虽然使用 golang 标准库 container/list 很容易实现双端队列,但经过 benchmark 压测发现数据差点意思. 在 github 中找到一个叫 edwingeng/deque 的项目,该队列的实现很不错,另外经过线上使用后,高频读写下 cpu 有下降,另外在几百万条数据堆积场景下, gc duration 也有下降. 下面分析下 deque 的设计实现.
代码地址:
https://github.com/edwingeng/deque

优点
- 双端队列设计
- 使用二维数组实现队列,比 list 更快,数据结构 gc 更友好
- sync.pool 优化 chunk 对象
- 更好的扩缩容机制
- 代码生成器,避免 interface{} 装箱拆箱操作.
- v2 版直接支持泛型
缺点
没锁,需要自己加一把锁.
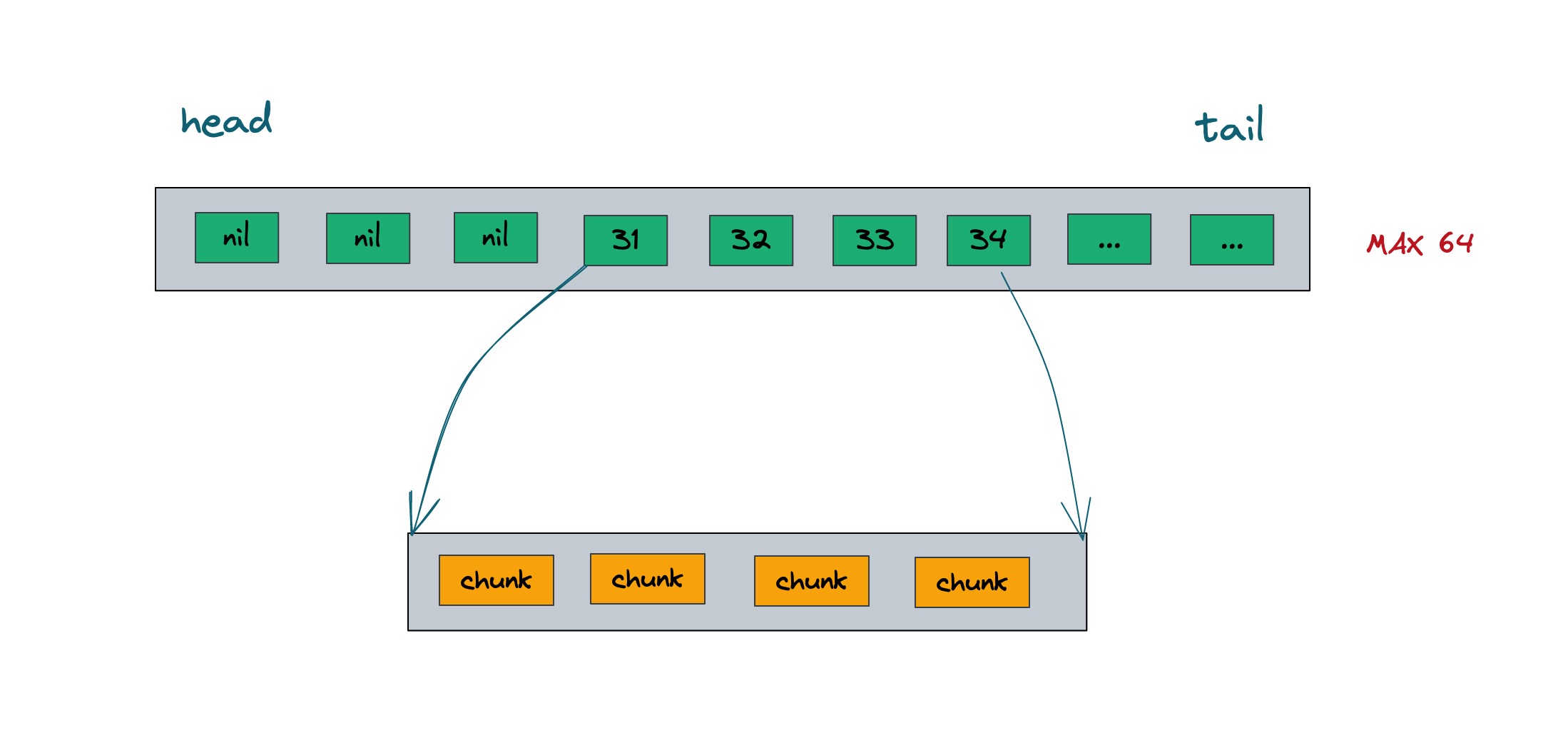
使用了二维数组实现了队列结构,第二层切片是一个 chunk,存放真实数据,而第一层切片关联索引第二层的 chunk.
