该系统属于长连接消息推送业务,某节假日推送消息的流量突增几倍,顺时出现比平日多出几倍的消息量等待下推。事后,发现生产消息的业务服务端因为某 bug ,把大量消息堆积在内存里,在一段时间后,突发性的发送大量消息到推送系统。但由于流量保护器的上限较高,当前未触发熔断和限流,所以消息依然进行流转。消息系统不能简单的进行削峰填谷式的排队处理,因为很容易造成消息的耗时长尾,所以在不触发流量保护器的前提下,需要进行的并发并行的去流转消息。
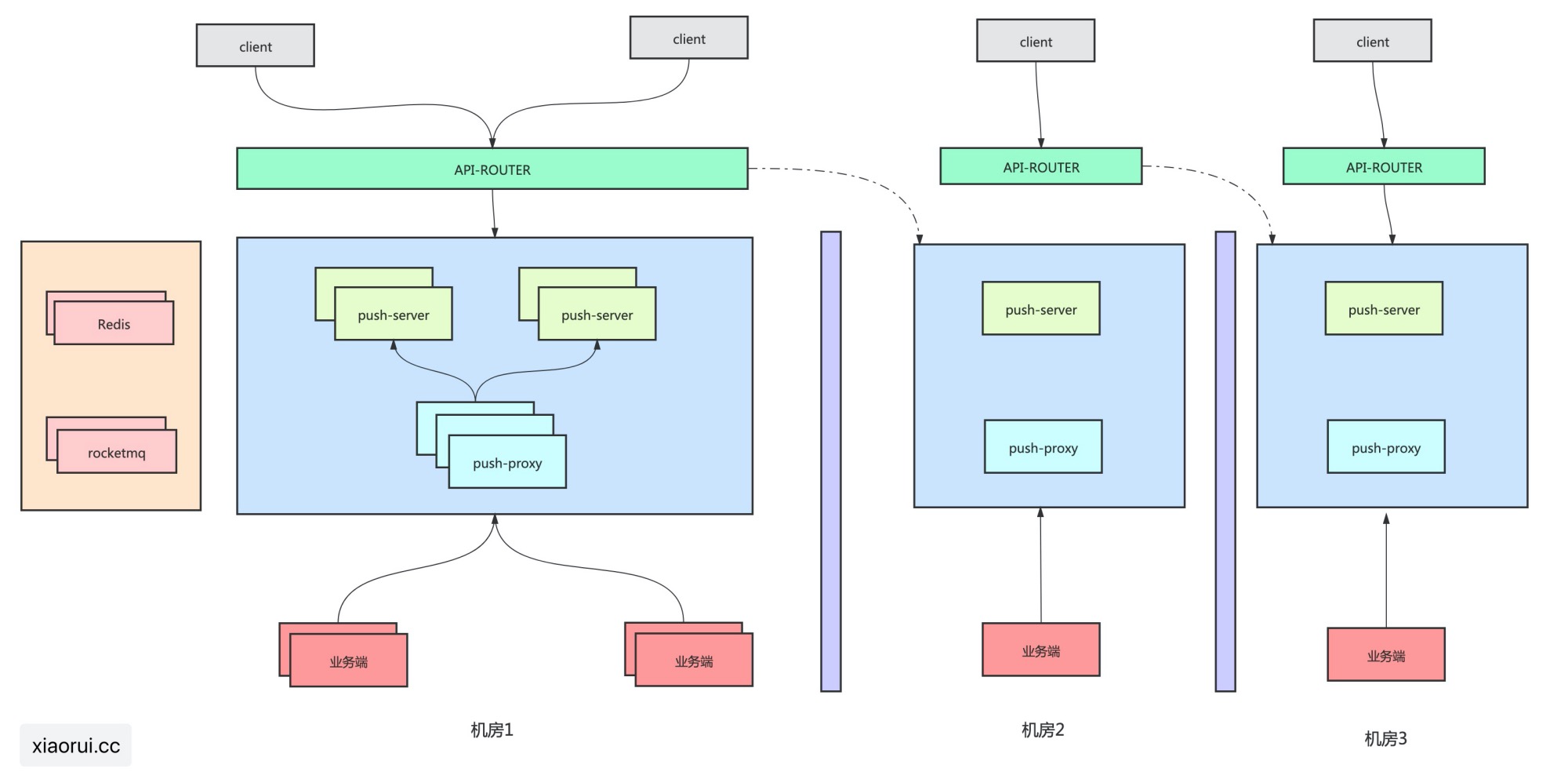
下图是我司长连接消息推送系统的简单架构图,出问题就是处在下游的消息生产方业务端。
