面向全公司做了一场技术分享,主题是 << kafka的设计与实现>> ,讲这个 topic 的原因是我们团队本身就想很依赖 kafka 中间件,另外同事最近在写关于混合云下的日志收集项目,跟日志收集相关的项目就逃不开 kafka 的。我对 kafka 原理还是有一定的理解,也看过一些零散的 kafka 代码,所以决定给大家讲讲 kafka 。
没太多去聊使用经验,而更多讲了kafka的关键技术点的原理设计实现,还有一些kafka的高级应用,这些都理解了,那么对于怎么用kafka也就理解了。总的来说就是让大家对kafka有更深入的理解,继而对分布式架构多了份知识沉淀。
对于这次分享,我花了心思做PPT及再次补充kafka的知识,但大家其实对kafka的设计原理并不感兴趣,不感冒。😅
有时间再补充每页ppt内容,很多时候知道我没时间补充文稿,所以尽量用图片代替文字来描述枯燥的内容。
如果 ppt 中有你不理解的地方,大家可以到 https://github.com/rfyiamcool/share_ppt 这里提问题 issue .
按照演讲目录来说,分了几块内容.
- 什么是 kafka,有哪些特点.
- kafka 为什么这么快?
- 机械硬盘为什么慢,如何计算寻到时间和旋转时间,iops计算.
- ssd 到底有多生猛
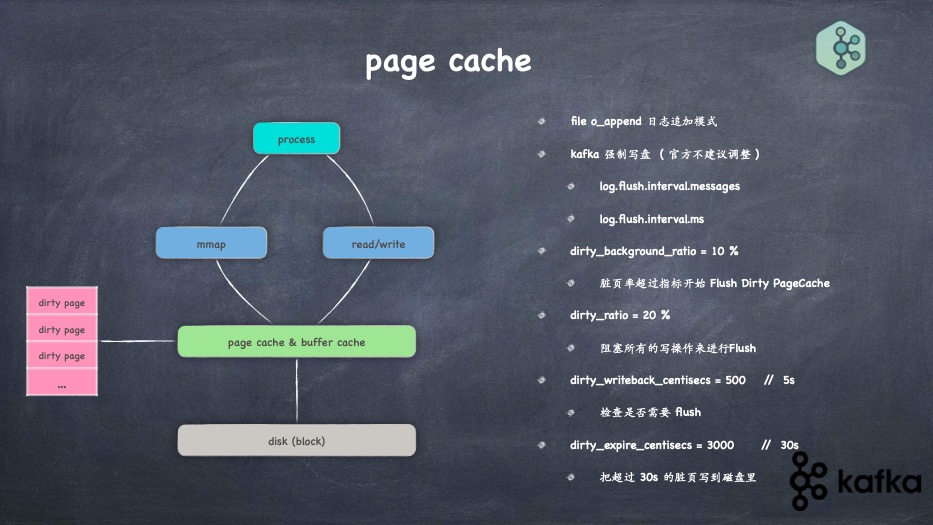
- page cache 读写文件的流程,buffer cache,脏页的落盘时机及阻塞写
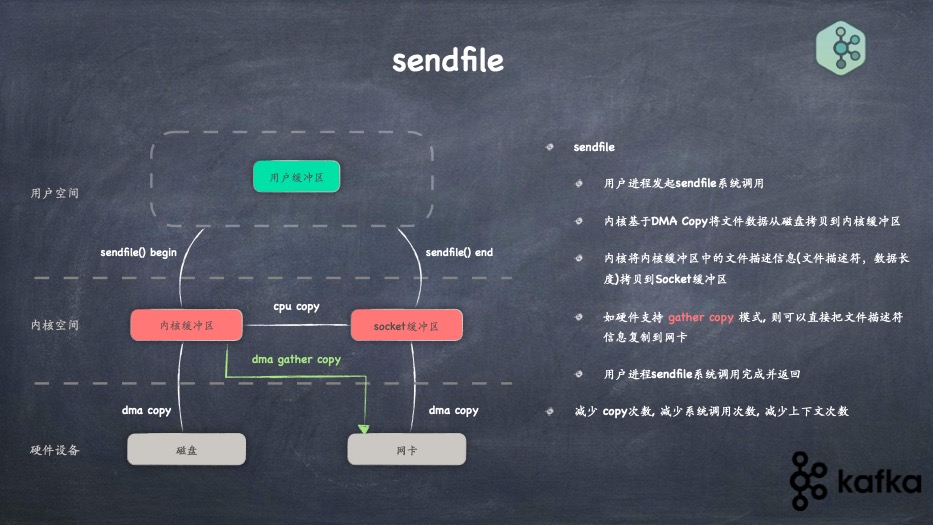
- sendfile
- mmap
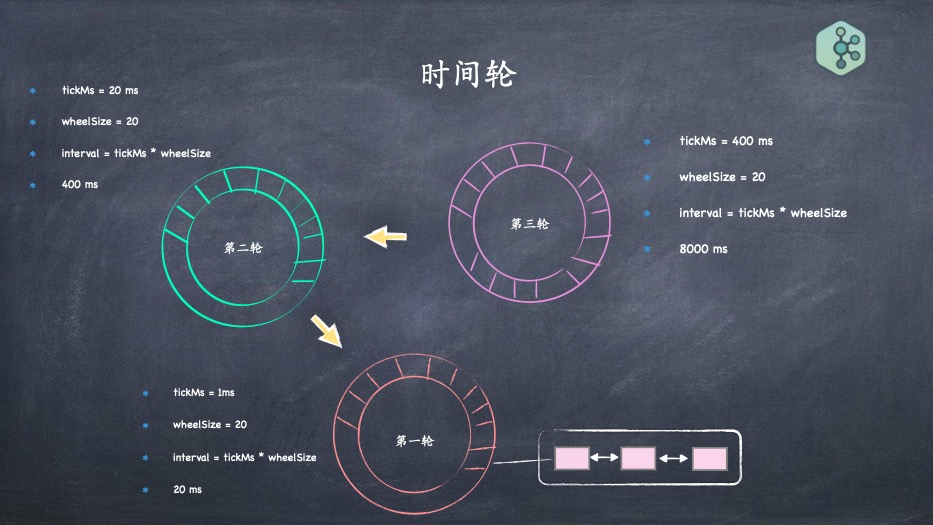
- 时间轮
- 各种编码优化
- ...
