前面我们分析了go 1.14的定时器和信号中断抢占的实现原理,继续分析defer的优化实现。在golang官方的note里描述了go 1.14的defer性能有大幅度提升。
简单描述下优化的原理,go 1.14新加入了开放编码(Open-coded)defer类型,编译器在ssa过程中会把被延迟的方法直接插入到函数的尾部,避免了运行时的deferproc及deferprocStack操作。免除了在没有运行时判断下的deferreturn调用。如有运行时判断的逻辑,则deferreturn也进一步优化,开放编码下的deferreturn不会进行jmpdefer的尾递归调用,而直接在一个循环里遍历执行。
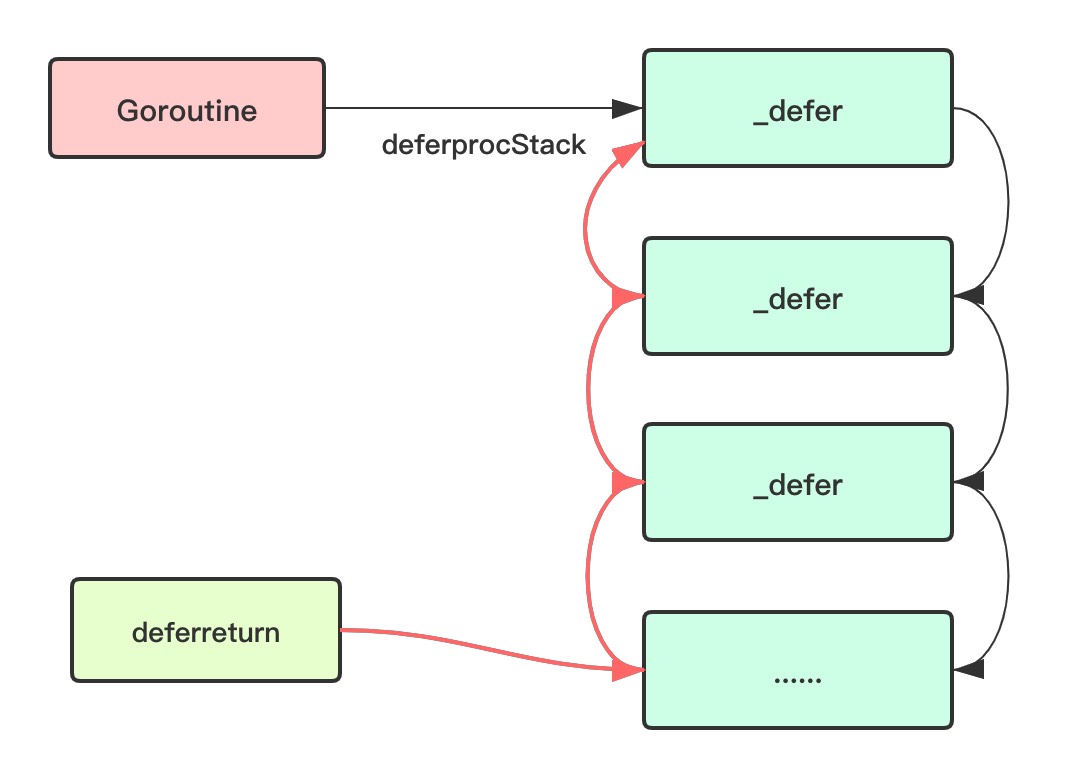
go 1.14之前是这样的。
下面是defer的测试脚本,分别使用go1.13和go1.14来benchmark测试。
// xiaorui.cc
package main
import (
"sync"
"testing"
)
type channel chan int
func NoDefer() {
ch1 := make(channel, 1)
close(ch1)
}
func Defer() {
ch2 := make(channel, 1)
defer close(ch2)
}
func NoDeferLock() {
l := sync.Mutex{}
l.Lock()
l.Unlock()
}
func DeferLock() {
l := sync.Mutex{}
l.Lock()
defer l.Unlock()
}
func BenchmarkNoDefer(b *testing.B) {
for i := 0; i < b.N; i++ {
NoDefer()
}
}
func BenchmarkDefer(b *testing.B) {
for i := 0; i < b.N; i++ {
Defer()
}
}
func BenchmarkNoDeferLock(b *testing.B) {
for i := 0; i < b.N; i++ {
NoDeferLock()
}
}
func BenchmarkDeferLock(b *testing.B) {
for i := 0; i < b.N; i++ {
DeferLock()
}
}看数据可得知go1.14比go1.13速度确实快了不少,差不多有35ns左右… 就上面的脚本来说,在go 1.14里用不用defer影响甚微。由于mac是高频赫兹的cpu,所以耗时比在服务器里要短。
// xiaorui.cc
> go test -bench=. -run=none -benchmem .
