64(&activeLogFile.WriteAt)
if err := activeLogFile.Write(entBuf); err != nil {
return nil, err
}
// 如果开启实时同步,则需要调用 sync 同步刷盘.
if opts.Sync {
if err := activeLogFile.Sync(); err != nil {
return nil, err
}
}
// 返回 valuePos 结构,该结构记录了 kv 在磁盘文件信息.
return &valuePos{fid: activeLogFile.Fid, offset: writeAt}, nil
}在 logfile 的每条数据都是由 header + kv 组成的, crc 校验码是对所有字段计算生成的. header 包含 类型 type,键的大小 keySize, 值的大小 valuesize 及 过期的时间 expireAt.
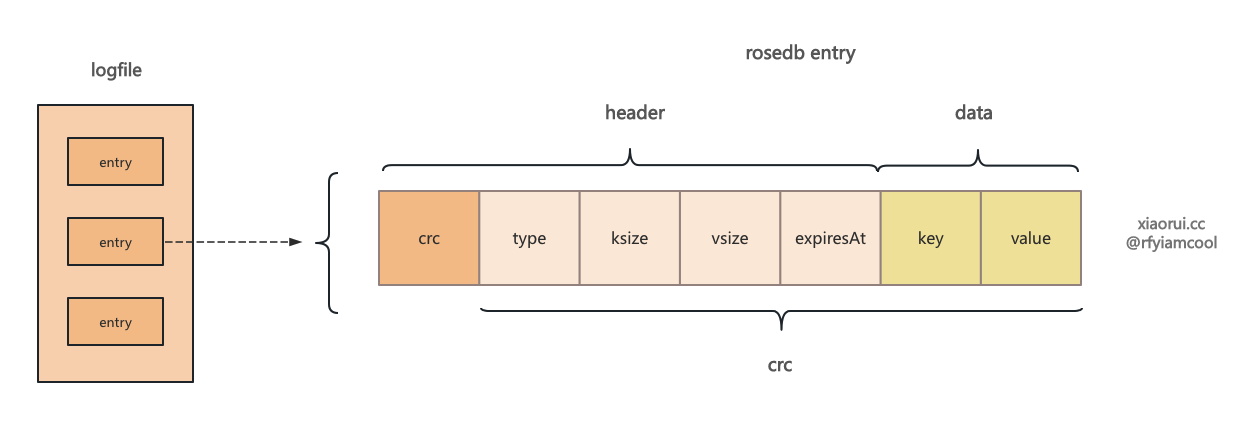
没什么可说的, 就是编码 entry 为字节数组。
func EncodeEntry(e *LogEntry) ([]byte, int) {
if e == nil {
return nil, 0
}
// MaxHeaderSize 为 25 个 字节.
header := make([]byte, MaxHeaderSize)
// 编码 header
header[4] = byte(e.Type)
var index = 5
// key size
index += binary.PutVarint(header[index:], int64(len(e.Key)))
// value size
index += binary.PutVarint(header[index:], int64(len(e.Value)))
// expireAt
index += binary.PutVarint(header[index:], e.ExpiredAt)
var size = index + len(e.Key) + len(e.Value)
buf := make([]byte, size)
copy(buf[:index], header[:])
// 写入 key value.
copy(buf[index:], e.Key)
copy(buf[index+len(e.Key):], e.Value)
// 对所有的数据进行 crc32 计算。
crc := crc32.ChecksumIEEE(buf[4:])
binary.LittleEndian.PutUint32(buf[:4], crc)
return buf, size
}func (db *RoseDB) updateIndexTree(idxTree *art.AdaptiveRadixTree,
ent *logfile.LogEntry, pos *valuePos, sendDiscard bool, dType DataType) error {
var size = pos.entrySize
if dType == String || dType == List {
// 如果是 string 和 list 则需要编码下。
_, size = logfile.EncodeEntry(ent)
}
// 构建索引的 node 节点对象, node 结构包含 value 在磁盘文件上的位置信息。
idxNode := &indexNode{fid: pos.fid, offset: pos.offset, entrySize: size}
// 如果是全内存模式, 则需要保存 value 值, KeyOnlyMemMode 则只需要存 value 的偏移量信息。
if db.opts.IndexMode == KeyValueMemMode {
idxNode.value = ent.Value
}
// 不为空则需要记录过期时间。
if ent.ExpiredAt != 0 {
idxNode.expiredAt = ent.ExpiredAt
}
// 把 key 和 index node 插入到 radix tree 索引里.
