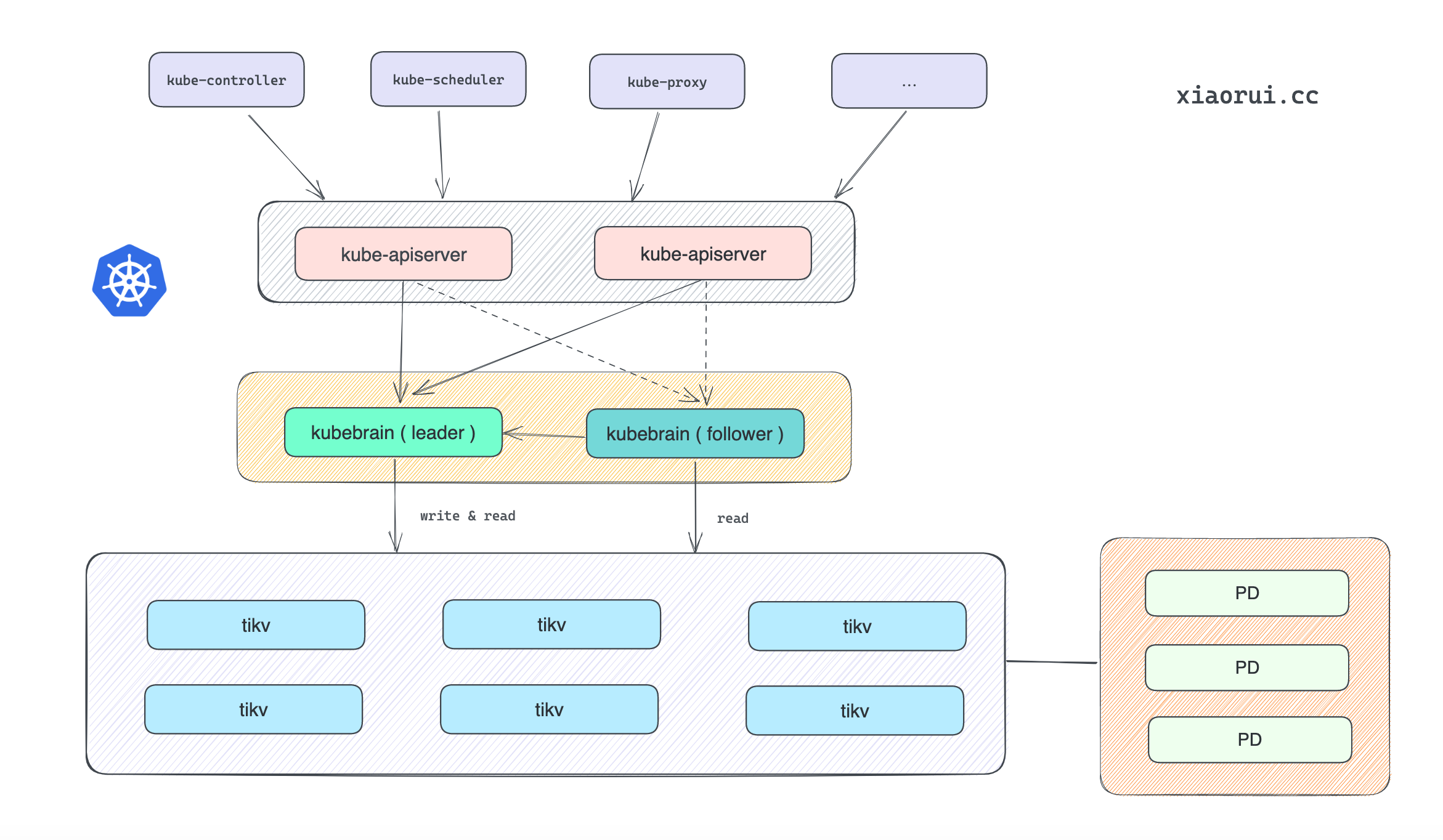
kubebrain 是头条开源的兼容 etcd 接口的 kubernetes 的元数据存储. 众所周知 k8s 元数据都是存在 etcd cluster 中, k8s 中的其他组件需要跟 apisrever 接口对接, 而 apiserver 则跟 etcd 对接, 所有的数据存储都在 etcd 中, 在超大集群下 etcd 带来的压力可想而知.
kubebrain 则去除了对 etcd 的依赖, 在架构可以上可以对接其他自定义分布式数据库. kubebrain 内部实现了 badgerdb 和 tikv 的存储结构. badgerdb 作为单机引擎适用于本地调试, 更推荐使用 tikv 作为数据存储引擎. 另外头条内部则使用 ByteKV 做 kubebrain 的数据存储引擎. ByteKV 未开源, 其架构跟 tikv 差不多. 头条有分享过 ByteKV 的实现原理, 有兴趣的朋友可以找下相关文章.