goarch: amd64
BenchmarkNoDefer-4 20000000 64.5 ns/op 112 B/op 1 allocs/op
BenchmarkDefer-4 10000000 106 ns/op 112 B/op 1 allocs/op
BenchmarkNoDeferLock-4 30000000 33.7 ns/op 8 B/op 1 allocs/op
BenchmarkDeferLock-4 20000000 73.9 ns/op 8 B/op 1 allocs/op
PASS
ok _/Users/ruifengyun/test 5.220s
> go14 test -bench=. -run=none -benchmem .
goos: darwin
goarch: amd64
BenchmarkNoDefer-4 18966534 62.9 ns/op 112 B/op 1 allocs/op
BenchmarkDefer-4 17870163 68.8 ns/op 112 B/op 1 allocs/op
BenchmarkNoDeferLock-4 42140348 27.8 ns/op 8 B/op 1 allocs/op
BenchmarkDeferLock-4 34660711 30.9 ns/op 8 B/op 1 allocs/op
PASS
ok _/Users/ruifengyun/test 7.641s// xiaorui.cc
func NoDefer() {
ch1 := make(channel, 10)
ch2 := make(channel, 10)
// 两个close
close(ch1)
close(ch2)
}
func Defer() {
ch1 := make(channel, 10)
ch2 := make(channel, 10)
// 两个defer
defer close(ch1)
defer close(ch2)
}go 1.13的汇编输出,runtime.deferprocStack是复制延迟参数到_defer结构里,_defer被链表连接,该链表放在goroutine数据结构里,runtime.deferreturn执行_defer。
// xiaorui.cc
TEXT main.Defer(SB) /root/test/d.go
func Defer() {
...
defer close(ch1)
...
0x452e54 48891424 MOVQ DX, 0(SP)
0x452e58 e8830cfdff CALL runtime.deferprocStack(SB)
0x452e5d 85c0 TESTL AX, AX
0x452e5f 755f JNE 0x452ec0
defer close(ch2)
...
0x452e8b e8500cfdff CALL runtime.deferprocStack(SB)
...
0x452e95 e84612fdff CALL runtime.deferreturn(SB)
...
defer close(ch2)
0x452eab e83012fdff CALL runtime.deferreturn(SB)
...
defer close(ch1)
...