oldVal, updated := idxTree.Put(ent.Key, idxNode)
if sendDiscard {
// 通过 discard 记录删除值.
db.sendDiscard(oldVal, updated, dType)
}
return nil
}Get 为 rosedb 的读取数据的方法, 该方法跟 redis string get 一样的. 其内部流程是对 string 类型加锁, 然后从索引里获取 indexNode,如果是内存模式,则直接返回 value,如果是存储模式,则需要从 valuePos 里获取对应的 logfile 对象,然后通过 offset 和 size 拿到数据,再经过解码后返回给上层。
func (db *RoseDB) Get(key []byte) ([]byte, error) {
// 加锁, 前面有说在 rosedb 里每个 type 类型都有一个锁。
db.strIndex.mu.RLock()
defer db.strIndex.mu.RUnlock()
// get 的核心方法
return db.getVal(db.strIndex.idxTree, key, String)
}getVal 用来获取数据,其内部是先从 radixTree 索引里获取 indexNode,然后判断是否过期,当 kv 有配置过期且已过期,则直接返回 key 不存在的错误。 rosedb 为内存模式,则直接返回 node 的 value,否则需要从 logfile 里获取编解码后的 kv 数据返回给上层。
基于 bitcask 存储模型过期的处理都是后台处理的, 查询时只判断是否过期,清理过期数据则是由后台合并时处理, 其实基于 lsm tree 设计的 kv 引擎也是通过 compact 合并时处理过期键的.
func (db *RoseDB) getVal(idxTree *art.AdaptiveRadixTree,
key []byte, dataType DataType) ([]byte, error) {
// 先从索引里获取 node,如果没有索引则说明无数据.
rawValue := idxTree.Get(key)
if rawValue == nil {
return nil, ErrKeyNotFound
}
// interface 转换为 indexNode 对象.
idxNode, _ := rawValue.(*indexNode)
if idxNode == nil {
return nil, ErrKeyNotFound
}
// 判断是否过期,当kv有配置过期,且已过期,则直接返回 key 不存在的错误.
// 基于 bitcask 存储模型过期的处理都是后台处理的, 查询时只判断是否过期,清理过期数据则是由后台合并时处理, 其实基于 lsm tree 设计的 kv 引擎也是通过 compact 合并时处理过期键的.
ts := time.Now().Unix()
if idxNode.expiredAt != 0 && idxNode.expiredAt <= ts {
return nil, ErrKeyNotFound
}
// 如果是内存模式,则直接返回 node 的 value。
if db.opts.IndexMode == KeyValueMemMode && len(idxNode.value) != 0 {
return idxNode.value, nil
}
// 存储模式下的 value 只是存 valuePos,也就是磁盘文件的偏移量。
logFile := db.getActiveLogFile(dataType)
if logFile.Fid != idxNode.fid {
// 如果不一致,则从归档文件集合里获取 logfile 对象。
logFile = db.getArchivedLogFile(dataType, idxNode.fid)
}
if logFile == nil {
return nil, ErrLogFileNotFound
}
// 从 logfile 里获取编解码后的 kv 数据。
ent, _, err := logFile.ReadLogEntry(idxNode.offset)
if err != nil {
return nil, err
}
// 如果 entry type 为 delete 标记, 或者过期,则直接返回 key 不存在。
if ent.Type == logfile.TypeDelete || (ent.ExpiredAt != 0 && ent.ExpiredAt < ts) {
return nil, ErrKeyNotFound
}
return ent.Value, nil
}ReadLogEntry() 用来从文件里获取 kv entry 对象,其内部流程如下。
- 先从文件中获取 entry header,再通过 header 里的 keySize 和 valueSize 计算 size ;
- 通过 offset 和 size 拿到 key 和 value ;
- 判断 crc 是否一致 ;
- 返回 entry 对象.