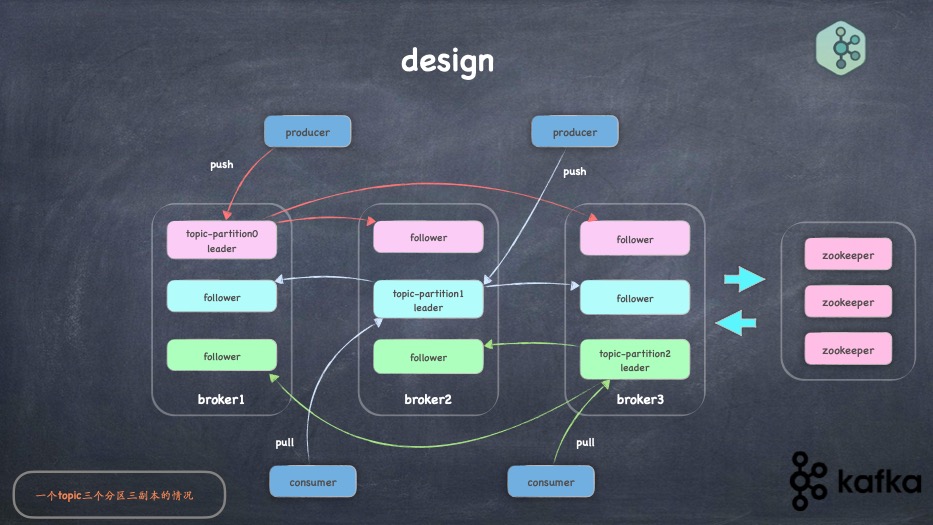
- kafka 架构是个什么样子
- kafka的一些名词解释 ?
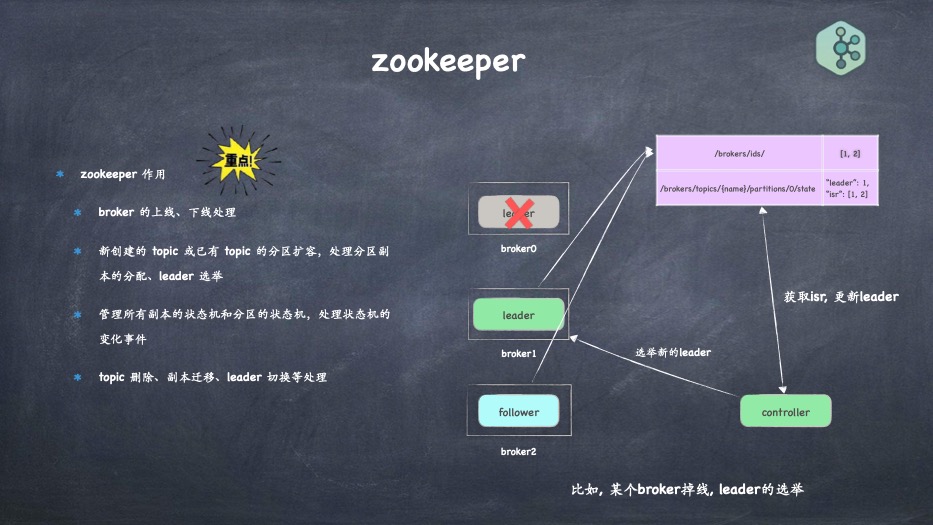
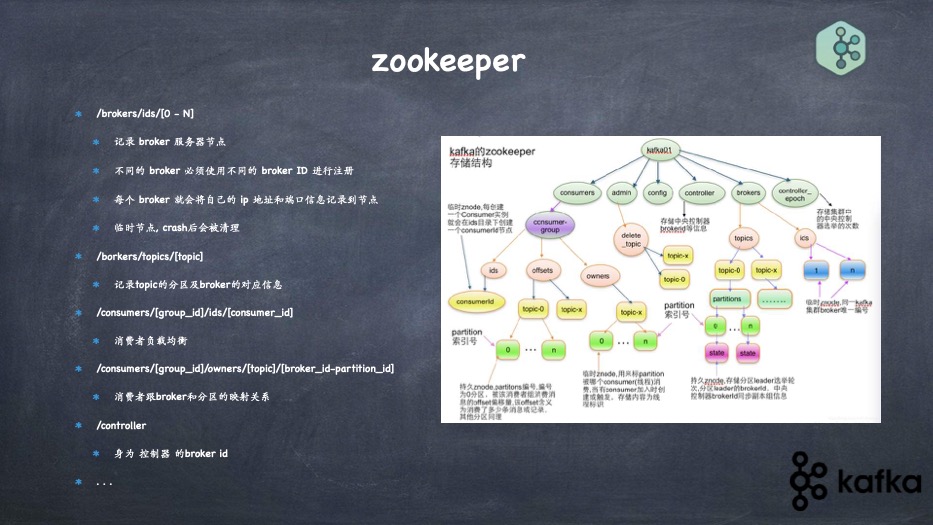
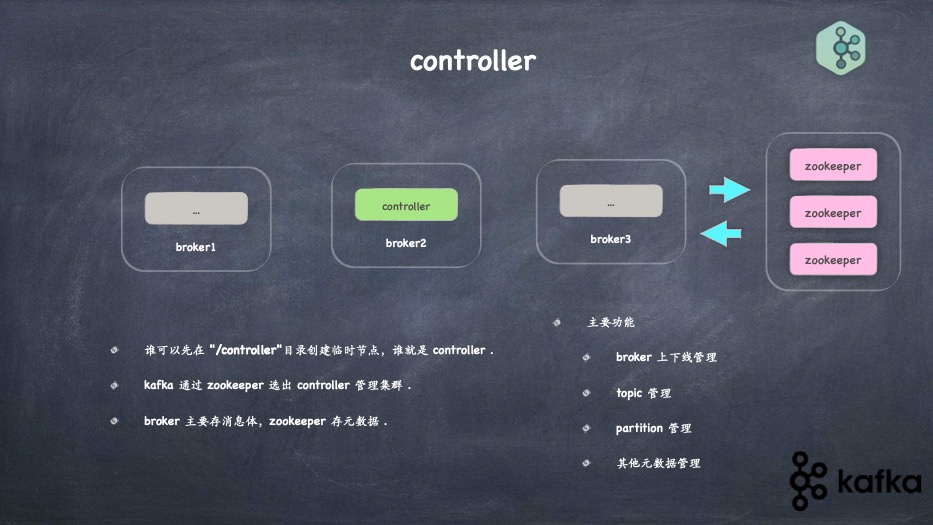
- zookeeper 到底是干嘛的, 各个路径代表的含义
- kafka 的设计原理