type chunk struct {
s int
e int
data [chunkSize]Elem
}
type deque struct {
chunks []*chunk
chunkPitch []*chunk
sFree int
eFree int
}
func (dq *deque) PushFront(v Elem) {
var c *chunk
n := len(dq.chunks)
if n == 0 {
dq.expandStart()
c = dq.chunks[0]
} else {
c = dq.chunks[0] // 获取 chunks 头节点.
if c.s == 0 { // 如果该 chunk 满了, 则获取一个 chunk.
dq.expandStart() // 把 start, end 设置 243
c = dq.chunks[0]
}
}
c.s--
c.data[c.s] = v // 也把数据放到 chunk 的尾部.
}
func (dq *deque) PushBack(v Elem) {
var c *chunk
n := len(dq.chunks)
if n == 0 {
dq.expandEnd()
c = dq.chunks[n]
} else {
c = dq.chunks[n-1] // 获取尾部节点,如果该节点满了,则创建一个新的 chunk, start 和 end 为 0.
if c.e == chunkSize {
dq.expandEnd()
c = dq.chunks[n]
}
}
// 把数据放到 chunk 对应的 index 里.
c.data[c.e] = v
// 自增,求下次 index 的位置.
c.e++
}
func (dq *deque) PopBack() Elem {
n := len(dq.chunks)
if n == 0 {
return elemDefValue
}
// 获取尾部的 chunk
c := dq.chunks[n-1]
// 相等说明为空
if c.e == c.s {
return elemDefValue
}
// 获取 chunk 尾部的元素, 并向前滚动索引
c.e--
r := c.data[c.e]
// 置空
c.data[c.e] = elemDefValue
// 如果没有数据了, 则进行缩容
if c.e == 0 {
dq.shrinkEnd()
}
return r
}
func (dq *deque) Len() int {
n := len(dq.chunks)
switch n {
case 0:
return 0
case 1:
// 只有单 chunk
return dq.chunks[0].e - dq.chunks[0].s
default:
// 头部 chunk + 尾部 chunk + 中间 chunk
return chunkSize - dq.chunks[0].s + dq.chunks[n-1].e + (n-2)*chunkSize
}
}使用 sync.pool 缓存 chunk 数据结构, 用来减轻 gc 开销.
var (
sharedChunkPool = newChunkPool(func() interface{} {
return &chunk{}
})
)
// 缩容
func (dq *deque) shrinkEnd() {
...
sharedChunkPool.Put(c)
...
}
// 扩容
func (dq *deque) expandEnd() {
...
c := sharedChunkPool.Get().(*chunk)
...
}chunk 最大为 254 个元素,当超过阈值时会实例化一个新的 chunk. 每次新增的 chunk 也都会放到 chunks 切片里. deque 没有使用 list.List 链表来关联 chunk,则使用切片.
deque 对 chunks 切片做了一些优化,由于双端队列还有个向前插入 pushFront() 的场景,如果单纯用 slice,那么会不断实例化一个新切片,把新的chunk 放到 chunks[0],以前的切片 append 后面.
不断的实例化新切片和搬迁旧切片,该操作还是有开销的. 所以抽象了一个比 chunks 更大的切片做引用占位符.
func (dq *deque) expandEnd() {
if f := dq.eFree; f == 0 {
dq.realloc()
}
// 从 sync.pool 获取新的 chunk 数组
c := sharedChunkPool.Get().(*chunk)
// 重置 start, end 偏移量
c.s, c.e = 0, 0
dq.eFree--
newEnd := len(dq.chunkPitch) - dq.eFree
dq.chunkPitch[newEnd-1] = c
// 把 chunkPitch 的数据引用到 chunks.
dq.chunks = dq.chunkPitch[dq.sFree:newEnd]
}PushBack/Deque<harden> 100000000 12.0 ns/op 8 B/op 0 allocs/op
PushBack/Deque 20000000 55.5 ns/op 24 B/op 1 allocs/op
PushBack/list.List 5000000 158.7 ns/op 56 B/op 1 allocs/op
PushFront/Deque<harden> 195840157 9.2 ns/op 8 B/op 0 allocs/op
PushFront/Deque 30000000 49.2 ns/op 24 B/op 1 allocs/op
PushFront/list.List 5000000 159.2 ns/op 56 B/op 1 allocs/op
Random/Deque<harden> 65623633 15.1 ns/op 0 B/op 0 allocs/op
Random/Deque 50000000 24.7 ns/op 4 B/op 0 allocs/op
Random/list.List 30000000 46.9 ns/op 28 B/op 1 allocs/op