rosedb 抽象了两种读写文件的方式,一种是 fileIO,另一种是 mmap 文件映射。从性能来说 mmap 要比 fileIO 高,mmap 减少了内核用户态之间的数据 copy,mmap 把文件映射到进程的地址空间上,对于应用程序来说就是个字节数组,这样在开发简单,无需 fileio 那种 readAt/writeAt 的读写,另外也方便构建缓存,因为对上层来说就是个字节数组。
文件位置: rosedb/logfile/log_file.go::ReadLogEntry()
func (lf *LogFile) ReadLogEntry(offset int64) (*LogEntry, int64, error) {
// 从文件中获取 header。
headerBuf, err := lf.readBytes(offset, MaxHeaderSize)
if err != nil {
return nil, 0, err
}
// 解码 []byte 为 header struct 对象.
header, size := decodeHeader(headerBuf)
if header.crc32 == 0 && header.kSize == 0 && header.vSize == 0 {
return nil, 0, ErrEndOfEntry
}
// 构建 entry 对象
e := &LogEntry{
ExpiredAt: header.expiredAt,
Type: header.typ,
}
kSize, vSize := int64(header.kSize), int64(header.vSize)
// 通过 ksize 和 vsize 计算 entrySize
var entrySize = size + kSize + vSize
// read entry key and value.
if kSize > 0 || vSize > 0 {
// 获取 key value
kvBuf, err := lf.readBytes(offset+size, kSize+vSize)
if err != nil {
return nil, 0, err
}
e.Key = kvBuf[:kSize]
e.Value = kvBuf[kSize:]
}
// 计算并判断 crc 校验码
if crc := getEntryCrc(e, headerBuf[crc32.Size:size]); crc != header.crc32 {
return nil, 0, ErrInvalidCrc
}
return e, entrySize, nil
}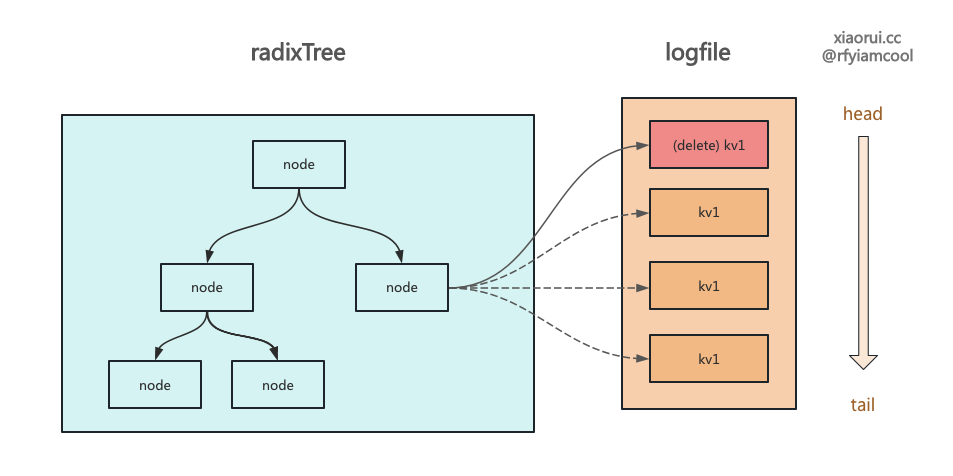
Delete 是 rosedb string 的删除方法,其逻辑很简单就两步,第一在 logfile 里写入带 Delete 标记的 entry,接着在 radixIndex 索引删删除这个 key。
当后面来 Get 请求时,如果索引中没找到已被标记删除的 key,则直接返回没找到 Key。 删除操作还会写入一个带 Delete 标记的 kv, 这是为了 rosedb 在启动阶段需要构建索引,这时候需要过滤掉被删除的 key 所设计的。
比如 activeLogFile 有一个删除标记 k1, 而归档的 logFile 也有 k1, 按照时间优先级,activeLogFile 的优先级更高。
还有值得一说的是 bitcask 和 lsm tree 一样,任何的写操作都是 append 追加一条日志。
// Delete value at the given key.