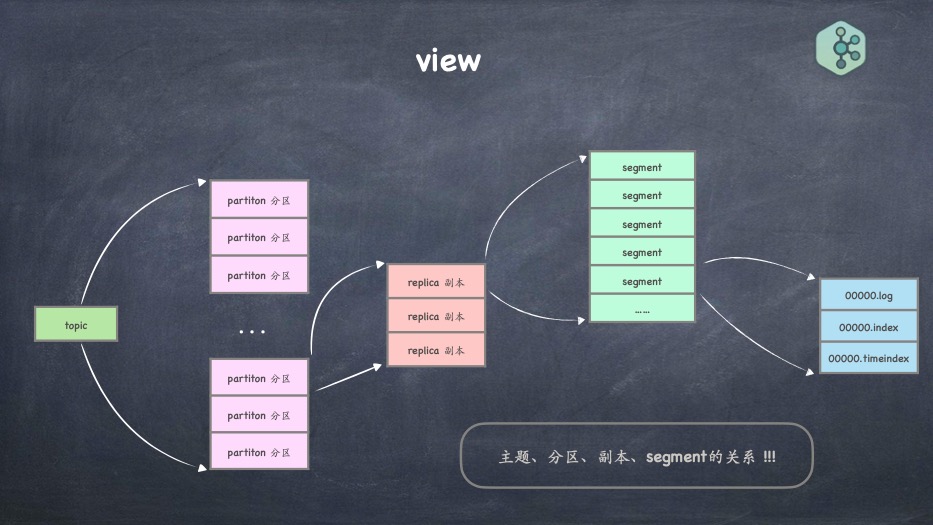
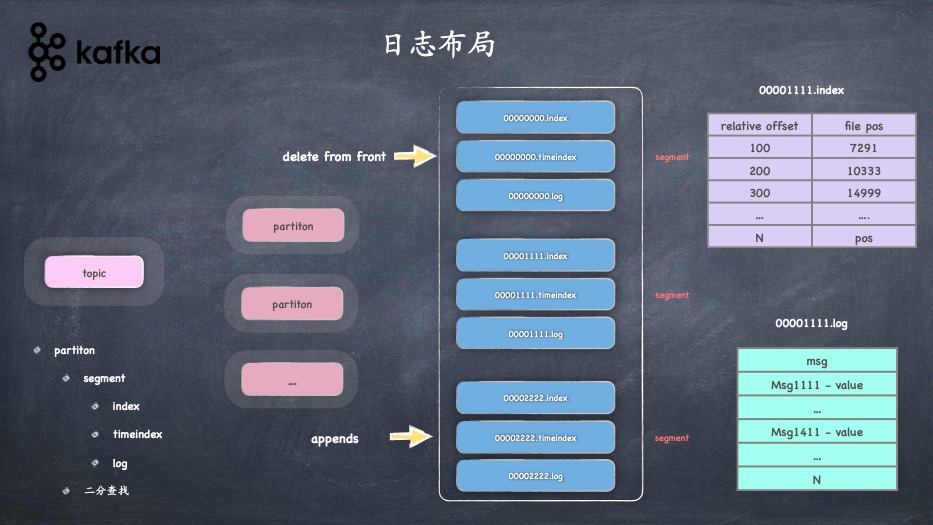
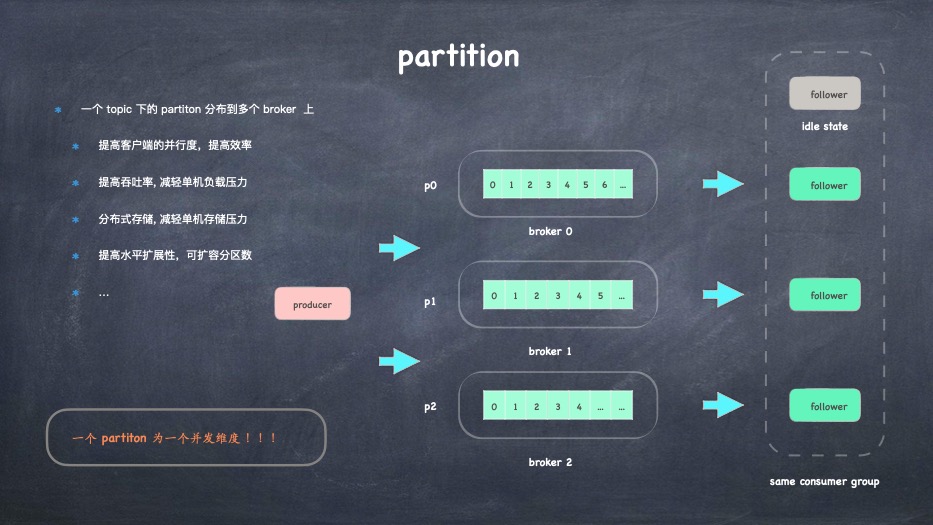
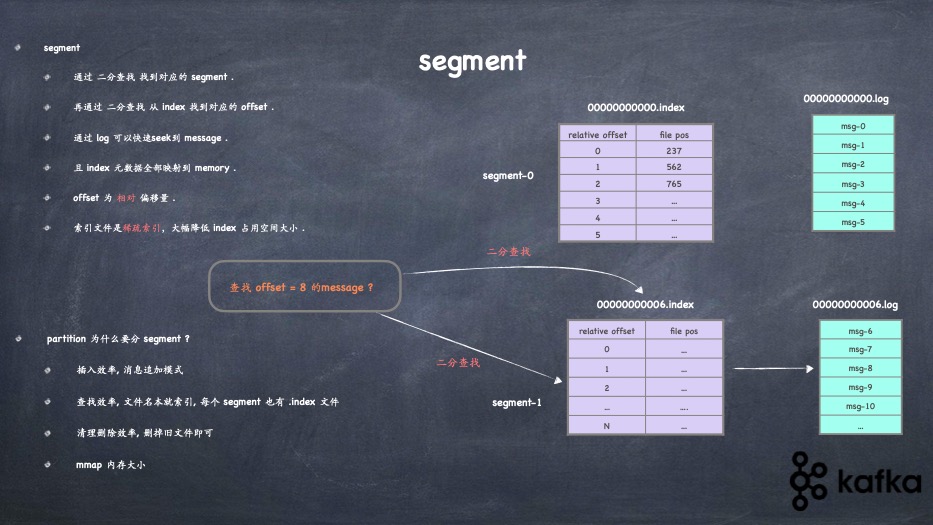
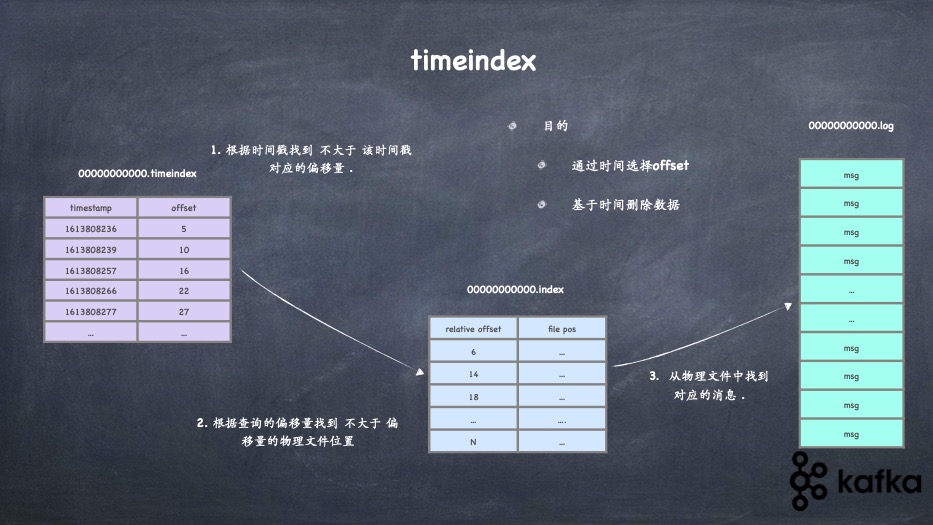
- topic、分区、分段、索引、日志的关系
- 分段索引的实现、日志的存储实现
- 生产者和消费者怎么运行的 ?
