大早通过监控系统发现有些 api 接口时延抖动,比以前时延都要高,再通过日志得知由于上层业务的变动,导致这边会往 redis 请求近百条命令。由于其他业务也通过 redis 来访问共享数据,故而 redis 的数据结构暂无法做变更。业务那边的逻辑暂时也无法优化,就只能先硬抗了。
一句话,历史遗留问题
如何优化这个时延问题,可以临时通过 redis pipeline 批量管道来优化时延。
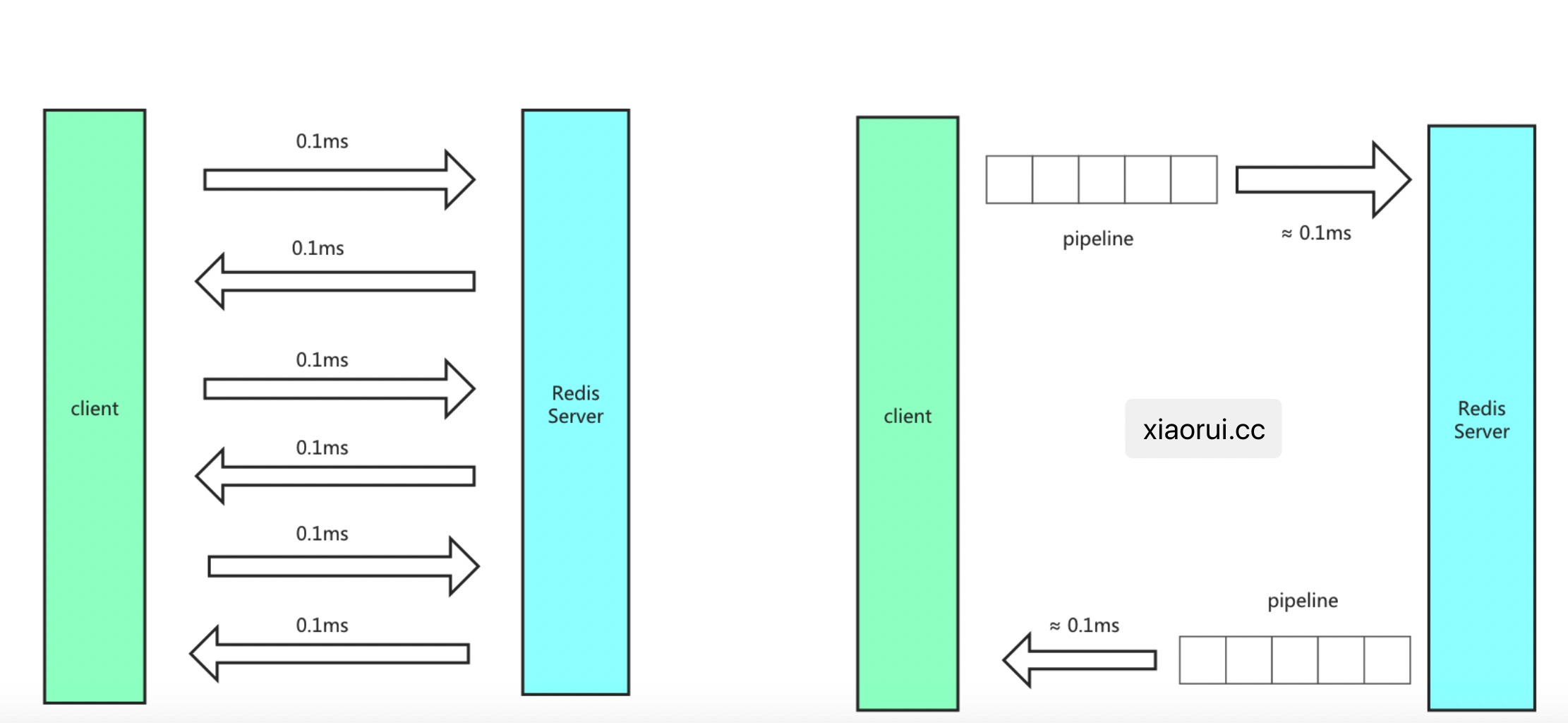
但在使用管道时带来了一个问题,看下文。
先说下发生了什么问题?