func (db *RoseDB) Delete(key []byte) error {
// 加锁
db.strIndex.mu.Lock()
defer db.strIndex.mu.Unlock()
// 写入一个删除标记
entry := &logfile.LogEntry{Key: key, Type: logfile.TypeDelete}
pos, err := db.writeLogEntry(entry, String)
if err != nil {
return err
}
// 在 radixTree 索引中删除
val, updated := db.strIndex.idxTree.Delete(key)
db.sendDiscard(val, updated, String)
_, size := logfile.EncodeEntry(entry)
node := &indexNode{fid: pos.fid, entrySize: size}
select {
case db.discards[String].valChan <- node:
// 通知 discard
default:
}
return nil
}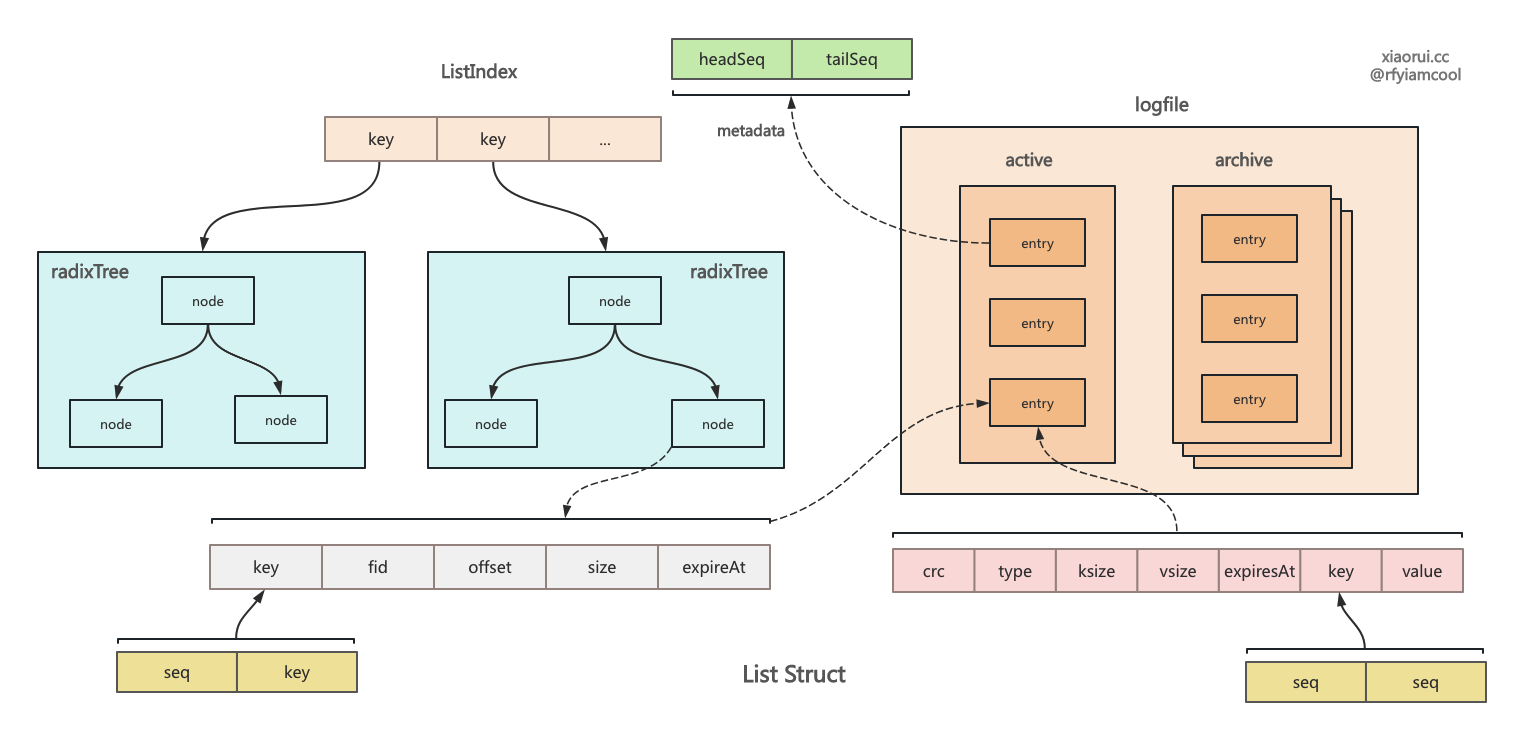
rosedb 的 list 跟 redis list 使用方法是一致的,rosedb 本质是个 kv 引擎,如何构建 list 列表结构 ? rosedb list 结构设计不复杂,首先为每个 list key 关联一个 metadata 元数据,元数据其实就两个字段一个是头部和尾部序号。默认序号为 uint32 最大值的中间值,当使用 Rpush 插入时,尾部需要加一,使用 Lpop 消费数据时,则在头部加一。 seq 是严格单调递增的。
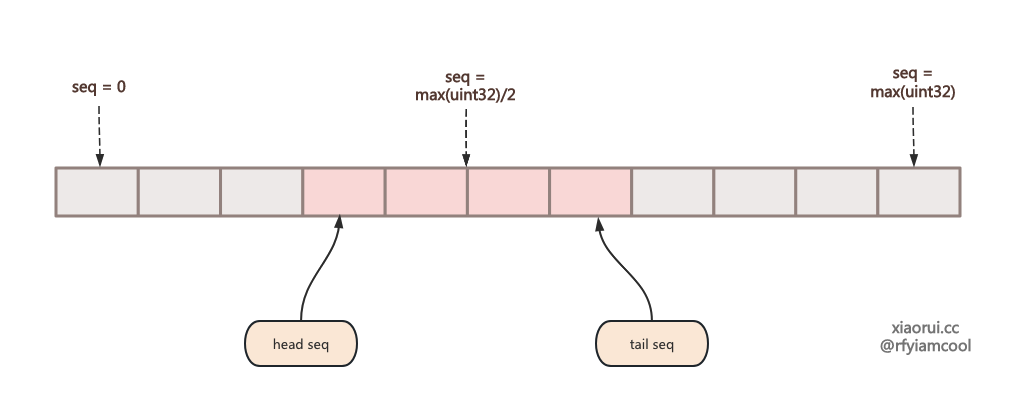
rosedb 为每个 list key 实例化了 radixTree 基数树索引,索引对象里存了所有的 list entry。写入的时候先要先把 entry 写入到 logfile 里,然后使用 valuePos 和 key 构建 indexNode,插入到 radixTree 索引里。查询自然是先从索引获取 key 对应的 valuePos,然后根据文件信息从 logfile 获取数据即可。
rosedb list 有几个问题,由于使用单调递增的 seq,无法实现 index 插入逻辑,如果选用 float 则可以不断中间插入。另外由于 rosedb list 的 seq 是 max(uint32)/2 值,当 list 一直有读写,tail seq 移动到最大值后, 再写入就出现了回绕,也就是说 head seq 比 tail seq 大,rosedb 没有处理回绕的逻辑。其实使用 int64 可避免这个问题,不外乎相比 uint32 用了 8 个字节。 当 list 为空时,rosedb 会删掉 list 的 metadata 元数据。但如果迟迟不触发空 list,那么还是会触发回绕的问题。
当然就 rosedb 场景来说,这个问题其实多虑的。bitcask 本就不适合量大的场景,比如启动时需要扫描所有盘,还需要在内存中构建全量索引,概率上 list value 是乱序存储的,需使用随机 IO 读取数据,这对于磁盘也是个考验。
func (db *RoseDB) RPush(key []byte, values ...[]byte) error {
// 加锁
db.listIndex.mu.Lock()
defer db.listIndex.mu.Unlock()
// 找到 list key 在索引里的 radixTree 基数结构
if db.listIndex.trees[string(key)] == nil {
db.listIndex.trees[string(key)] = art.NewART()
