基于 badger
v4.0.1进行源码分析
badgerDB 是 golang 社区中性能排头部的 kv 存储引擎, badger 支持 wisckey 大value存储分离, SSI 隔离的事务, MVCC, 并发合并等等特性.
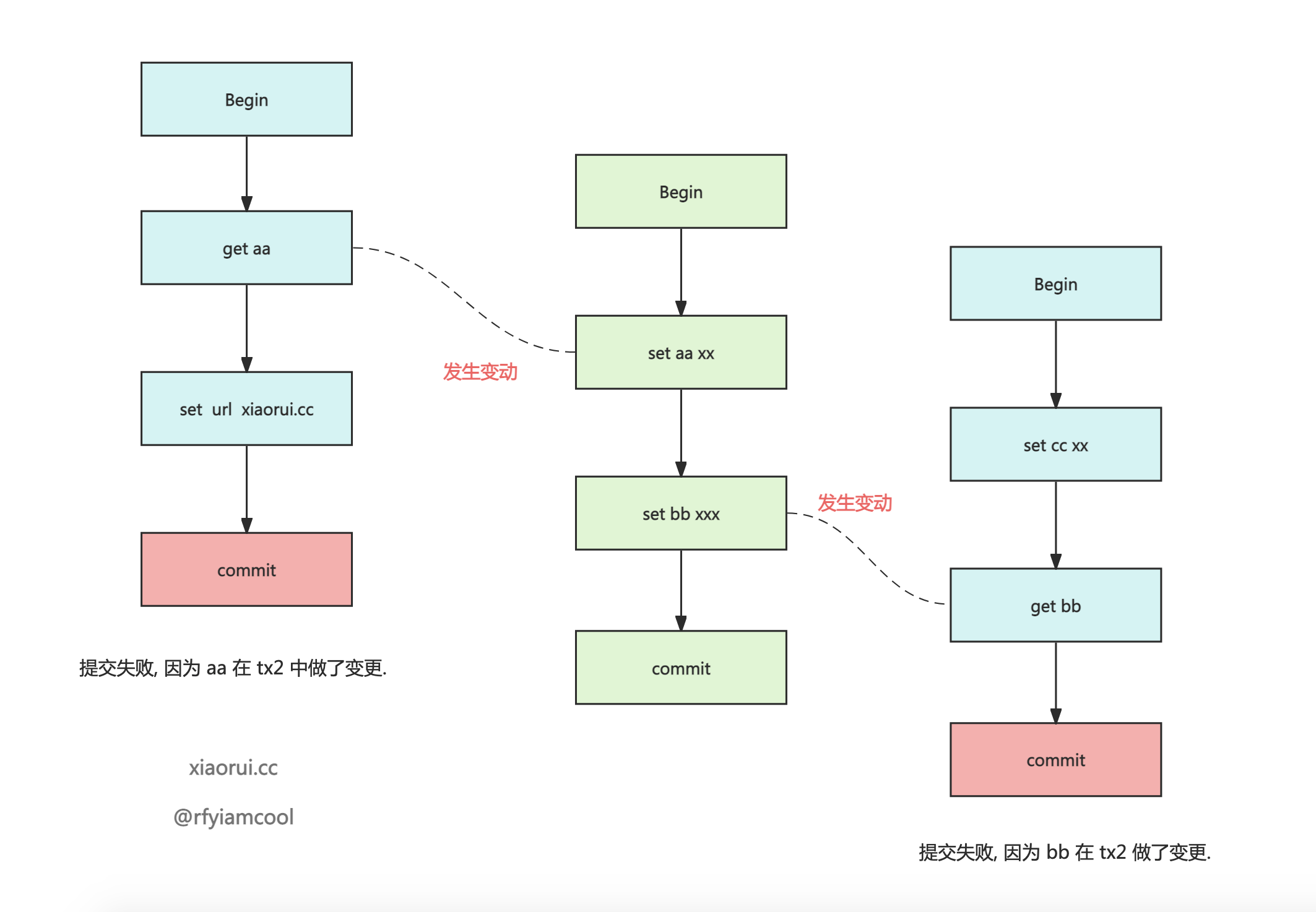
本文主要分析 badger 读写下的事务的实现原理. golang badger 实现了 Serializable Snapshot Isolation 隔离级别的乐观并发控制事务模型. SSI 其原理是在事务读写操作时, 实现了跟踪记录读写操作, 在事务 Commit 提交时进行事务冲突检查. 检测的方法是如果当前事务中读取过的键key, 在事务执行的期间被其他事务修改过, 那么则会提交失败.