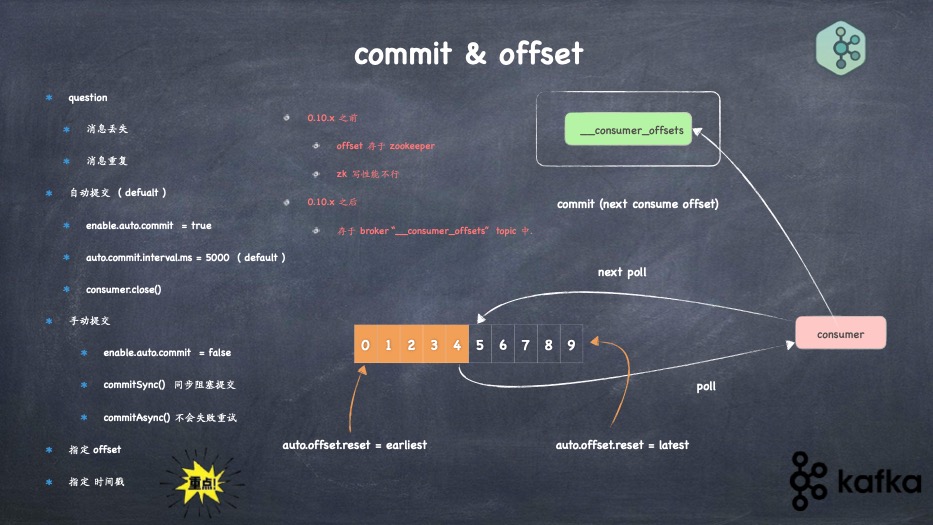
- commit 也分自动和手动提交 ?
- offset 存在哪里,怎么存的?怎么取的,怎么优化的 ?
- 消费组是个什么东西
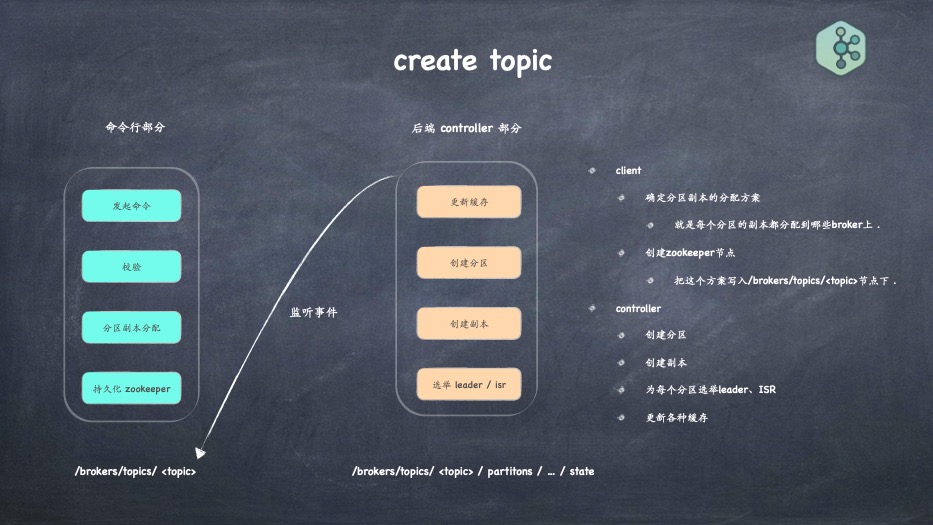
- 创建topic的流程
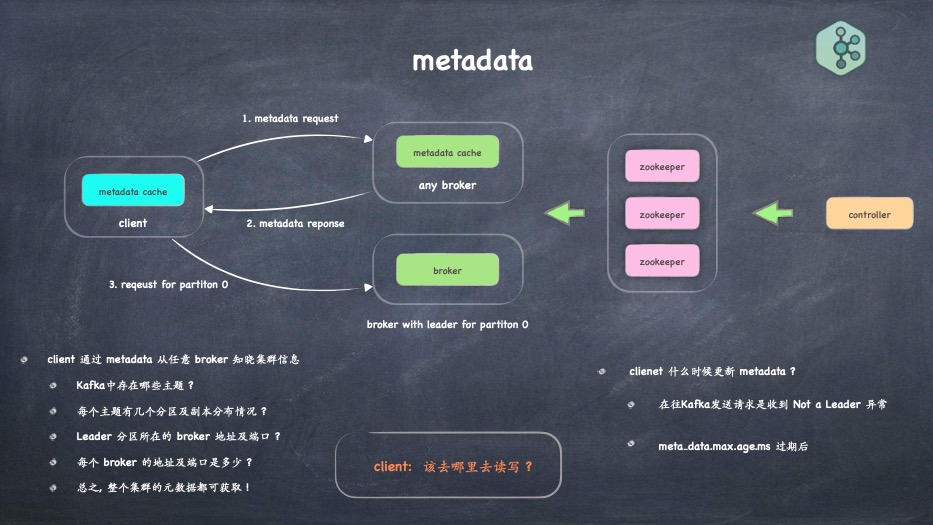
- metadata是个什么东西
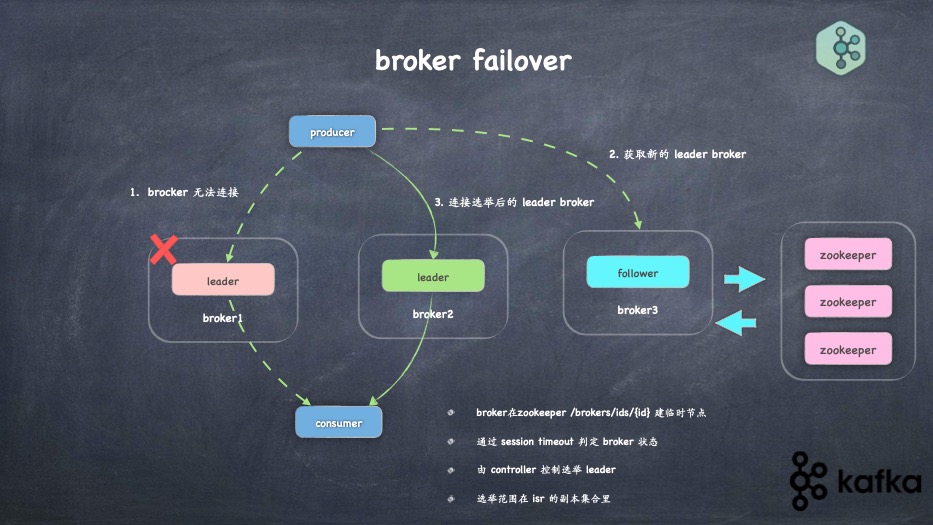