}
// 遍历 values 对象插入到 radixTree 基数索引里
for _, val := range values {
if err := db.pushInternal(key, val, false); err != nil {
return err
}
}
return nil
}pushInternal 方法用来把数据写到 logfile 里,然后把 entry 插入到 radixTree 索引里。 每个 list key 都有一个独的 radixTree 基数索引对象,另外每个 list key 还对应一个 metadata 元数据对象,metadata 对象保存了 head 和 tail 序号。 保存在 logfile 里的 key 后 4 个字节为 seq 序号。
其实在 radixTree 索引里无需保存 key 键,只需要存 seq 就可以满足增删改查需求。
func (db *RoseDB) pushInternal(key []byte, val []byte, isLeft bool) error {
// 获取 key 关联的 radix tree 索引对象
idxTree := db.listIndex.trees[string(key)]
// 从 kv 里获取 list key 的元数据, 头和尾部序号。
headSeq, tailSeq, err := db.listMeta(idxTree, key)
if err != nil {
return err
}
var seq = headSeq
// 调整位置
if !isLeft {
seq = tailSeq
}
// 编码 key 和 序号生成新的 key
encKey := db.encodeListKey(key, seq)
// 构建 entry 对象, 这里的 key 使用附带 seq 序号的 key
ent := &logfile.LogEntry{Key: encKey, Value: val}
// 把 entry 写到 logfile 里并得到 valuePos 对象信息
valuePos, err := db.writeLogEntry(ent, List)
if err != nil {
return err
}
// 更新索引, 类型标记为 List
if err = db.updateIndexTree(idxTree, ent, valuePos, true, List); err != nil {
return err
}
// 移动序号
if isLeft {
headSeq--
} else {
tailSeq++
}
// 保存该 list key 的头尾序号
err = db.saveListMeta(idxTree, key, headSeq, tailSeq)
return err
}使用 key 键和 seq 序号组成一个写入的 key,也就是前 4 个字节为 seq 序号。
func (db *RoseDB) encodeListKey(key []byte, seq uint32) []byte {
buf := make([]byte, len(key)+4)
binary.LittleEndian.PutUint32(buf[:4], seq)
copy(buf[4:], key[:])
return buf
}saveListMeta 用来更新 list key 的元数据,使用 headseq 和 tailseq 构建元数据的 value 值,然后写到 logfile 里,最后在索引缓存里也更新该元数据。
func (db *RoseDB) saveListMeta(idxTree *art.AdaptiveRadixTree, key []byte, headSeq, tailSeq uint32) error {