在使用 golang redigo pipeline 模式下,错误使用会引发乱序串读的问题。简单说,发了一组 pipeline命 令,但由于只发送而没有去解析接收结果,那么后面通过连接池重用该连接时,会拿到了上次的请求结果,乱序串读了。
redigo 的这个问题我是知道的,只是时间长忘记了,毕竟好久就改用 go-redis。文章中描述的问题只有 redigo 里存在,为什么不采用 go-redis ? 别问,问就是一坨历史代码。项目中跟redis 交互的函数就有 350 多个,坨坨的逻辑轻易没人碰。😅
下面是可以复现问题的代码,注意看注释。
func TestMultiPipeline(t *testing.T) {
c, err := redis.Dial("tcp", "172.16.0.46:6379")
assert.Equal(&testing.T{}, err, nil)
defer c.Close()
s := time.Now()
for i := 0; i < 100; i++ {
c.Send("set", "k1", "k1")
c.Send("get", "k1")
c.Send("set", "k2", "k2")
c.Send("set", "k3", "k3")
c.Flush()
c.Receive()
c.Receive()
c.Receive()
c.Receive()
assert.Equal(&testing.T{}, err, nil)
}
cost := time.Since(s)
t.Log("pipe totol cost: ", cost)
c.Send("get", "k1")
c.Send("get", "k2")
c.Flush()
c.Send("get", "k2")
c.Flush()
k1, err := redis.String(c.Receive())
assert.Equal(t, err, nil)
assert.Equal(t, "k1", k1) // 拿到的是上一波的返回数据
c.Send("get", "k3")
c.Flush()
k2, err := redis.String(c.Receive())
assert.Equal(t, err, nil)
assert.Equal(t, "k2", k2) // 拿到的是上上一个波的返回数据
}看源码可得知,Flush() 只是把buffer缓冲区的数据写到连接里,而没有从连接读取的过程。所以说,在redigo的pipeline里,有几次的写,就应该有几次的 Receive() 。Receive是从连接读缓冲区里读取解析数据。
receive() 是不可或缺的! 不能多,也不能少,每个 send() 都对应一个 receive()。
如果多了,那么就会阻塞,为啥会阻塞 ?他会尝试从 conn 里读取返回数据,但问题已经没有数据可以等待返回了。
如果少了,那么就会造成文章中的 case,串写问题。
话说,文章中提及的问题本不应该要我们去处理,毕竟要上层业务放来小心的控制 receive() 着实太恶心了,更应该督促 redigo 作者去增强完善的功能,然而没用,作者现在已不想改这个库了,毕竟他的竞品 go-redis 更优秀,对外方法都实现了命令抽象,自带集群协议,命令封装在连接池内等等。
func (c *conn) Send(cmd string, args ...interface{}) error {
c.mu.Lock()
c.pending += 1
c.mu.Unlock()
if c.writeTimeout != 0 {
c.conn.SetWriteDeadline(time.Now().Add(c.writeTimeout))
}
if err := c.writeCommand(cmd, args); err != nil {
return c.fatal(err)
}
return nil
}
func (c *conn) Flush() error {
if c.writeTimeout != 0 {
c.conn.SetWriteDeadline(time.Now().Add(c.writeTimeout))
}
if err := c.bw.Flush(); err != nil {
return c.fatal(err)
}
return nil
}
func (c *conn) Receive() (interface{}, error) {
return c.ReceiveWithTimeout(c.readTimeout)
}
func (c *conn) ReceiveWithTimeout(timeout time.Duration) (reply interface{}, err error) {
var deadline time.Time
if timeout != 0 {
deadline = time.Now().Add(timeout)
}
c.conn.SetReadDeadline(deadline)
if reply, err = c.readReply(); err != nil {
return nil, c.fatal(err)
}
// When using pub/sub, the number of receives can be greater than the
// number of sends. To enable normal use of the connection after
// unsubscribing from all channels, we do not decrement pending to a
// negative value.
//
// The pending field is decremented after the reply is read to handle the
// case where Receive is called before Send.
c.mu.Lock()
if c.pending > 0 {
c.pending -= 1
}
c.mu.Unlock()
if err, ok := reply.(Error); ok {
return nil, err
}
return
}上面其实已经说了答案,要么按部就班的使用 receive() ,不多不少的调用;要么直接使用完美的 go-redis 库。
使用了 pipeline 批量确实有效的减少了时延,也减少了 redis 压力。不要再去使用 golang redigo 这个库了,请直接选择 go-redis 库。