0x452ec1 e81a12fdff CALL runtime.deferreturn(SB)
func Defer() {
0x452ed6 e8d572ffff CALL runtime.morestack_noctxt(SB)
0x452edb e9d0feffff JMP main.Defer(SB)
...下面是go 1.14的汇编码,close(ch)对应的是runtime.closechan函数。函数尾部被插入了runtime.closechan方法,避免了deferprocStack的构建过程和deferreturn执行,而go 1.13通过jmpdefer递归了多次deferreturn,每次从_defer链表获取后进入的_defer记录并执行。
下面汇编有 “runtime.deferreturn” 的调用,但在调用前已经被执行RET返回指令了。另外也没有test、cmp等判断指令,按道理deferreturn可直接优化掉。😅
defer close(ch1)
0x458d14 488d0d5d1e0200 LEAQ 0x21e5d(IP), CX
0x458d1b 48894c2440 MOVQ CX, 0x40(SP)
0x458d20 488b542420 MOVQ 0x20(SP), DX
0x458d25 4889542438 MOVQ DX, 0x38(SP)
0x458d2a c644241f01 MOVB 0x1, 0x1f(SP)
defer close(ch2)
0x458d2f 48894c2430 MOVQ CX, 0x30(SP)
0x458d34 4889442428 MOVQ AX, 0x28(SP)
}
0x458d39 c644241f01 MOVB0x1, 0x1f(SP)
0x458d3e 488b442428 MOVQ 0x28(SP), AX
0x458d43 48890424 MOVQ AX, 0(SP)
0x458d47 e8e4b6faff CALL runtime.closechan(SB)
0x458d4c c644241f00 MOVB 0x0, 0x1f(SP)
0x458d51 488b442438 MOVQ 0x38(SP), AX
0x458d56 48890424 MOVQ AX, 0(SP)
0x458d5a e8d1b6faff CALL runtime.closechan(SB)
0x458d5f 488b6c2448 MOVQ 0x48(SP), BP
0x458d64 4883c450 ADDQ0x50, SP
0x458d68 c3 RET
0x458d69 e8b2f8fcff CALL runtime.deferreturn(SB)
0x458d6e 488b6c2448 MOVQ 0x48(SP), BP
0x458d73 4883c450 ADDQ $0x50, SP
0x458d77 c3 RET
func Defer() {
0x458d78 e8b390ffff CALL runtime.morestack_noctxt(SB)
0x458d7d e91effffff JMP main.Defer(SB)共有三种 defer 模式类型,编译后一个函数里只会一种 defer 模式。
-
堆上分配 (deferProc),基本是依赖运行时来分配 “_defer” 对象并加入延迟参数。在函数的尾部插入deferreturn方法来消费defer链条。
-
栈上分配 (deferprocStack),基本跟堆上差不多,只是分配方式改为在栈上分配,压入的函数调用栈存有_defer记录,另外编译器在ssa过程中会预留defer空间。
-
open coded开放编码模式。open coded 就是 go 1.14 新增的模式。
// xiaorui.cc
func (s *state) stmt(n *Node) {
case ODEFER:
if Debug_defer > 0 {
var defertype string
if s.hasOpenDefers {
defertype = "open-coded"
} else if n.Esc == EscNever {
defertype = "stack-allocated"
} else {
defertype = "heap-allocated"
}
Warnl(n.Pos, "%s defer", defertype)
}
if s.hasOpenDefers {
s.openDeferRecord(n.Left)
} else {
d := callDefer
if n.Esc == EscNever {
d = callDeferStack
}
s.call(n.Left, d)
}
...默认open-coded最多支持8个defer,超过则取消。
cmd/compile/internal/gc/walk.go
// xiaorui.cc
const maxOpenDefers = 8
func walkstmt(n *Node) *Node {
...
switch n.Op {
case ODEFER:
Curfn.Func.SetHasDefer(true)
Curfn.Func.numDefers++
if Curfn.Func.numDefers > maxOpenDefers {
Curfn.Func.SetOpenCodedDeferDisallowed(true)
}
if n.Esc != EscNever {
Curfn.Func.SetOpenCodedDeferDisallowed(true)
}
...
}在构建ssa时如发现gcflags有N禁止优化的参数 或者 return数量 * defer数量超过了 15不适用open-coded模式。
cmd/compile/internal/gc/ssa.go
// xiaorui.cc
func buildssa(fn *Node, worker int) *ssa.Func {
...
var s state
...
s.hasdefer = fn.Func.HasDefer()
...
s.hasOpenDefers = Debug['N'] == 0 && s.hasdefer && !s.curfn.Func.OpenCodedDeferDisallowed()
if s.hasOpenDefers &&
s.curfn.Func.numReturns*s.curfn.Func.numDefers > 15 {
s.hasOpenDefers = false
}
...