// 前 4 个字节为 head 序号,后4个字节为 tail 序号.
buf := make([]byte, 8)
binary.LittleEndian.PutUint32(buf[:4], headSeq)
binary.LittleEndian.PutUint32(buf[4:8], tailSeq)
// 这里的 value 为 headseq 和 tailseq 序号.
ent := &logfile.LogEntry{Key: key, Value: buf, Type: logfile.TypeListMeta}
// 把 list key 的元数据写到日志里.
pos, err := db.writeLogEntry(ent, List)
if err != nil {
return err
}
// 在内存缓存里更新 list key 的 metadata 索引.
err = db.updateIndexTree(idxTree, ent, pos, true, List)
return err
}rosedb 的 Rpop 和 Lpop 是用来从头部获取并删除元素的方法, Rpop 是从右面删除,而 Lpop 是从左面删除。
// LPop removes and returns the first elements of the list stored at key.
func (db *RoseDB) LPop(key []byte) ([]byte, error) {
// 加锁
db.listIndex.mu.Lock()
defer db.listIndex.mu.Unlock()
// 获取值
return db.popInternal(key, true)
}popInternal 用来获取头部元素并删除该元素。其实现流程如下。
- 先获取 list key 相关的 radeixTree 索引对象 ;
- 从索引里获取 key 相关的元数据, 主要就两个字段 headseq 和 tailseq ;
- 编码生成一个含有 seq 的 key, 然后从 index 和 logfile 里获取该 key 的数据 ;
- 数据既然已经获取,那么就需要标记删除,在 logfile 写入一个带 delete 标记的 entry ;
- 在索引中删除该 entry ;
- 移动 head 和 tail 序号后,更新保存 list key 元数据 ;
- 如果 list key 元素的长度已经为空, 则直接干掉该 list key 对象的 radix index 索引对象.
func (db *RoseDB) popInternal(key []byte, isLeft bool) ([]byte, error) {
if db.listIndex.trees[string(key)] == nil {
return nil, nil
}
// 获取 list key 相关的 radeixTree 索引树.
idxTree := db.listIndex.trees[string(key)]
// 从索引里获取 key 相关的元数据, 主要就两个字段 headseq 和 tailseq.
headSeq, tailSeq, err := db.listMeta(idxTree, key)
if err != nil {
return nil, err
}
// 如果一致说明无数据,直接报空.
if tailSeq-headSeq-1 <= 0 {
return nil, nil
}
// 移动位置
var seq = headSeq + 1
if !isLeft {
seq = tailSeq - 1
}
// 编码 key 和 seq 为新 key
encKey := db.encodeListKey(key, seq)
// 先从索引里获取 valuePos,然后再从对应的 logfile 里获取 value.