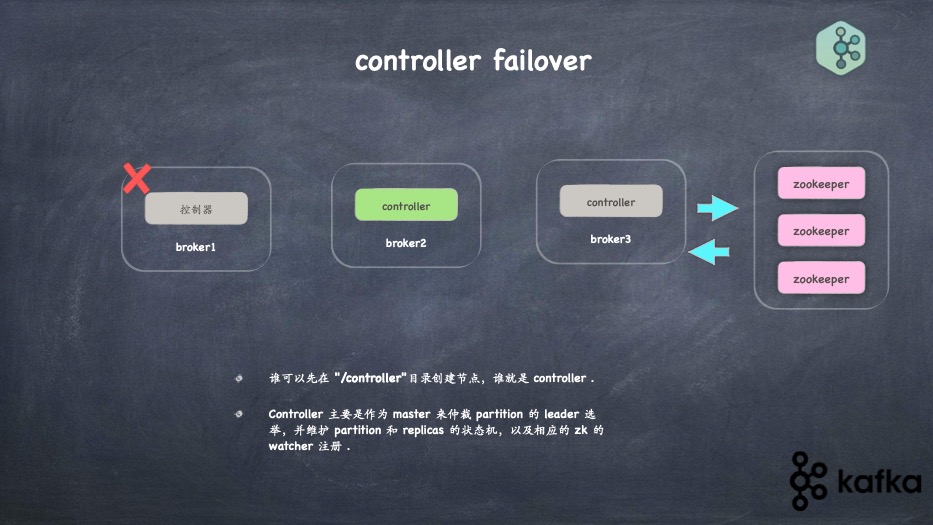
- controller作用,如何选举、如何failover
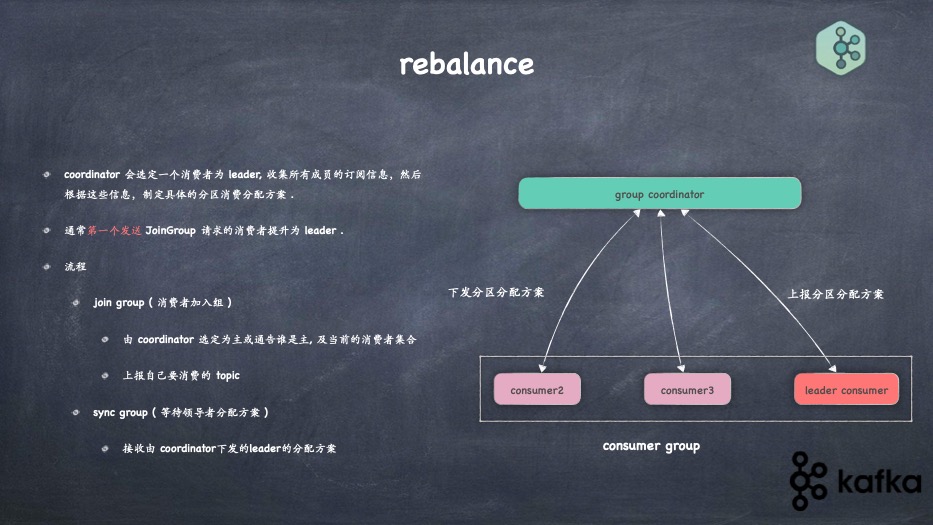
- coordinator作用及实现
- rebalance实现
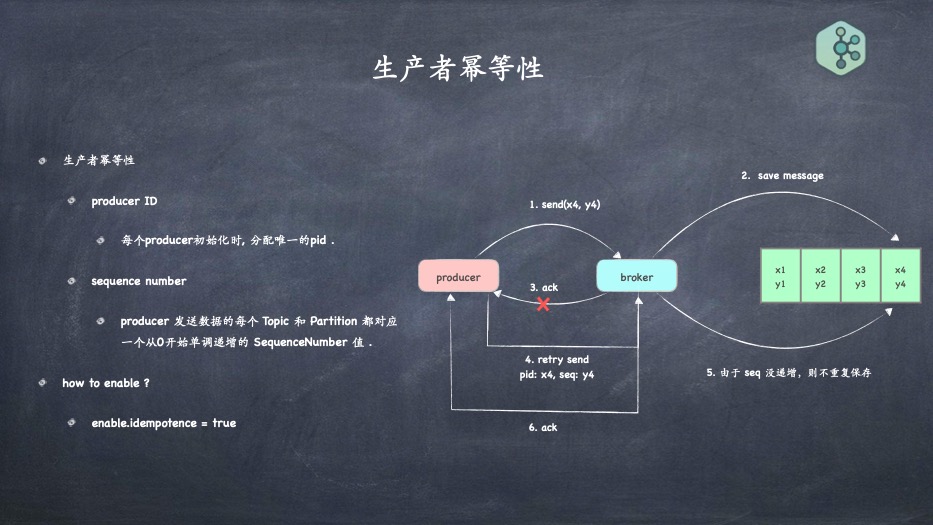
- 生产幂等的实现
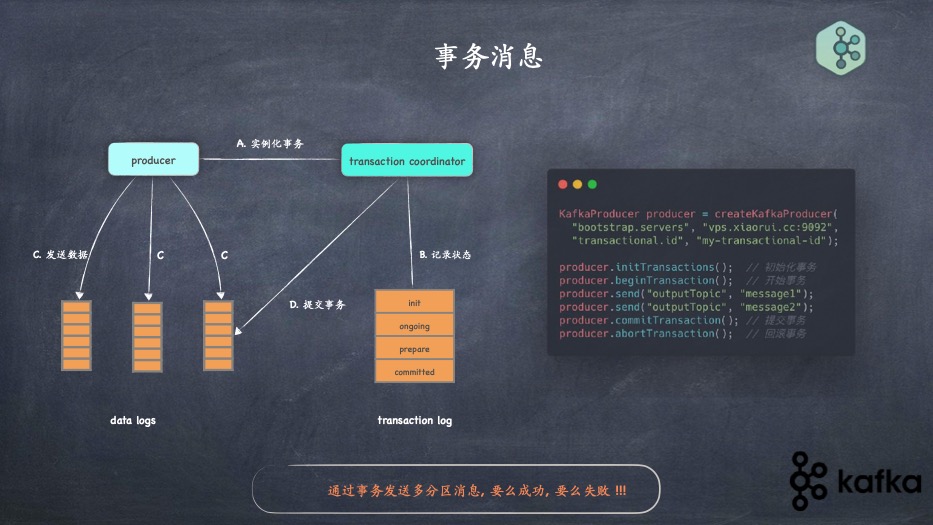
- 消息事务的实现
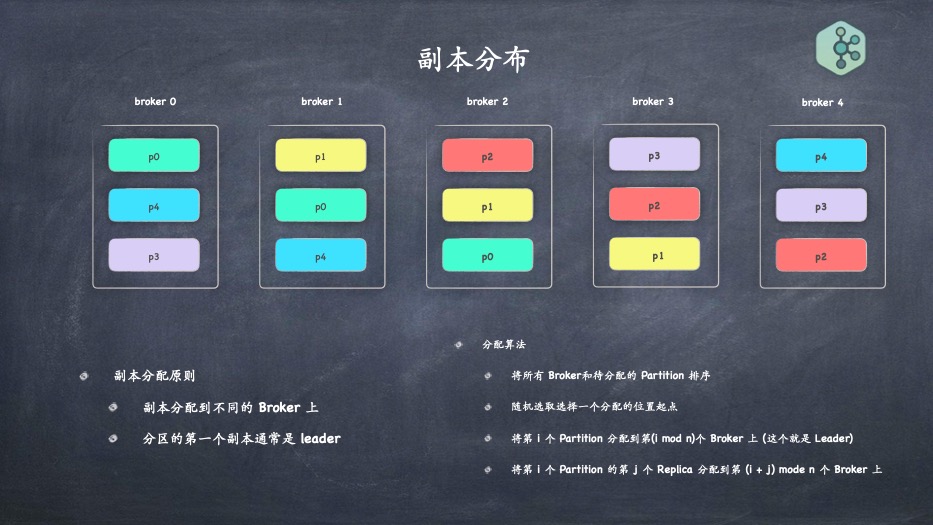