其实更重要的因为是前些日子公司做成本优化,把一个可用区里的一波机器从物理机迁移到阿里云内,机器的配置也做了阉割。突然想起 曹春晖大佬 的一句话,没钱做优化,有钱加机器。
这样两个问题加起来,导致消息时延从 < 100ms 干到 < 3s 左右,通过监控看到高时延问题最少 10 来分钟。
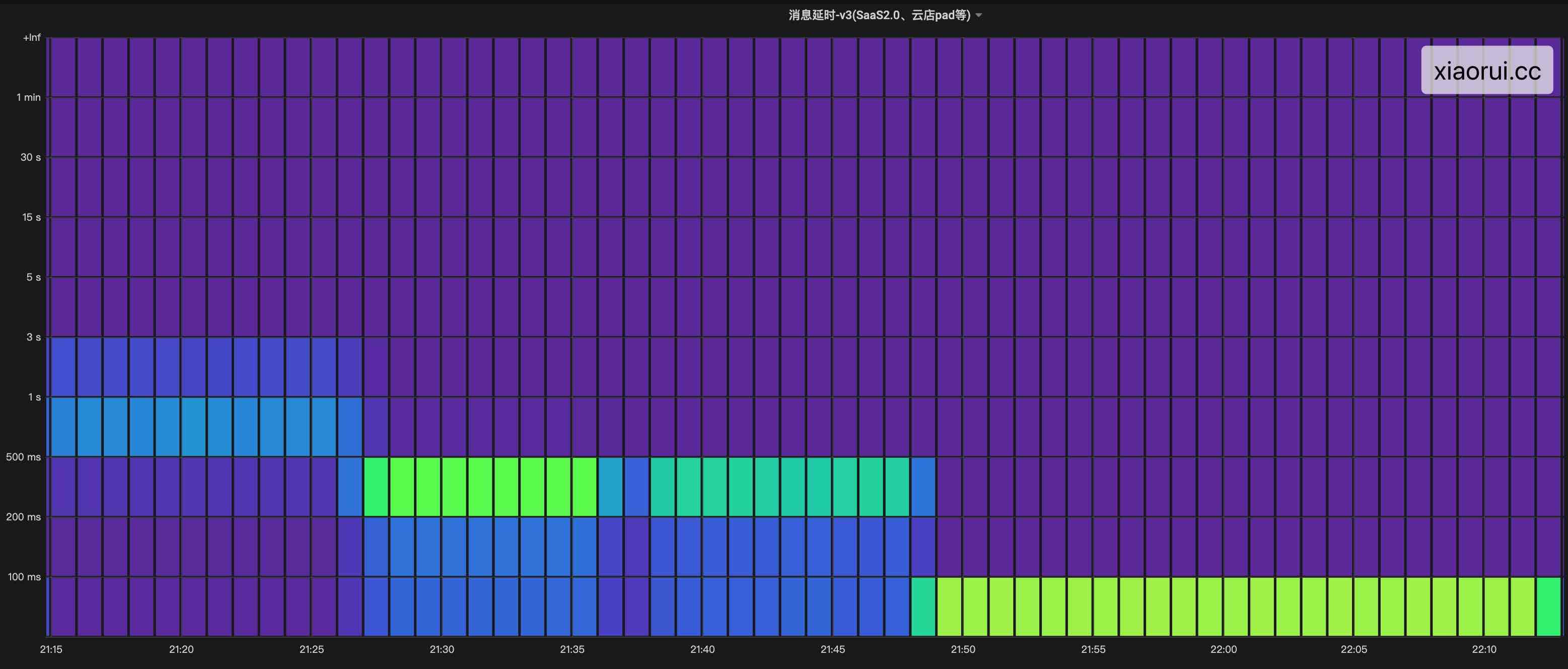
造成消息推送的时延飙高,通常来说有几种情况,要么cpu有负载?要么 redis 时延高?要么消费rocketmq 慢?或者哪个关键函数处理慢 ?