kubebrain github 地址
https://github.com/kubewharf/kubebrain
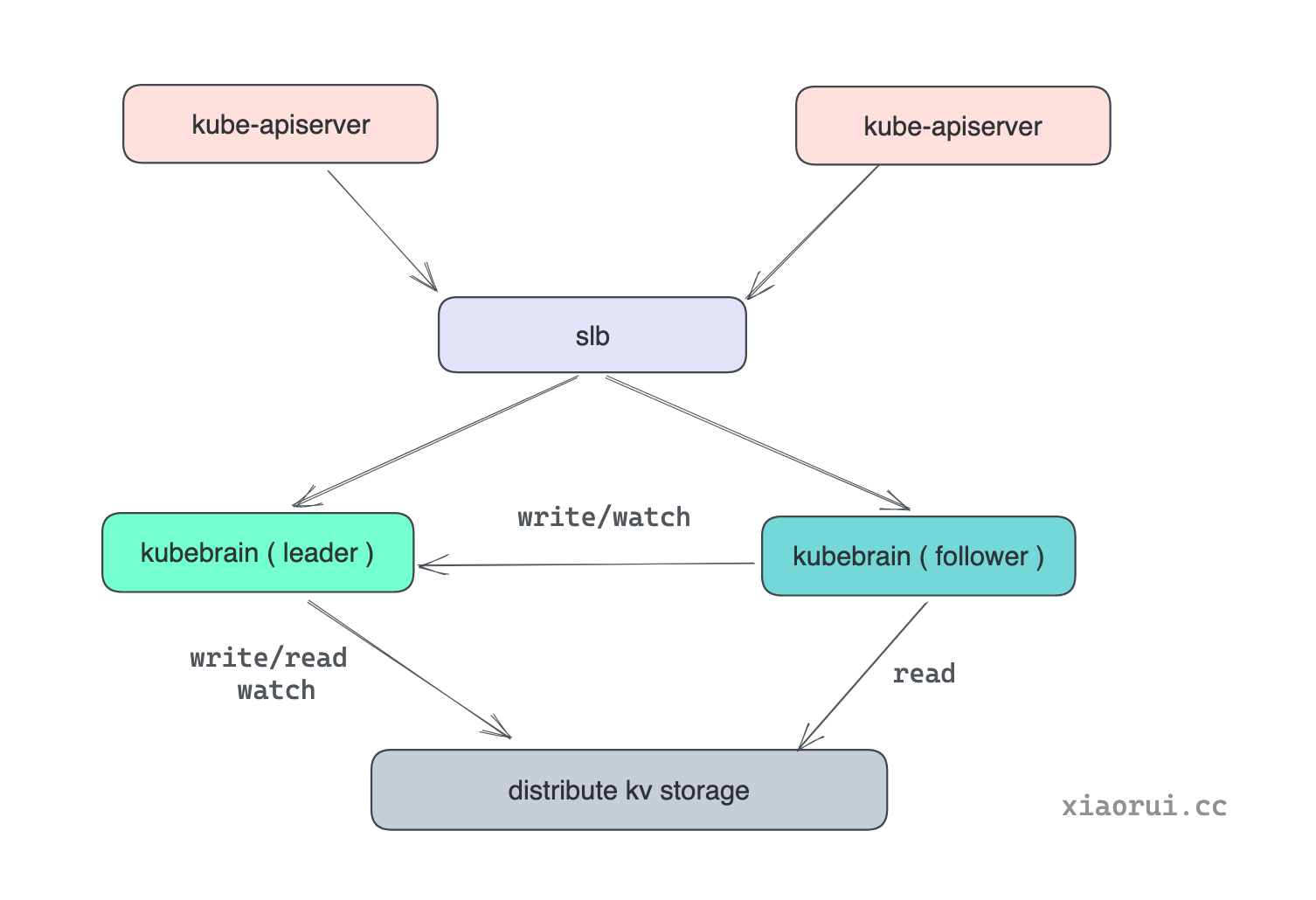
kubebrain 虽然是支持分布式横向扩展, 但它内部是分为主从节点的, 原理倒是没什么, 通过分布式锁进行选举, 拿到锁自然为 leader 主节点, 其他实例为 follower 从节点. 主节点可以承接读写请求, 而从节点可以处理读请求, 对于写 和 watch/lease 操作需要代理转发到 leader 节点去处理.
对于 k8s apiserver 来说, 访问任意 kubebrain 节点都可以. 访问主节点时可直接处理请求, 从节点会代理转发到主节点. 另外 kubebrain 在启动 grpc server 时, 注册了 leader 和 memberlist 相关的接口, 客户端可通过这两个接口进行合理调度, 避免每次访问从节点, 减少 follower 节点转发带来的 latency 延迟.
一句话, 当前 kubebrain 是单主架构, 写操作只能到 leader 节点操作, 使用 etcd sdk 对 kubebrain 请求时, kubebrain 发现自身不是 leader 节点时, 会把请求代理转发到 leader 节点上.
主要是为了解决多节点集群下 revision 版本号生成和 watch 增量订阅. 后面会分析发号器和 watch 的实现原理.