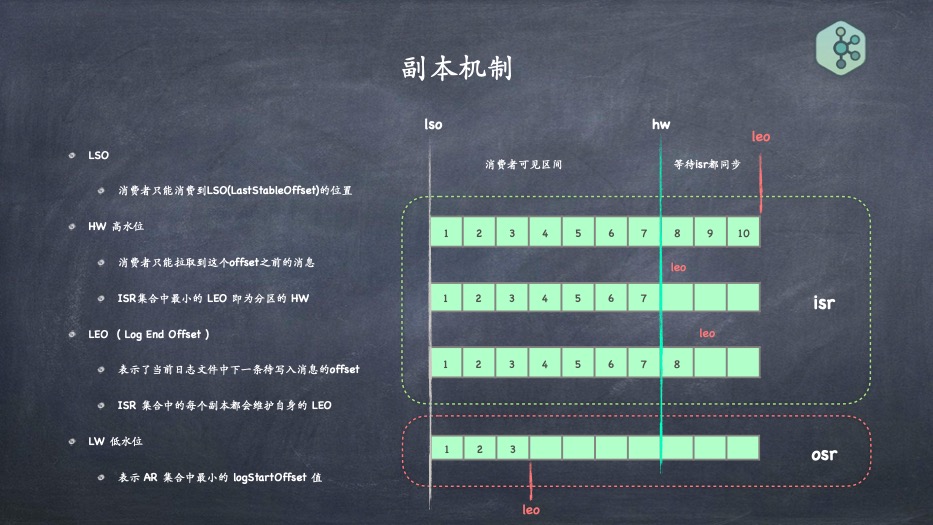
- 分区的副本分布算法,及多副本之间如何做到的选举
- 副本同步机制,理解重要的ar、isr、osr、hw、leo概念
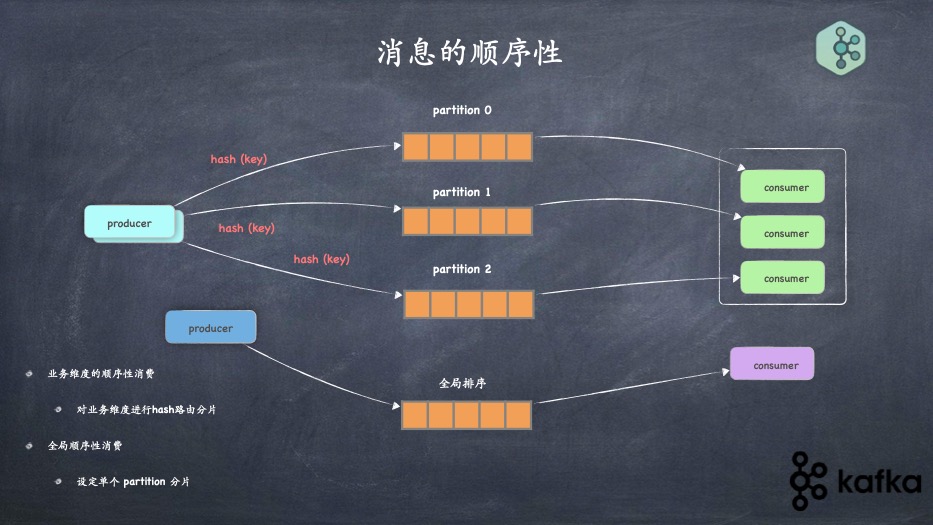
- 如何保证消息的可靠性、顺序性消费
- kafka 高级功能实现
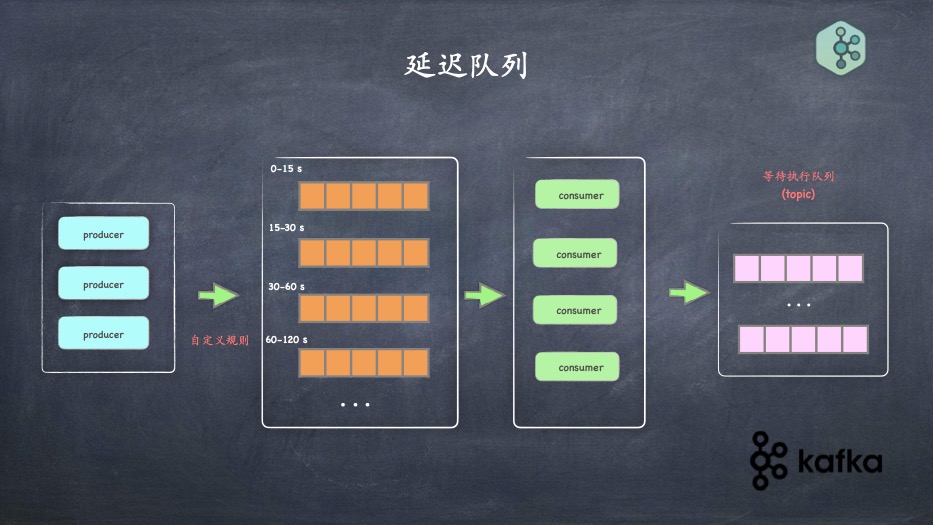
- 延迟队列的实现
- 死信队列实现
- 过滤功能
- 重试队列