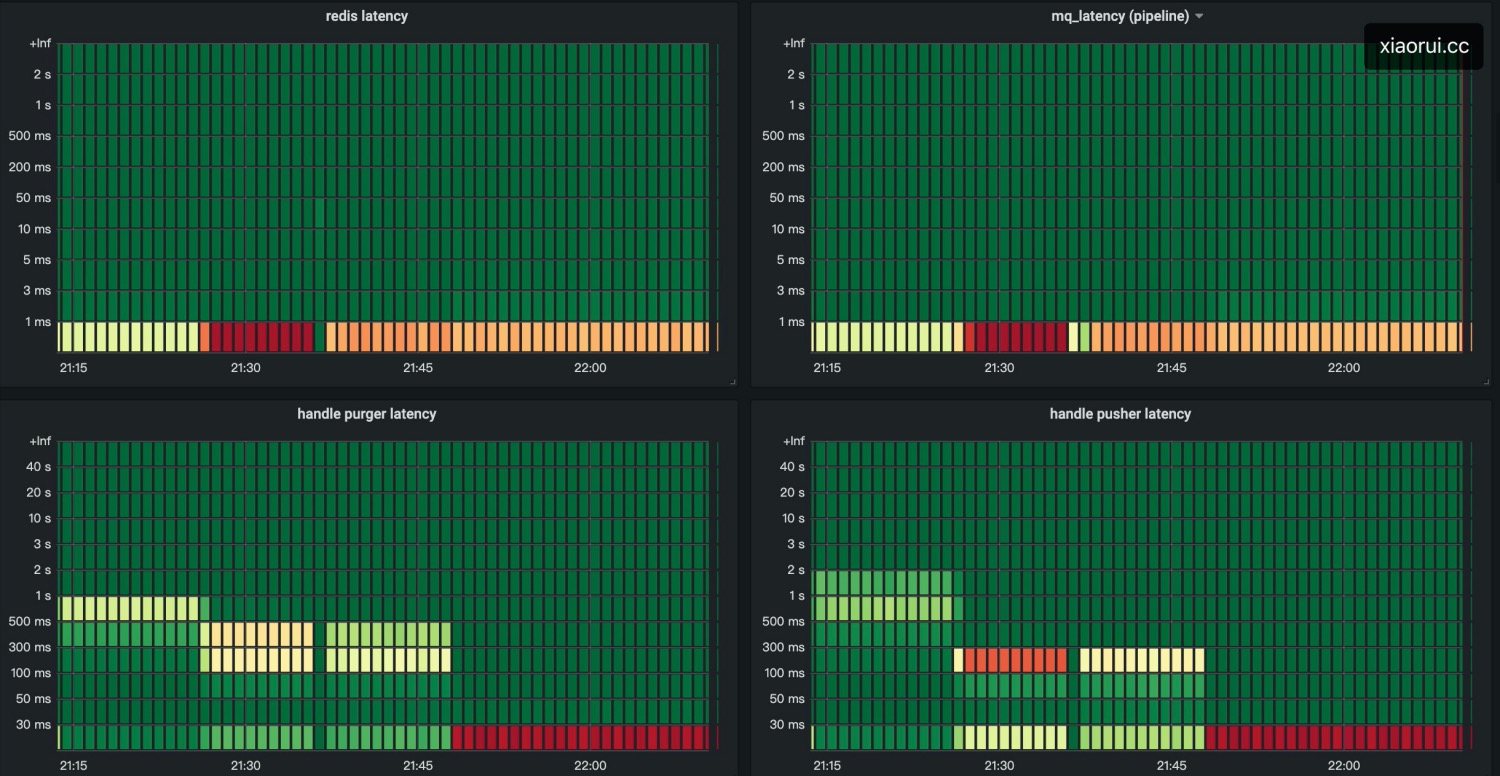
通过监控图表得知,load正常,且网络io方面都不慢,但两个关键函数都发生了处理延迟的现象,该两函数内处理redis和mq的网络io操作外,基本是纯业务组合的逻辑,讲道理不会慢成这个德行。
询问基础运维的同学得知,当时该几个主机出现了磁盘 iops 剧烈抖动, iowait 也随之飙高。但问题来了,大家都知道通常来说linux下的读写都有使用 buffer io,写数据是先写到 page buffer 里,然后由内核的 kworker/flush 线程 dirty pages 刷入磁盘,但当脏写率超过阈值 dirty_ratio 时,业务中的write会被堵塞住,被动触发进行同步刷盘。
推送系统的日志已经是INFO级别了,虽然日志经过特殊编码,空间看似很小,但消息的流程依旧复杂,不能不记录,每次扯皮的时候都依赖这些链路日志来甩锅。
阿里云主机普通云盘的 io 性能差强人意,以前在物理机部署时,真没出现这问题。😅
通过监控的趋势可分析出,随着消息的突增造成的抖动,我们只需要解决抖动就好了。上面有说,虽然是buffer io写日志,但随着大量脏数据的产生,来不及刷盘还是会阻塞 write 调用的。
解决方法很简单,异步写不就行了 !!!
- 实例化一个
ringbuffer结构,该ringbuffer的本质就是一个环形的 []byte 数组,可使用Lock Free提高读写性能; - 为了避免 OOM, 需要限定最大的字节数;为了调和空间利用率及性能,支持扩缩容;缩容不要太频繁,可设定一个空闲时间;
- 抽象 log 的写接口,把待写入的数据塞入到ringbuffer里;
- 启动一个协程去消费
ringbuffer的数据,写入到日志文件里;- 当 ringbuffer 为空时,进行休眠百个毫秒;
- 当 ringbuffer 满了时,直接覆盖写入。
这个靠谱么? 我以前做分布式行情推送系统也是异步写日志,据我所知,像 WhatsApp、腾讯QQ和广发证券也是异步写日志。对于低延迟的服务来说,disk io造成的时延也是很恐怖的。
覆盖日志,被覆盖的日志呢? 异步写日志,那Crash了呢? 首先线上我们会预设最大 ringbuffer 为200MB,200MB足够支撑长时间的日志的缓冲。如果缓冲区满了,说明这期间并发量着实太大,覆盖就覆盖了,毕竟 系统稳定性和保留日志,你要哪个 ?