需要说明是 mysql serializable 事务级别使用了锁进行串行化操作, 而 PostgreSQL 则使用了 Serializable Snapshot Isolation 的乐观事务机制, 只有在提交时才会进行事务冲突检测, ssi 的事务模型是支持并发操作的. 另外 badger 的 ssi 的实现要比 pg 简单不少.
golang badger kv 存储引擎实现原理系列的文章地址 (更新中)
https://github.com/rfyiamcool/notes#golang-badger
下面是使用 db.Update() 事务进行读写的 db 的例子. db.View 是只读事务, 传入的事务处理方法只能是 Get(), 如果使用 Set() 则直接异常. db.Update 是可以进行读写事务, 不仅可以读, 也可以写.
package main
import (
"fmt"
badger "github.com/dgraph-io/badger/v3"
)
func main() {
db, err := badger.Open(badger.DefaultOptions("/tmp/xiaorui.cc/badger"))
defer db.Close()
err = db.Update(func(txn *badger.Txn) error {
// do something
// ...
// set
txn.Set([]byte("url"), []byte("xiaorui.cc"))
// get
txn.Get([]byte("url"))
return nil
})
if err != nil {
panic(err.Error())
}
}Update 内部会创建更新用的 txn, 再调用传入事务方法, 最后执行自动提交, 执行失败则通过 defer 来销毁事务.
func (db *DB) Update(fn func(txn *Txn) error) error {
// 已关闭, 返回错误.
if db.IsClosed() {
return ErrDBClosed
}
// 这里不能为 true.
if db.opt.managedTxns {
panic("Update can only be used with managedDB=false.")
}
// 创建一个事务, true 为可更新.
txn := db.NewTransaction(true)
// 延后执行安全销毁
defer txn.Discard()
// 调用传入的 fn, 传入 txn
if err := fn(txn); err != nil {
return err
}
// 提交事务
return txn.Commit()
}Set 写操作只是把数据写到 txn pendingWrites 中, 其实没有真正的去执行写操作.
Set 流程如下.
- 把待写入的 key 的 hash 值存到 txn 的 conflictKeys 里.
- 把待写入的 entry 写到 txn 的 pendingWrites 待写入字典容器里.
badgerDB 的写操作是需要在事务中进行的.
// 写入和更新数据
func (txn *Txn) Set(key, val []byte) error {
return txn.SetEntry(NewEntry(key, val))
}
// 删除数据
// 删除也是使用 txn.modify 来更新数据, 只是 meta 为 bitDelete.
func (txn *Txn) Delete(key []byte) error {
e := &Entry{
Key: key,
meta: bitDelete,
}
return txn.modify(e)
}
func (txn *Txn) SetEntry(e *Entry) error {
return txn.modify(e)
}
func (txn *Txn) modify(e *Entry) error {
const maxKeySize = 65000
// ...
// 是否禁止该 key
if err := txn.db.isBanned(e.Key); err != nil {
return err
}
// 检查 key size
if err := txn.checkSize(e); err != nil {
return err
}
// 通过 `runtime.memhash` 计算 key 的hash值, 然后写到 txn 的 conflictKeys 字典里.
if txn.db.opt.DetectConflicts {
fp := z.MemHash(e.Key)
txn.conflictKeys[fp] = struct{}{}
}
// 写过多次, 则把旧值写到 duplicateWrites 字典里.
if oldEntry, ok := txn.pendingWrites[string(e.Key)]; ok && oldEntry.version != e.version {
txn.duplicateWrites = append(txn.duplicateWrites, oldEntry)
}
// 把写入的 entry 写到待写入字典里 pendingWrites 里.