下面是 Txn 接口里转发逻辑的实现.
func (s *RPCServer) Txn(ctx context.Context, txn *etcdserverpb.TxnRequest) (*etcdserverpb.TxnResponse, error) {
...
if !s.peers.IsLeader() {
// 如果被访问的实例不是 leader, 且开启了转发开关, 则把请求转发到 leader 节点.
if s.peers.EtcdProxyEnabled() {
return s.peers.Txn(ctx, txn)
}
return nil, status.Errorf(codes.Unavailable, "txn error addr is %s leader %s", s.backend.GetResourceLock().Identity(), s.backend.GetResourceLock().Describe())
}
if put := isCreate(txn); put != nil {
response, err = s.backend.Create(ctx, put)
if err != nil || !response.Succeeded {
failedKey = string(put.Key)
}
} else if rev, key, ok := isDelete(txn); ok {
response, err = s.backend.Delete(ctx, key, rev)
methodTag = metrics.Tag("method", "delete")
if err != nil || !response.Succeeded {
failedKey = string(key)
}
} else if rev, key, value, lease, ok := isUpdate(txn); ok {
response, err = s.backend.Update(ctx, rev, key, value, lease)
methodTag = metrics.Tag("method", "update")
if err != nil || !response.Succeeded {
failedKey = string(key)
}
}
...
return response, err
}下面是 Watch 接口里转发逻辑的实现.
源码位置: pkg/server/etcd/watch.go
func (w *watcher) Watch(ctx context.Context, id int64, r *etcdserverpb.WatchCreateRequest) {
...
var ch <-chan []*mvccpb.Event
var err error
// 判断本实例是否是 leader 节点
if w.grpcServer.peers.IsLeader() {
// 直接调用 watch
ch, err = w.backend.Watch(ctx, string(r.Key), uint64(r.StartRevision))
} else {
// 转发 watch 请求到 leader 实例
ch, err = w.grpcServer.peers.Watch(ctx, string(r.Key), uint64(r.StartRevision))
}
...
for events := range ch {
if len(events) == 0 {
continue
}
watchResponse := &etcdserverpb.WatchResponse{
Header: &etcdserverpb.ResponseHeader{
Revision: events[len(events)-1].Kv.ModRevision,
},
WatchId: id,
Events: events,
}
if err := w.watchServer.Send(watchResponse); err != nil {
continue
}
}
}kubebrain 项目主要是为了解决 etcd 的在 k8s 大集群下存在性能问题. 按照头条的在文档中的表述, 在超过一定的节点数后 k8s 会出现性能问题. k8s 官方也给出建议最大节点数为 5000, 超过该范畴 k8s 不太能提供稳定的支撑.
k8s apiserver 服务由于无状态, 所以很容易就支持高可用和负载均衡的, 而 etcd 作为分布式数据库, 必然是有状态的. 虽然 etcd 由 raft 一致性协议构建了集群, 但 etcd 的设计是单 raft group 设计, 也就是说 etcd 没有分区的概念, 整个集群就只有一个 leader, 读写都在 leader 节点进行. 而 kubebrain 建议社区中使用的 pingcap tikv 做底层存储是支持 multi raft group 的, 极大的提高了读写能力. kubebrain 代码中抽象了存储接口, 可以根据需求自定义 kv 数据库. kubebrain 内置了 badgerdb 和 tikv 的调用, 而头条内部则使用 ByteKV 做 kubebrain 的存储引擎, 头条有分享过 ByteKV 的实现原理, 有兴趣的朋友可以找下相关文章.
另外 etcd 底层的存储引擎是 boltdb, 这玩意是写操作是串行的, 并发写的性能差点意思. etcd 是存在碎片的, 所以需要定期执行碎片回收, 但是该操作是存在性能开销的, 这根 defrag 的逻辑有关系. 当 etcd 重启时需要扫描整个 boltdb 存储文件, 然后在内存里构建索引 treeIndex, 索引的 key 为 name, 而 value 为 revison. 因为这个问题, 当 etcd 数据达到一定量级后, 不仅启动恢复的操作会很长, 而且也需要花费内存构建完整的 treeIndex 索引树.
正是由于在量级下 etcd 有上面这些个问题, 所以头条使用 kubebrain 元数据存储来解决 etcd 的性能问题. 其实阿里内部也有尝试使用 oceanbase 替换 boltdb 存储引擎, etcd servre 只是用来做请求代理, 真正的数据是存放在 oceanbase 分布式数据库里的.
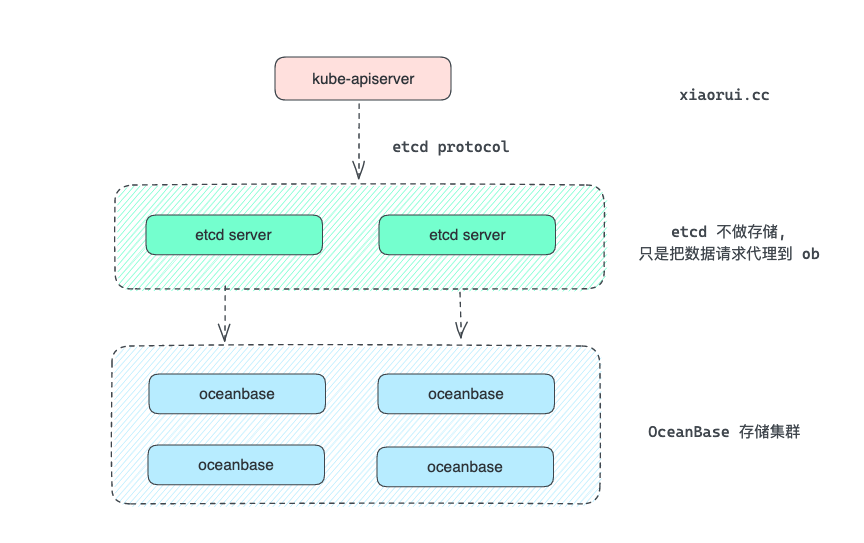
如果对 etcd 的实现原理有兴趣, 可以阅读以前写过的技术分享.