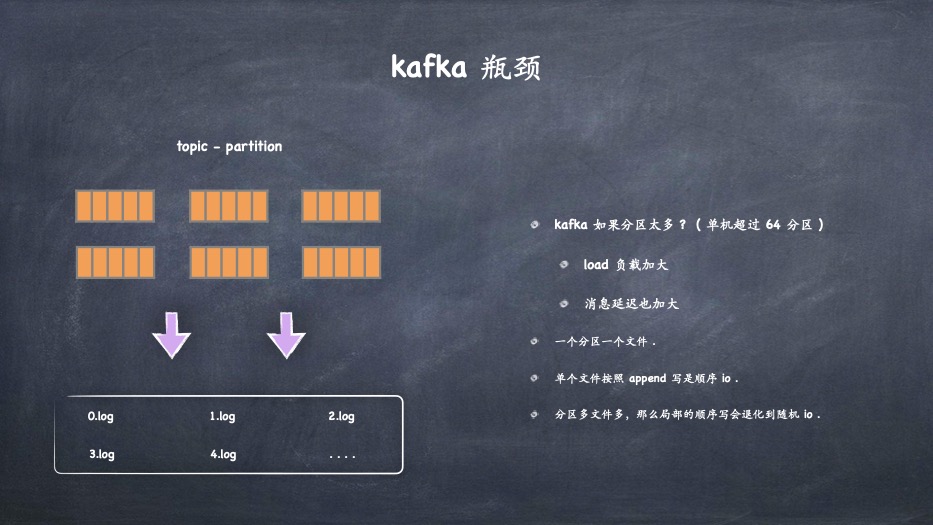
- 对于kafka的性能瓶颈,各个公司对kafka的优化方案
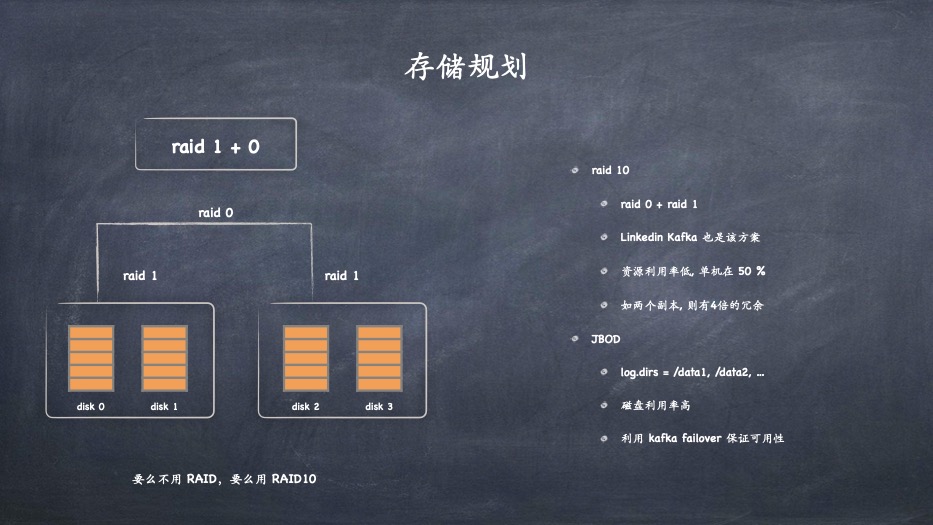
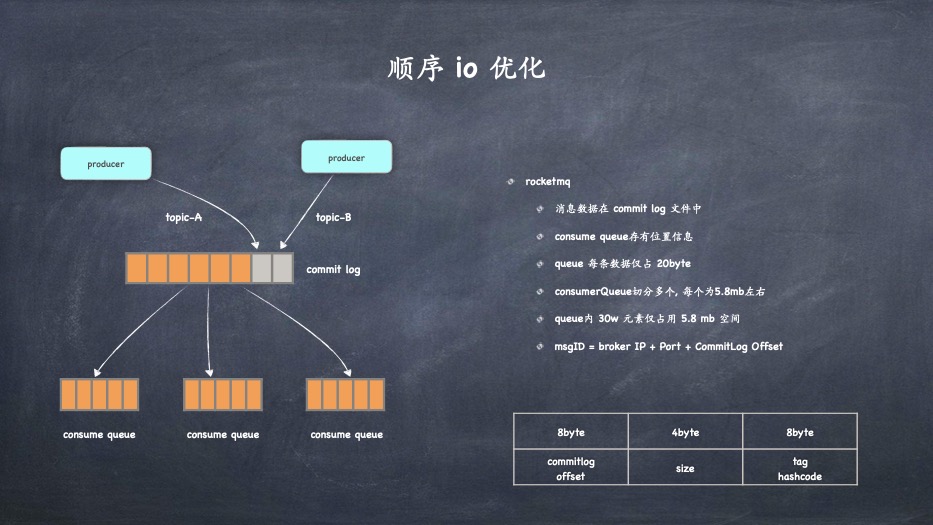
- 聚合消息日志到独立的 commit log 中
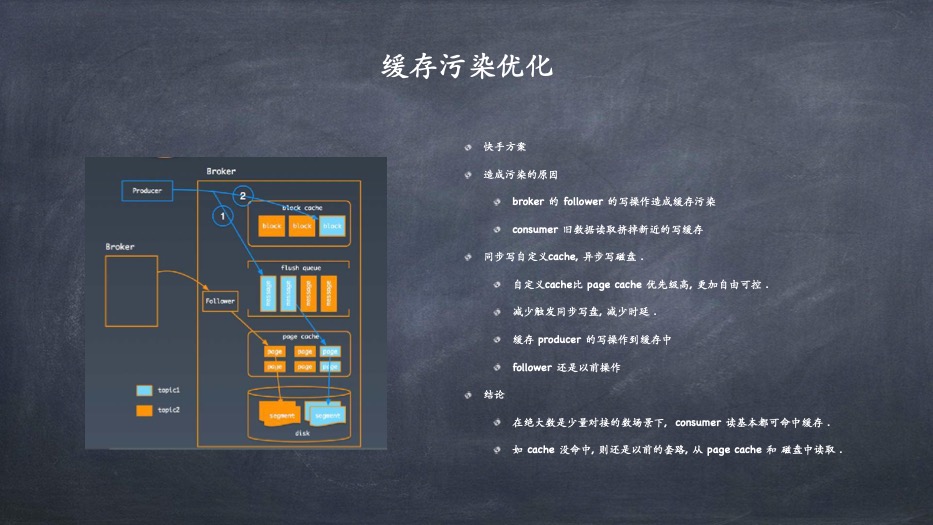
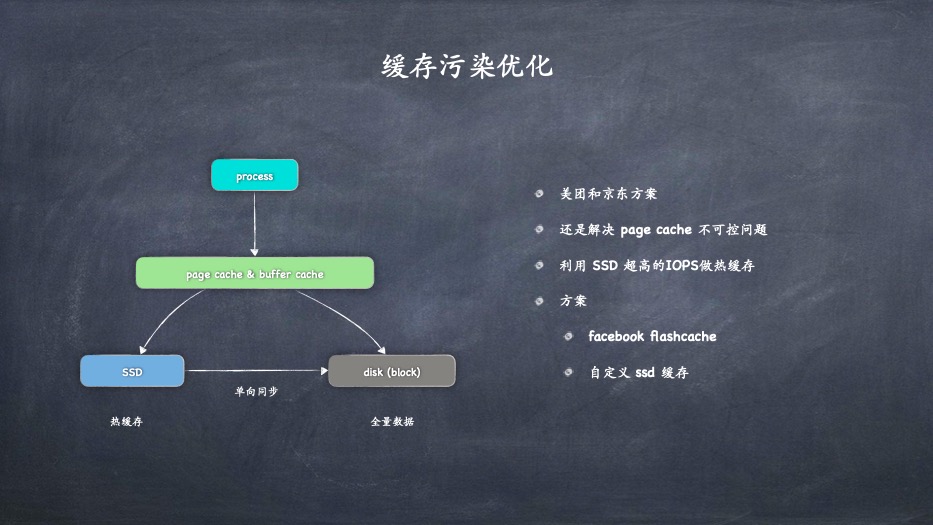
- 缓存污染优化
- ssd iops优化
- 对比其他mq
- rabbitmq
- alibaba rocketmq
- apache pulsar
完整 ppt 的下载地址 :
https://github.com/rfyiamcool/share_ppt#kafka%E7%9A%84%E8%AE%BE%E8%AE%A1%E4%B8%8E%E5%AE%9E%E7%8E%B0
记得点 github star 哈 ...
ppt 的页数有 70 页,只是传了部分的预览图,想看完整的 ppt 可以到github中看。