txn.pendingWrites[string(e.Key)] = e
return nil
}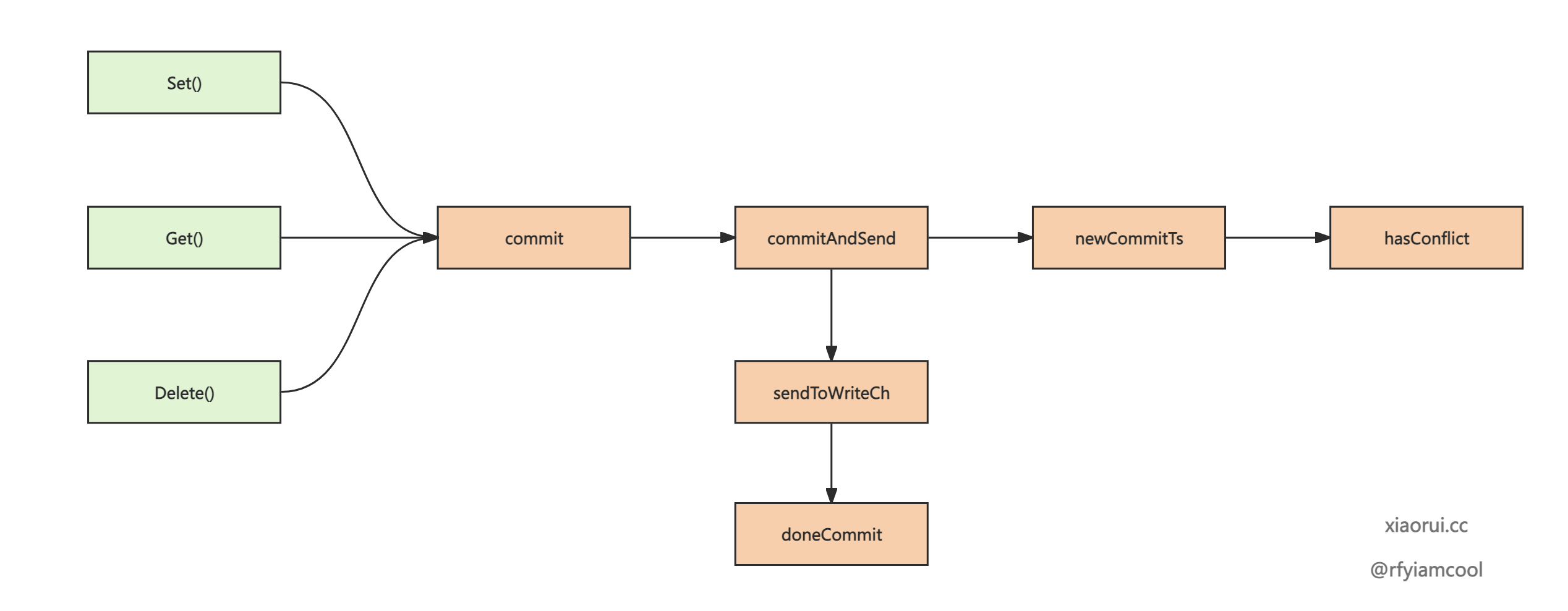
不管是 Set 和 Delete 操作, 只要没有提交事务, 那么写入的 kv 都只是存储在 txn 里. 只有在 commit 提交事务时, 才会真正的写入 kv.
Commit 用来检测事务是否有冲突, 在无冲突下进行事务提交, 最后移动水位线.
func (txn *Txn) Commit() error {
// pendingWrites 为空, 说明当前事务无更新.
if len(txn.pendingWrites) == 0 {
return nil // Nothing to do.
}
// 检测是否被关闭
if err := txn.commitPrecheck(); err != nil {
return err
}
defer txn.Discard()
// 提交事务, 写入数据
txnCb, err := txn.commitAndSend()
if err != nil {
return err
}
// 等待事务执行完毕, 无异常下移动水位线.
return txnCb()
}commitAndSend 为 Commit 的核心方法, 首先判断当前事务是否有冲突, 接着把 entries 写到如 db.writeCh 里, 最后调用 doneCommit 来移动水位线.
func (txn *Txn) commitAndSend() (func() error, error) {
// 获取事务对应的全局 oracle
orc := txn.db.orc
// 加锁保证线程安全
orc.writeChLock.Lock()
defer orc.writeChLock.Unlock()
// 获取 commitTS, 并检测当前事务是否跟全局活动事务表中事务产生冲突.
commitTs, conflict := orc.newCommitTs(txn)
if conflict {
return nil, ErrConflict
}
setVersion := func(e *Entry) {
if e.version == 0 {
e.version = commitTs
} else {
keepTogether = false
}
}
for _, e := range txn.pendingWrites {
// 配置 key 的 version.