编码的设计

在 kv 存储引擎里, kubebrain 的 key 的编码方式为 magic+raw_key+split_key+revision.
- magic 为
\x57\xfb\x80\x8b - raw_key 为实际 apiserver 输入到存储系统中的 key
- split_key 为
$ - revision 为逻辑时钟对写操作分配的逻辑操作序号通过BigEndian编码成的Bytes
记录关联 rawkey 的各个 revison 版本值, 另外通过 0 占位符指向最新的 reviosn.
{magic}:{raw_key}:{split_key}:0 -> revision{magic}:{raw_key}:{split_key}:{revision} -> value
代码位置: pkg/backend/coder/normal.go
boltdb 的 key 只是 revison 版本号, 而 value 则是 mvccpb.KeyValue 结构体, 字段含有真正的 key、 value 及其他属性.
正是因为所有的 key 只是 revison 的设计, 导致 etcd 在启动时需要把 kv 都读取出来, 然后构建 treeIndex 索引, treeIndex 的 key 为用户数据的 key, 而 value 为 revision.
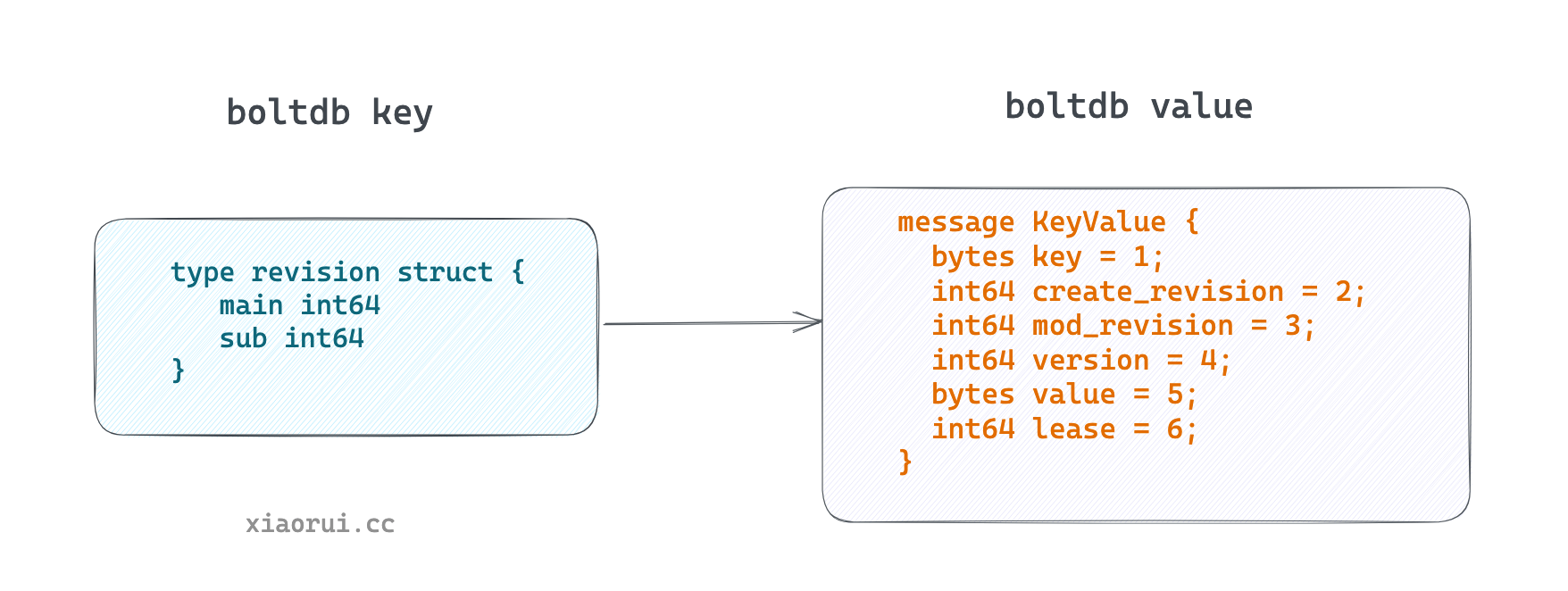
kubebrain 的存储排列方式更加好理解, 其 key 是由 raw_key + revison 构成, 而 value 则是 raw_value. 通过存储引擎的 iter 迭代器可扫描出该 key 所有的 revison 变更记录.
