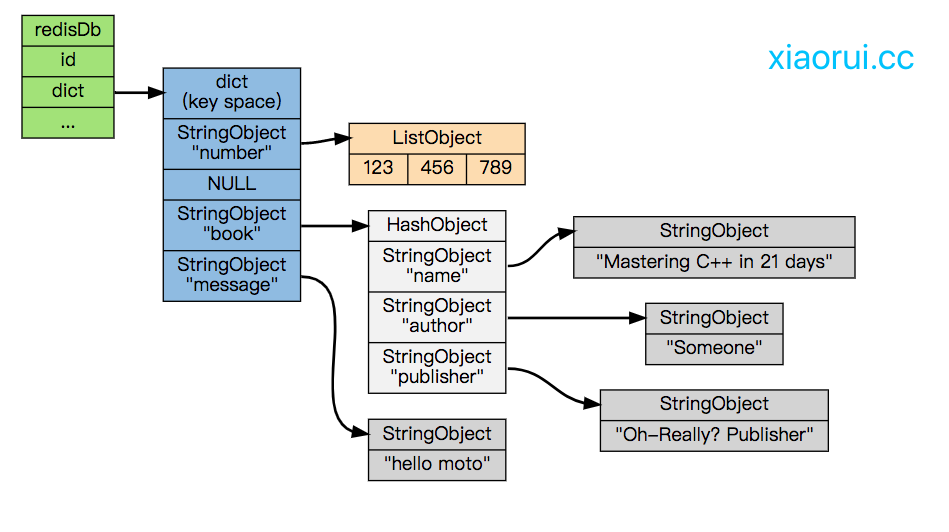
千万级别的key value在redis里怎么存才合适? 我们知道redis的最上层的db里维护了dict, 如果我们直接跑set key value命令,那么dict会存你的key及value对象,包括操作都会存在redisdb的dict里。数据结构如下。
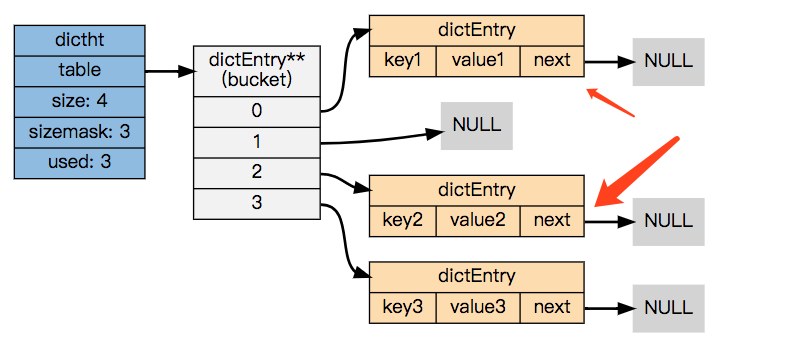
redis的 quicklist, hashmap在数据量小于配置的阈值时,使用ziplist来存储数据。为什么会使用ziplist, ziplist采用了一段连续的内存来存储数据。相比hashtable减少了内存碎片和指针的内存占用。这里说的指针空间占用主要是说,在hashmap产生冲突后,dictEntry使用next字段来连接下一个entry。
redis hash 内存
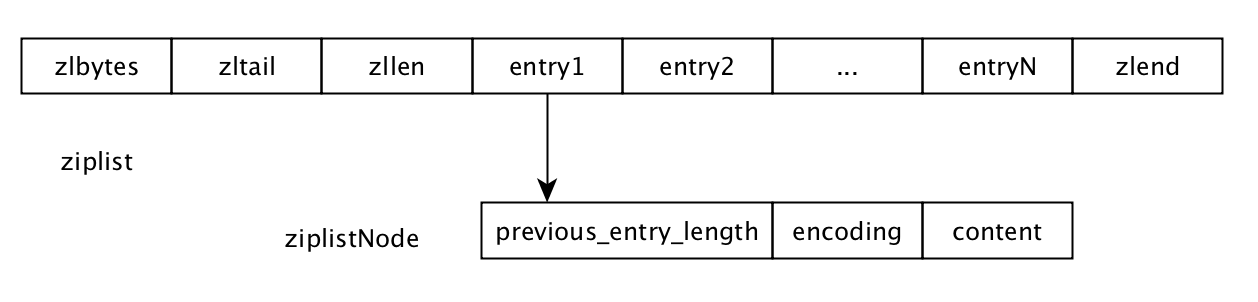
我们在来分析下ziplist结构的字段构成,zlbytes 是 ziplist 占用的空间,zltail 是最后一个数据项的偏移位置,这方便逆向遍历链表,zllen 是数据项entry 的个数,zlend是ziplist的结尾符,entry就是存放kv数据的。entry又包含了三个字段,分别是前一个entry的size, 编码及数据。 ziplist是个线性数据结构,各个字段凑在一起。
如何使用ziplist? 我们知道redis hashmap初始阶段就是ziplist, 只要不超过max-ziplist-value和ziplist-entries就不会进化到hashmap。那么我们就可以利用这个特性,把几千万的kv分片到一堆的hashmap里。公式是 kv/hash-ziplist-entries = 分片数,但是我们要考虑hash算法带来的倾斜问题,可以使用murmur32 hash算法,再适当的调大分片数的方式减少kv倾斜进化hash map.
下面使用python脚本往redis里灌数据,来对比有无使用ziplist的内存使用情况。使用ziplist只用了500m左右,hash dict占用1.5g的内存,ziplist确实省内存。
// xiaorui.cc
import sys
import redis
import binascii
def normal():
n = 15000000
r = redis.Redis()
for i in range(n):
key = "hello_golang_" + str(i)
value = "nima_" + str(i)
r.set(key, value)
print(r.info()["used_memory_human"])
# mem 1.54G
def opt():
n = 15000000
r = redis.Redis()
for i in range(n):
key = "hello_golang_" + str(i)
value = "nima_" + str(i)
bucket_id = binascii.crc32(key.encode())%37500
r.hset(bucket_id, key, value)
print(r.info()["used_memory_human"])
# mem 536M
if __name__ == "__main__":
cmd = sys.argv[1]
if cmd == "opt":
opt()
if cmd == "normal":
normal()ziplist有缺点 ?通过他的数据结构设计就可以分析的出来,时间复杂度大。把ziplist-max-entries的值调大2048后,在客户端在并发请求时,redis cpu的百分比有上升的趋势,但内存确实节省了不少。 😅
这里简单说下ziplist的增删改查的过程,ziplist在删除某个entry时,会把该元素后面的entry往前面推,说白了就是copy。查找的时候,直接遍历。 插入的时候通常往后插入,但当空间不够了,再实例化一个大ziplist,把以前的entry copy过去。
redis的数据结构设计都很巧妙,值得去深度学习下。