setVersion(e)
}
for _, e := range txn.duplicateWrites {
setVersion(e)
}
// 实例化 entries 对象
entries := make([]*Entry, 0, len(txn.pendingWrites)+len(txn.duplicateWrites)+1)
processEntry := func(e *Entry) {
// key 的后面追加 version
e.Key = y.KeyWithTs(e.Key, e.version)
entries = append(entries, e)
}
// 组装 pendingWrites 键值
for _, e := range txn.pendingWrites {
processEntry(e)
}
// 组装 duplicateWrites 键值
for _, e := range txn.duplicateWrites {
processEntry(e)
}
// ...
req, err := txn.db.sendToWriteCh(entries)
if err != nil {
// 更新水位线
orc.doneCommit(commitTs)
return nil, err
}
// 等待 keys 写入完成, 更新事务的水位线.
ret := func() error {
err := req.Wait()
orc.doneCommit(commitTs)
return err
}
return ret, nil
}newCommitTs 用来检测传入的事务是否跟活跃事务集有冲突, 无冲突下, 返回一个事务时间.
func (o *oracle) newCommitTs(txn *Txn) (uint64, bool) {
// 对 oracle 加锁, oracle 是全局的.
o.Lock()
defer o.Unlock()
// 检测传入的txn是否跟 oracle 记录的事务有冲突.
if o.hasConflict(txn) {
return 0, true
}
var ts uint64
if !o.isManaged { // 通常都为 false 的.
o.doneRead(txn)
// 清理过期事务
o.cleanupCommittedTransactions()
// 获取新的事务 ts
ts = o.nextTxnTs
o.nextTxnTs++
o.txnMark.Begin(ts)
} else {
ts = txn.commitTs
}
// 如果开启冲突检测
if o.detectConflicts {
// 把当前事务放到 oracle 的 committedTxns 中.
o.committedTxns = append(o.committedTxns, committedTxn{
ts: ts,
conflictKeys: txn.conflictKeys,
})
}
// 返回当前事务ts, 无冲突
return ts, false
}
hasConflict 用来检测是否有事务冲突. 其逻辑如下.