}逃逸分析会判断循序的层数,如果有轮询,那么强制使用栈分配模式。
cmd/compile/internal/gc/escape.go
// xiaorui.cc
func (e *Escape) augmentParamHole(k EscHole, call, where *Node) EscHole {
...
if where.Op == ODEFER && e.loopDepth == 1 {
// force stack allocation of defer record, unless open-coded
// defers are used (see ssa.go)
where.Esc = EscNever
return e.later(k)
}
return e.heapHole().note(where, "call parameter")
}总结下open coded的使用条件,defer最多8个,return * defer < 15,无循环,gcflags无 “N” 取消优化。
ssa的构建过程是相当的麻烦,源码也很难理解。简单说golang编译器可在中间代码ssa的过程中优化defer,open-coded模式下把被延迟的方法和deferreturn直接插入到函数尾部。
多数defer看直接被编译器分析优化,但如果一个 defer 发生在一个条件语句中,而这个条件必须等到运行时才能确定。go1.14在open-coded使用延迟比特 (defer bit) 来判断条件分支是否该执行。一个字节8个比特,在open coded里最多8个defer,包括了if判断里的defer。只要有defer关键字就在相应位置设置bit,而在if判断里需要运行时来设置bit,编译器无法控制的。
需要运行时确认defer的例子
if createTime > Now {
defer close(chan) // 运行时确认
}deferreturn的实现
// xiaorui.cc
func deferreturn(arg0 uintptr) {
gp := getg()
// 获取栈顶的_defer
d := gp._defer
sp := getcallersp()
if d.openDefer {
done := runOpenDeferFrame(gp, d)
...
gp._defer = d.link
freedefer(d) // 释放_defer到资源池里
return
}
fn := d.fn
d.fn = nil
gp._defer = d.link
freedefer(d)
// 堆、栈的defer类型会通过jmpdefer递归调用deferreturn
jmpdefer(fn, uintptr(unsafe.Pointer(&arg0)))
}
func runOpenDeferFrame(gp *g, d *_defer) bool {
done := true
// 所有defer信息都存储在funcdata中
fd := d.fd
_, fd = readvarintUnsafe(fd) // 跳过maxargssize
deferBitsOffset, fd := readvarintUnsafe(fd) // deferBits偏移量
nDefers, fd := readvarintUnsafe(fd) // 函数中defer数量
deferBits := *(*uint8)(unsafe.Pointer(d.varp - uintptr(deferBitsOffset))) // 当前执行的defer
for i := int(nDefers) - 1; i >= 0; i-- {
// 从defer中读取funcdata信息
var argWidth, closureOffset, nArgs uint32
argWidth, fd = readvarintUnsafe(fd)
closureOffset, fd = readvarintUnsafe(fd)
nArgs, fd = readvarintUnsafe(fd)
// 执行的函数和参数
closure := *(**funcval)(unsafe.Pointer(d.varp - uintptr(closureOffset)))
d.fn = closure
deferArgs := deferArgs(d)
// 将_defer参数数据拷贝到和_defer关联内存位置
for j := uint32(0); j < nArgs; j++ {
// argCallOffset <= argOffset + argLen
var argOffset, argLen, argCallOffset uint32 // defer参数在栈帧中的偏移量
argOffset, fd = readvarintUnsafe(fd) // 参数大小
argLen, fd = readvarintUnsafe(fd) // 函数调用时,参数在args参数中的位置
argCallOffset, fd = readvarintUnsafe(fd)
memmove(unsafe.Pointer(uintptr(deferArgs)+uintptr(argCallOffset)),
unsafe.Pointer(d.varp-uintptr(argOffset)),
uintptr(argLen))
}
// 通过位移操作,移到下一个defer执行位置
deferBits = deferBits &^ (1 << i)
*(*uint8)(unsafe.Pointer(d.varp - uintptr(deferBitsOffset))) = deferBits
reflectcallSave(p, unsafe.Pointer(closure), deferArgs, argWidth)
if p != nil && p.aborted {
break
}
d.fn = nil
...
}
return done
}defer的代码由于涉及到很多的编译操作,所以苦涩难懂。对于defer的原理有个大概理解就可以了,open codeed的优化主要集中在ssa,而ssa又枯涩难理解 😅。
好奇为什么open coded最多只支持8个defer,看起来扩充字节做延迟比特控制应该也可以的。