val, err := db.getVal(idxTree, encKey, List)
if err != nil {
return nil, err
}
// 数据既然拿到了,就需要执行该 entry,删除逻辑就是写一条删除日志。
ent := &logfile.LogEntry{Key: encKey, Type: logfile.TypeDelete}
pos, err := db.writeLogEntry(ent, List)
if err != nil {
return nil, err
}
// 在内存索引里删除相关的 key
oldVal, updated := idxTree.Delete(encKey)
// 移动序号
if isLeft {
headSeq++
} else {
tailSeq--
}
// 保存该 list key 的 metadata 元数据。
if err = db.saveListMeta(idxTree, key, headSeq, tailSeq); err != nil {
return nil, err
}
// 触发 discard 逻辑
db.sendDiscard(oldVal, updated, List)
_, entrySize := logfile.EncodeEntry(ent)
node := &indexNode{fid: pos.fid, entrySize: entrySize}
select {
case db.discards[List].valChan <- node:
default:
logger.Warn("send to discard chan fail")
}
if tailSeq-headSeq-1 == 0 {
// 如果为空则需要重置 metadata
if headSeq != initialListSeq || tailSeq != initialListSeq+1 {
headSeq = initialListSeq
tailSeq = initialListSeq + 1
_ = db.saveListMeta(idxTree, key, headSeq, tailSeq)
}
// 删除该 list key 的 radixTree 索引树
delete(db.listIndex.trees, string(key))
}
return val, nil
}Lrange 可以获取两个 index 索引位置之间的所有数据。获取 list key 对应的 metadata 元数据, 然后通过 metadata 的 seq 序号计算出 start 和 end 相对索引位置对应的 seq 序号,只需要对两个 seq 进行遍历获取即可。
func (db *RoseDB) LRange(key []byte, start, end int) (values [][]byte, err error) {
// 加锁
db.listIndex.mu.RLock()
defer db.listIndex.mu.RUnlock()
// 判空
if db.listIndex.trees[string(key)] == nil {
return nil, ErrKeyNotFound
}
// 通过 list key 获取对应的 index Tree 对象。
idxTree := db.listIndex.trees[string(key)]
// 获取 list key 的 metadata 元数据。
headSeq, tailSeq, err := db.listMeta(idxTree, key)
if err != nil {
return nil, err
}
var startSeq, endSeq uint32
// 计算获取 start index 对应的 seq 序号
startSeq, err = db.listSequence(headSeq, tailSeq, start)
if err != nil {
return nil, err
}
// 计算获取 end index 对应的 seq 序号
endSeq, err = db.listSequence(headSeq, tailSeq, end)
if err != nil {
return nil, err
}
// 移动位置
if startSeq <= headSeq {
startSeq = headSeq + 1
}
if endSeq >= tailSeq {
endSeq = tailSeq - 1
}
// 非法 index 索引号
if startSeq >= tailSeq || endSeq <= headSeq || startSeq > endSeq {
return nil, ErrWrongIndex
}
// 按照 seq 序号遍历获取数据,并 append 到 values 集合里.
for seq := startSeq; seq < endSeq+1; seq++ {
// 把 key 和 seq 拼装组成 enckey.
encKey := db.encodeListKey(key, seq)
// 从 logfile 里获取 enckey 的数据.
val, err := db.getVal(idxTree, encKey, List)
if err != nil {
return nil, err
}
// 追加到 values 集合里.
values = append(values, val)
}
// 返回集合
return values, nil
}通过分析 rosedb 源码中 string 和 list 结构的实现原理, 可以发现 rosedb 中一些巧妙的设计.
- 不同的数据类型存到不同的 logfile 里 ;
- 不同的数据类型都有自己的索引。 string 类型是共用一个 radixTree 索引,而 list 列表结构有些差异,每个 list key 都有一个独立的 radeixTree 索引 ;
- 所有的写操作都是构建一个 entry 写到活跃的 logfile 里,删除操作则多带一个 delete 删除标记,然后也 entry 写到 logfile 日志文件里 ;
- 内存的索引是通过
radixTree基数树来构建的,index node 只保存 key 和 valuePos,valuePos 记录了 value 在磁盘中的位置,主要记录了文件id和偏移量。
下面是 rosedb 里 string 和 list 结构的布局
rosedb 里 string 结构的设计
rosedb 里 list 列表结构的设计