- 遍历 oracel 事务管理器中已提交的事务, 如果遍历到的事务结束 ts 小于等于 当前事务的 readTs 则跳过.
- 如果当前事务跟遍历的事务 committedTxn 有时间重叠, 那么需要判断 committedTxn 是否含有传入 txn 的 reads 的 keys.
- 有, 则说明发生了事务冲突.
func (o *oracle) hasConflict(txn *Txn) bool {
// 事务的读列表为空则跳出.
if len(txn.reads) == 0 {
return false
}
// 遍历 oracle 存在的已提交事务
for _, committedTxn := range o.committedTxns {
// 如果遍历到的事务结束 ts 小于等于 当前事务的 readTs 则跳过.
if committedTxn.ts <= txn.readTs {
continue
}
// 判断当前事务的 read keys 集合是否在于 committedTxn 中.
for _, ro := range txn.reads {
if _, has := committedTxn.conflictKeys[ro]; has {
// 存在说明有事务冲突.
return true
}
}
}
// 无冲突
return false
}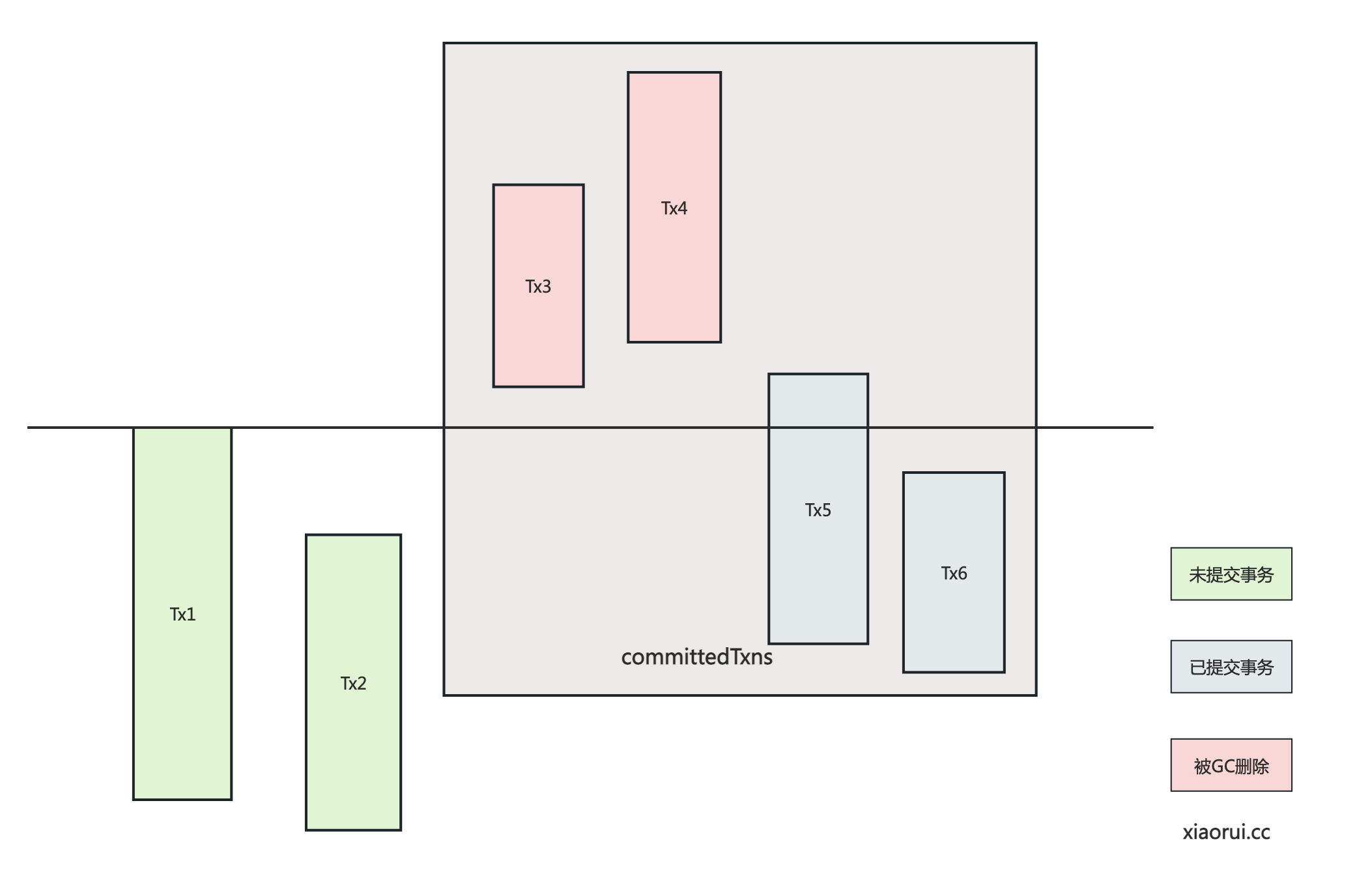
cleanupCommittedTransactions 用来清理已提交事务集合里处于低水位线的事务集合. 避免在判断冲突事务时, 因遍历过多的 committedTxns 事务, 造成多余的性能开销.
比如, 当前活跃的事务集合中最小开始时间为 T100, 那么在 committedTxns 删除小于 T100 的事务.
func (o *oracle) cleanupCommittedTransactions() { // Must be called under o.Lock
// 无需处理冲突
if !o.detectConflicts {
return
}
var maxReadTs uint64
if o.isManaged {
maxReadTs = o.discardTs
} else {
// 水位线, readMark 是一个堆结构, 从堆里获取获取事务中最小事务的时间.
maxReadTs = o.readMark.DoneUntil()
}
// 断言
y.AssertTrue(maxReadTs >= o.lastCleanupTs)
// 一样则跳出
if maxReadTs == o.lastCleanupTs {
return
}
// 把当前记录的 ts 赋值到 lastCleanupTs
o.lastCleanupTs = maxReadTs
// 遍历已提交的 txn 事务,
tmp := o.committedTxns[:0]
for _, txn := range o.committedTxns {
// 比水位线小, 需要被删除, 也就是忽略.