// EncodeObjectKey implements Coder interface
func (n *normalEncoderDecoder) EncodeObjectKey(userKey []byte, revision uint64) []byte {
key := make([]byte, len(magicBytes)+len(userKey)+1+8)
// {magic}:{raw_key}:{split_key}:{revision}
copy(key, magicBytes)
copy(key[len(magicBytes):], userKey)
copy(key[len(magicBytes)+len(userKey):], splitKey)
binary.BigEndian.PutUint64(key[len(magicBytes)+len(userKey)+1:], revision)
return key
}
// EncodeRevisionKey implements Coder interface
func (n *normalEncoderDecoder) EncodeRevisionKey(key []byte) []byte {
return n.EncodeObjectKey(key, 0)
}
// Decode implements Coder interface
func (n *normalEncoderDecoder) Decode(internalKey []byte) (userKey []byte, revision uint64, err error) {
if !bytes.Equal(internalKey[:len(magicBytes)], magicBytes) {
return nil, 0, errors.Errorf("magic number not right for object key %v", hex.EncodeToString(internalKey))
}
if internalKey[len(internalKey)-9] != splitByte {
return nil, 0, errors.Errorf("split byte not right for object key %v", hex.EncodeToString(internalKey))
}
revision = binary.BigEndian.Uint64(internalKey[len(internalKey)-8:])
userKey = internalKey[len(magic) : len(internalKey)-9]
return
}获取单条数据也是通过 iter 迭代器来实现的,只是 limit 为 1. 当 revison 为 0, 那么初始的 revison 为 uint64 最大.
func (b *backend) getInternalVal(ctx context.Context, key []byte, revision uint64) (val []byte, modRevision uint64, err error) {
if revision == 0 {
revision = math.MaxUint64
}
startKey := b.coder.EncodeObjectKey(key, revision)
endKey := b.coder.EncodeObjectKey(key, 0)
iter, err := b.kv.Iter(ctx, startKey, endKey, 0, 1)
if err != nil {
return nil, 0, err
}
defer iter.Close()
err = iter.Next(ctx)
if err != nil {
if err == io.EOF {
// it's compacted after deleted or it doesn't exist
return nil, 0, storage.ErrKeyNotFound
}
return nil, 0, err
}
userKey, modRev, err := b.coder.Decode(iter.Key())
if modRev == 0 || bytes.Compare(userKey, key) != 0 {
// it's marked by deleting
return nil, modRev, storage.ErrKeyNotFound
}
return iter.Val(), modRev, nil
}需要保存 rawkey 对应的最新 revison 版本,另外还需要记录 rawkey 对应 revison 的值.
// CreateWithTTL implements Creator interface
func (l *naiveCreator) CreateWithTTL(ctx context.Context, key []byte, val []byte, revision uint64, ttl int64) (err error) {
revisionKey := l.coder.EncodeRevisionKey(key)
objectKey := l.coder.EncodeObjectKey(key, revision)
revisionBytes := uint64ToBytes(revision)
err = l.create(ctx, revisionKey, objectKey, val, revisionBytes, ttl)
...
}
func (l *naiveCreator) create(ctx context.Context, revisionKey []byte, objectKey []byte, value []byte, revision []byte, lease int64) (err error) {
batch := l.store.BeginBatchWrite()
batch.PutIfNotExist(revisionKey, revision, lease)
batch.Put(objectKey, value, lease)
return batch.Commit(ctx)
}
func (l *naiveCreator) update(ctx context.Context, revisionKey []byte, objectKey []byte, value []byte, newRevision []byte, oldRevision []byte, lease int64) (err error) {
batch := l.store.BeginBatchWrite()
batch.CAS(revisionKey, newRevision, oldRevision, lease)
batch.Put(objectKey, value, lease)
return batch.Commit(ctx)
}既然 kubebrain 的存在是为了替换 etcd 作为新一代的元数据存储, 那么也是需要支持 etcd watch 功能. k8s 内部的 watch 订阅无处不在, informer 的实现就离不开 etcd watch. 社区中大多数分布式数据库是不支持 watch 功能的, tikv 也是不支持 watch 订阅的. kubebrain 考虑到对接的 kv 数据库不支持 watch, 所以在其内部实现了 watch 功能.
简化流程如下.
- 先在 watch 里注册含有 chan 的 sub 对象,再创建一个跟 grpc 服务层及交互的 result 队列.
- 获取增量的数据,记录最新的 last revison, 然后把增量的数据推到 result chan 里.
- 开一个协程去监听 sub.chan,然后过滤小于等于 last revison 的数据,把大于 last revison 的数据放到 result 队列中,其目的在于 1,2 步骤非原子,概率上会产生的重复的消息.
- 让 grpc 服务层监听 result 队列,把数据写到 conn stream 里.
- backend 会启动一个 go b.watcherHub.Stream(b.watchChan) 协程,该协程会监听下游的chan, 当有事件到达时,会把该事件推送给所有的 sub 订阅端.
先 etcd 到 brain,最后在 backend 找到 watch 的最终实现.
代码位置: pkg/backend/watch.go
kubebrain 使用一个环形数组实现的事件缓存, 逻辑好理解,数组来存数据,两个 int64 记录数组中开始及结束的位置,该数字会一直单调递增,使用取摸计算位置. FindEvents() 使用方法来实现 revison 增量数据的扫描.
代码位置: github/kubebrain/pkg/backend/ring.go
type Ring struct {
s, e int64
l int
arr []*proto.Event
sync.RWMutex
}
func NewRing(l int) *Ring {
return &Ring{
arr: make([]*proto.Event, l, l),
l: l,
}
}
func (r *Ring) Add(event *proto.Event) {
r.Lock()
defer r.Unlock()
r.arr[r.index(r.e)] = event
if r.e == r.s+int64(r.l) {
r.s++
}
r.e++
}
func (r *Ring) Size() int {
return r.l
}
func (r *Ring) newest() *proto.Event {
return r.arr[r.index(r.e-1)]
}
func (r *Ring) oldest() *proto.Event {
return r.arr[r.index(r.s)]
}
func (r *Ring) Reset() {
r.Lock()
defer r.Unlock()
r.s, r.e = 0, 0
}首先实现一个 k8s 里锁的接口,kubebrain 的锁是通过 tikv 实现的,然后借助 k8s 的 leaderelection.RunOrDie 方法来拿锁和间隔性的续约.