Crash造成异步日志丢失?针对日志做个metrics,超过一定的阈值才进行开启异步日志。但我采用的是跟广发证券一样的策略,不管不顾,丢了就丢了。如果正常关闭,退出前可优雅可选择性阻塞日志缓冲刷新完毕。如果Crash情况,丢了就丢了,因为golang的panic会打印到stderr。
另外 Golang 的 垃圾回收器GC 对于 ringbuffer 这类整块 []byte结构来说,扫描很是友好。Ringbuffer开到 1G 进行测试,GC的 Latency 指标趋势无异常。
至于异步日志的 golang 代码,我暂时不分享给大家了,不是因为多抠门,而是因为公司内部的 log 库耦合了一些东西,真心懒得抽离。但异步日志的实现思路就是这么一回事。
如有全量详细日志的打印需求,建议分两组 ringbuffer 缓冲区,一个用作 debug 输出,一个用作其他 level 的输出,好处在于互不影响。还有就是做好缓冲区的监控。
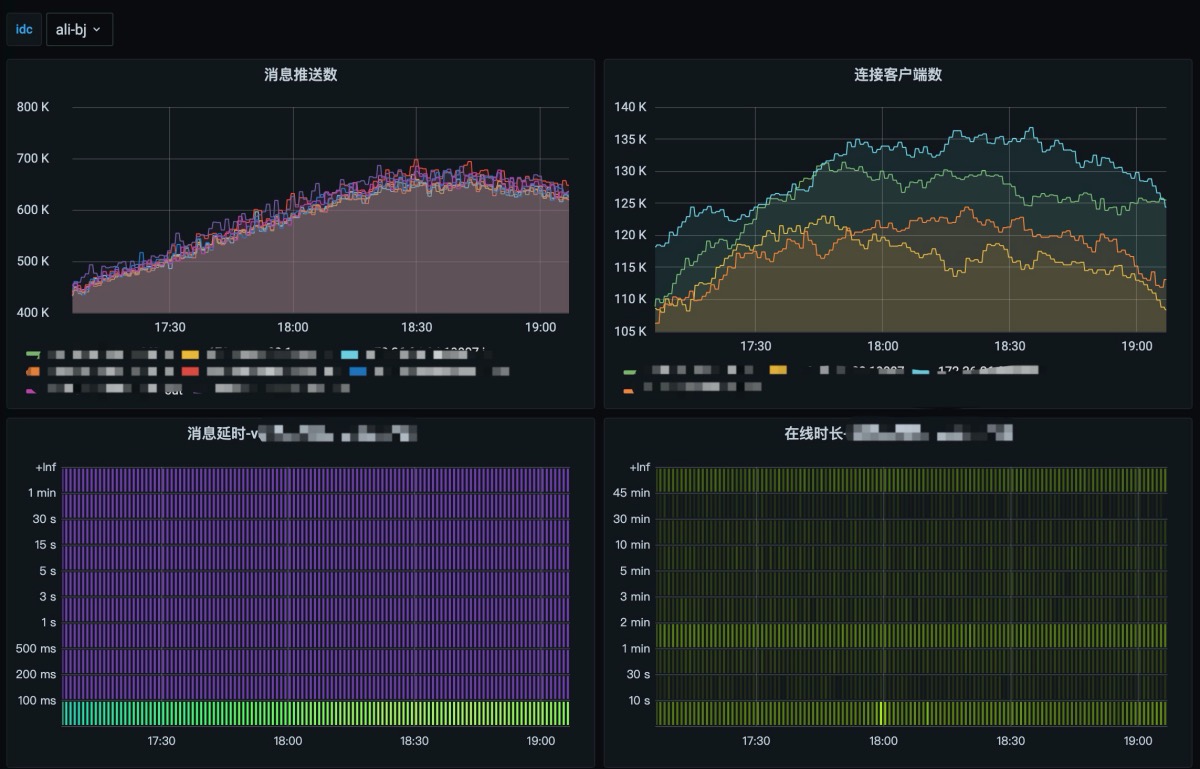
下面是我们集群中的北京阿里云可用区集群,高峰期消息的推送量不低,但消息的延迟稳定在 100ms 以内。