if txn.ts <= maxReadTs {
continue
}
// 比水位线高则保留
tmp = append(tmp, txn)
}
// 重新赋值
o.committedTxns = tmp
}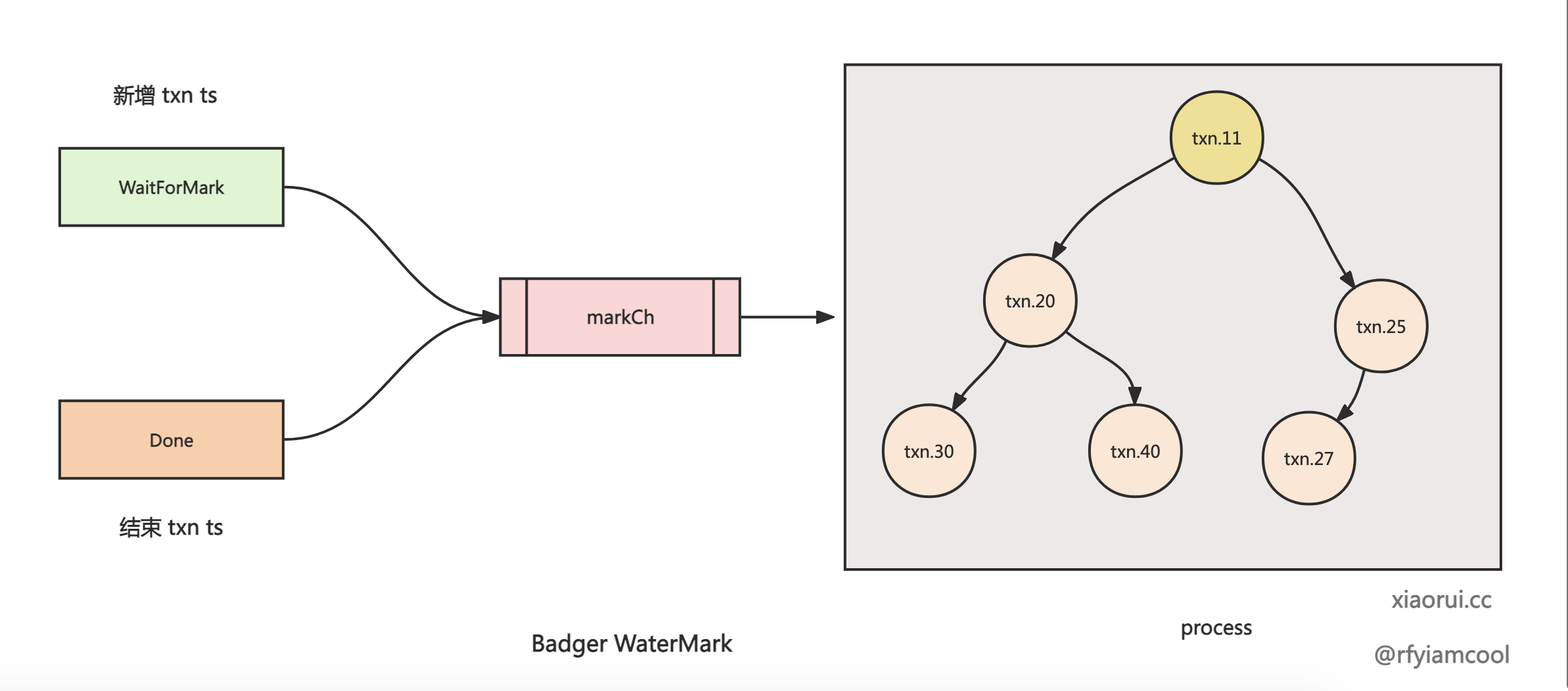
waterMark 保存了当前 badger 里的所有活跃事务的 ts. 开始事务的时候需要添加 readTs 到 waterMark 里, 事务在执行后 Done 时添加 commitTs 到 waterMark 里. waterMark 在经过堆排序后, 取最小的 ts 为 doneUtil 值. badger 在进行事务清理时, 会以 waterMark 水位线的 doneUntil 为基准, 删除之前的已提交事务.
另外 readTs 为事务的创建时间, commitTs 为事务的结束时间. 这里的时间不是物理时钟的时间, 而是逻辑递增的时间序列.
源码位置: badger/y/watermark.go
badger 中的事务实现的原理还是相对好理解的, badger 在事务中追踪记录写操作的 keys, 在事务提交时会做事务冲突检测.
事务冲突检测方法会检测当前提交事务内曾读取过的 keys, 在事务执行期间是否被其他事务更改过, 改过那么就算冲突, 不能写入, 上层可以进行重试.
- badgerdb 的所有操作都是以事务的方式进行的.
- badgerdb set 和 delete 写操作, 只有在 commit 提交时才会真正的去写 db, 之前都是存储在 txn 中.
- badgerdb oracle 在 badger 里不仅实现了授时服务, 就是事务的时间生成, 还实现了类似事务管理器, 其内部维护了一段时间内的已提交事务, 用来做事务在提交时的冲突检测.
- waterMark 用来维护当前活动事务的水位线, 内部使用小顶堆排序事务ts, 主要目的用来事务的 gc 回收.