LeaderElection 接口定义如下:
代码位置: pkg/server/service/leader/leader.go
type LeaderElection interface {
// Campaign run leader election loop
Campaign()
// GetLeaderInfo get leader info, return peer address
GetLeaderInfo() string
// IsLeader return true when this instance is leader
IsLeader() bool
// GetElectionInfo get info of election
GetElectionInfo() (ElectionInfo, error)
}拿锁是通过存储层实现 PutIfNotExist 方法来实现的,锁的续约则通过 cas 实现的,总之需要存储接口实现, 获取锁信息是直接到存储层读取.
代码位置: pkg/backend/election/election.go
// Get implements resourcelock.Interface
func (r *resourceLock) Get() (*resourcelock.LeaderElectionRecord, error) {
klog.V(8).Info("[resource lock] get lock")
err := r.getRecord()
if err != nil {
return nil, err
}
err = r.getTso()
if err != nil {
return nil, err
}
return &r.record, nil
}
func (r *resourceLock) getRecord() (err error) {
ctx, cancel := r.genContext(context.Background())
defer cancel()
var val []byte
val, err = r.store.Get(ctx, r.electionKey)
if err != nil {
if err == storage.ErrKeyNotFound {
return apierrors.NewNotFound(schema.GroupResource{}, string(r.electionKey))
}
return err
}
r.lastVal = val
var record resourcelock.LeaderElectionRecord
if err := json.Unmarshal(val, &record); err != nil {
return err
}
r.record = record
return nil
}
func (r *resourceLock) Create(ler resourcelock.LeaderElectionRecord) error {
lerBytes, err := json.Marshal(ler)
if err != nil {
return err
}
batch := r.store.BeginBatchWrite()
batch.PutIfNotExist(r.electionKey, lerBytes, 0)
ctx, cancel := r.genContext(context.Background())
defer cancel()
err = batch.Commit(ctx)
if err != nil {
return err
}
r.lastVal = lerBytes
r.tso, err = r.store.GetTimestampOracle(context.Background())
return err
}
// Update implements resourcelock.Interface
func (r *resourceLock) Update(ler resourcelock.LeaderElectionRecord) error {
recordBytes, err := json.Marshal(ler)
if err != nil {
return err
}
batch := r.store.BeginBatchWrite()
batch.CAS(r.electionKey, recordBytes, r.lastVal, 0)
ctx, cancel := r.genContext(context.Background())
defer cancel()
err = batch.Commit(ctx)
if err != nil {
return err
}
r.tso, err = r.store.GetTimestampOracle(context.Background())
return err
}借助 tikv 的事务功能实现 PutIfNotExist, CAS 函数, 通过事务让其具有原子性.
代码位置: pkg/storage/tikv/batch.go
type batch struct {
txn *txnkv.KVTxn
list []func(ctx context.Context) error
}
func (b *batch) PutIfNotExist(key []byte, val []byte, ttl int64) {
idx := len(b.list)
b.list = append(b.list, func(ctx context.Context) error {
oldVal, err := b.txn.Get(ctx, key)
if err != nil && tikverr.IsErrNotFound(err) {
err = b.txn.Set(key, val)
if err != nil {
return errors.Wrapf(err, "fail to create key %s", string(key))
}
return nil
} else if err == nil {
return storage.NewErrConflict(idx, key, oldVal)
}
return errors.Wrapf(err, "fail to get key %s", string(key))
})
}
func (b *batch) CAS(key []byte, newVal []byte, oldVal []byte, ttl int64) {
idx := len(b.list)
b.list = append(b.list, func(ctx context.Context) error {
val, err := b.txn.Get(ctx, key)
if err != nil {
if tikverr.IsErrNotFound(err) {
return storage.ErrKeyNotFound
}
return errors.Wrapf(err, "fail to get key %s", string(key))
}
if !bytes.Equal(oldVal, val) {
return storage.NewErrConflict(idx, key, val)
}
err = b.txn.Set(key, newVal)
if err != nil {
return errors.Wrapf(err, "fail to set key %s", string(key))
}
return nil
})
}像 kubebrain, tidb 里有个逻辑时钟 tso, 他其实逻辑上跟 id 生成器是一样的, 都是在维护全局递增的id.
etcd 对于每次 key 的操作都会产生全局递增的 revision, 通过该修订号可以判定顺序, 也可以使用 list/watch 功能, 使用 revison 版本号可以拿到新增的数据.
kubebrain 当然也是需要使用 revision 管理 key 的版本, 每个 Revision 是一个 uint64 的数字. 分配 Revision 时需要保证 Revision 全局单调递增. 在单机数据库中产生时间戳很简单,用 atomic 原子自增的整数就能以很高的性能分配版本号.
但 kubebrain 是分布式架构, 如何生成递增的 revison ?
kubebrain 的设计就简单粗暴一些, 多个 kubebrain 节点进行选举, 只有主节点才可进行发号器逻辑, 也就是说只有主节点才可以进行写操作. 其他节点作为候选者自然不能进行写操作.
kubebrain 在代码中有说明 tso 的逻辑是参考了 tidb tso 设计. 但 kubebrain 是在内存里维护 tso, 但 tidb 则把 tso 生成器逻辑放到了 pd 组件里, 每次进行事务的时候都需要到 pd 申请事务 id, 带来的开销是每次请求都需要一次 rtt 调用.
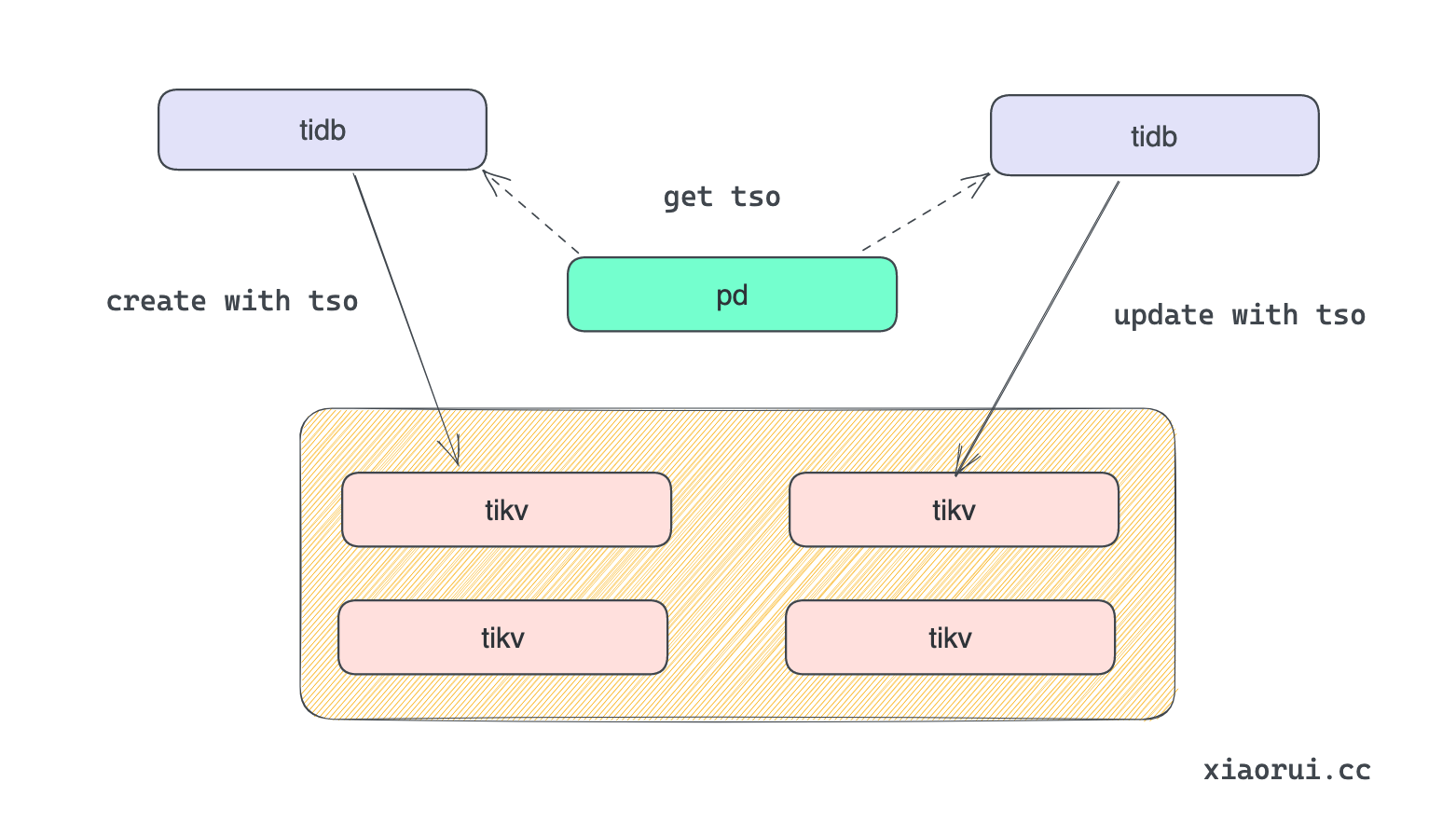
代码没什么可说的, 就是在内存里维护了两个 revison, 每次生成的时候使用 atomic 递增.
// naiveTSO is the allocator of revision based on the tso service of kv store
type naiveTSO struct {
committedRevision uint64
dealRevision uint64
}
// GetRevision implement TSO interface
func (n *naiveTSO) GetRevision() (maxCommittedRevision uint64) {
return atomic.LoadUint64(&n.committedRevision)
}
// Deal implement TSO interface
func (n *naiveTSO) Deal() (revision uint64, err error) {
return atomic.AddUint64(&n.dealRevision, 1), err
}
// Commit implement TSO interface
func (n *naiveTSO) Commit(revision uint64) {
atomic.StoreUint64(&n.committedRevision, revision)
// in case leader transfer, need to update tso and pre tso
preTSO := atomic.LoadUint64(&n.dealRevision)
if preTSO < revision {
atomic.CompareAndSwapUint64(&n.dealRevision, preTSO, revision)
}
}
// Init implement TSO interface
func (n *naiveTSO) Init(start uint64) {
atomic.StoreUint64(&n.committedRevision, start)
atomic.StoreUint64(&n.dealRevision, start)
}
func NewTSO() TSO {
return &naiveTSO{}
}KubeBrain中支持特定类型resource的TTL机制,且实现方式与etcd有显著不同.
- 不存在Lease和Key的绑定关系,仅根据Key的Pattern来确定是否有TTL,更新TTL需要更新Key Value
- 不支持灵活的TTL时间设置,超时时间固定
- 并不保证超过TTL之后数据立即被回收
- 针对超过TTL被删除Key并不会抛出对应的Event
KubeBrain中实现TTL有两种方式.
- 对于支持Key Value TTL的存储引擎,KubeBrain会将TTL下沉到存储引擎中实现,GC操作和读放大
- 对于不支持Key Value TTL的存储引擎,KubeBrain提供了内置的TTL机制
KubeBrain内置的TTL机制作为Compact机制的一个组成而存在。KubeBrain主节点会定时对存储引擎中所有的数据进行扫描,在不破坏一致性的前提下将Revision过旧的数据进行删除,避免存储引擎中的数据量无限制增长。
- 每次开始Compact前,KubeBrain主节点会记录物理时钟TimeStamp和逻辑时钟revision的历史记录,并且保存在内存中,作为revision是否超时的查询依据
- 执行Compact时会从内存中检查之前Compact记录的历史记录,根据历史记录中的TimeStamp和当前TimeStamp的差值大于固定TTL的最新的历史记录,对应的Revision记作TTLRevision,并清理掉之前的历史记录,在扫描Key的时候对于符合特定Pattern的Key
- 对于Revision Key,如果value对应的Revision不大于TTLRevision,则清理
- 对于Object Key,如果Decode(ObjectKey)得到的Revision不大于TTLRevision,则清理
每隔 60 秒进行一次 compact 操作,传递的 revison 是新生成的最新 revison - 1000 . 有点奇葩呀,再写入频繁的场景下,key 含有多 revison 的数据很容易被清理掉。 另外 compact 是把所有匹配 prefix 的 kvs 都捞出来进行遍历,通过 coder 提取 key 的 revison,如果小于指定的 revison, 则进行剔除.
kubebrain 的 compact 可以选择的策略不多,且值 1000 是写在代码里的, 而 etcd 可以针对时间进行控制,还可以对 key 的 revision count 进行控制. etcd 由于所有的 key 都在内存的 tree 结构中,所以遍历的成本不高,那么如何拿到某个时间点的 revison ? etcd 会启动一个定时器,每隔一段时间记录当前 revison 和 time.now() 的关系.
// compactLoop compacts background
func (s *Server) compactLoop() {
ticker := time.NewTicker(time.Second * 60)
defer ticker.Stop()
for {
<-ticker.C
klog.Info("begin to check compact")
if s.peers.IsLeader() {
klog.Info("leader start to compact")
compactRevision := s.backend.GetCurrentRevision() - 1000
startTime := time.Now()
s.backend.Compact(context.Background(), compactRevision)
s.metricCli.EmitGauge("leader.compact", compactRevision)
s.metricCli.EmitHistogram("leader.compact.latency", time.Since(startTime).Seconds())
}
}
}kubebrain 的 metrics 收集很有趣, 采用 lazy 动态注册的方法.
下面是自定义 metrics 收集器对象的数据结构.
代码位置: pkg/metrics/metrics.go
type prometheusWrapper struct {
globalLabelNames []string
globalLabels []metrics.T
counterVecMu sync.RWMutex
counterVecMap map[string]*prometheus.CounterVec
gaugeVecMu sync.RWMutex
gaugeVecMap map[string]*prometheus.GaugeVec
histogramVecMu sync.RWMutex
histogramVecMap map[string]*prometheus.HistogramVec
}然后,简单说下 counter 和 gauge 收集实现,首先通过 name 在 map 中查找已经已经实例化的收集对象,如果为空,则按照 name 和 labels 实例化对象,然后注册到 prometheus 全局对象里.
// EmitCounter implements metrics.Metrics interface
func (pw *prometheusWrapper) EmitCounter(name string, value interface{}, labels ...metrics.T) error {
flt, _ := convert2float64(value)
pw.mustGetCounterVec(name, labels).With(pw.labelsToMap(labels)).Add(flt)
return nil
}
// EmitGauge implements metrics.Metrics interface
func (pw *prometheusWrapper) EmitGauge(name string, value interface{}, labels ...metrics.T) error {
flt, _ := convert2float64(value)
pw.mustGetGaugeVec(name, labels).With(pw.labelsToMap(labels)).Set(flt)
return nil
}头条开源的 kubebrain 初衷是好的, 可通过自定义存储存储接口, 实现三方数据库的对接, 避免了 etcd 的种种问题.
由于大多数分布式数据库没有 etcd watch 和 revison 功能. 所以需要 kubebrain 帮助 kv 存储系统兼容 etcd watch 订阅和 revison 全局单调递增的等等的设计, 不得不把 kubebrain 搞成单主架构. 也就是说, 虽然启动了多个 kubebrain 实例, 但只有一个实例为主 leader, 其他实例为候选者 candidate, 不参与读写请求.