基于 badger
v4.0.1进行源码分析
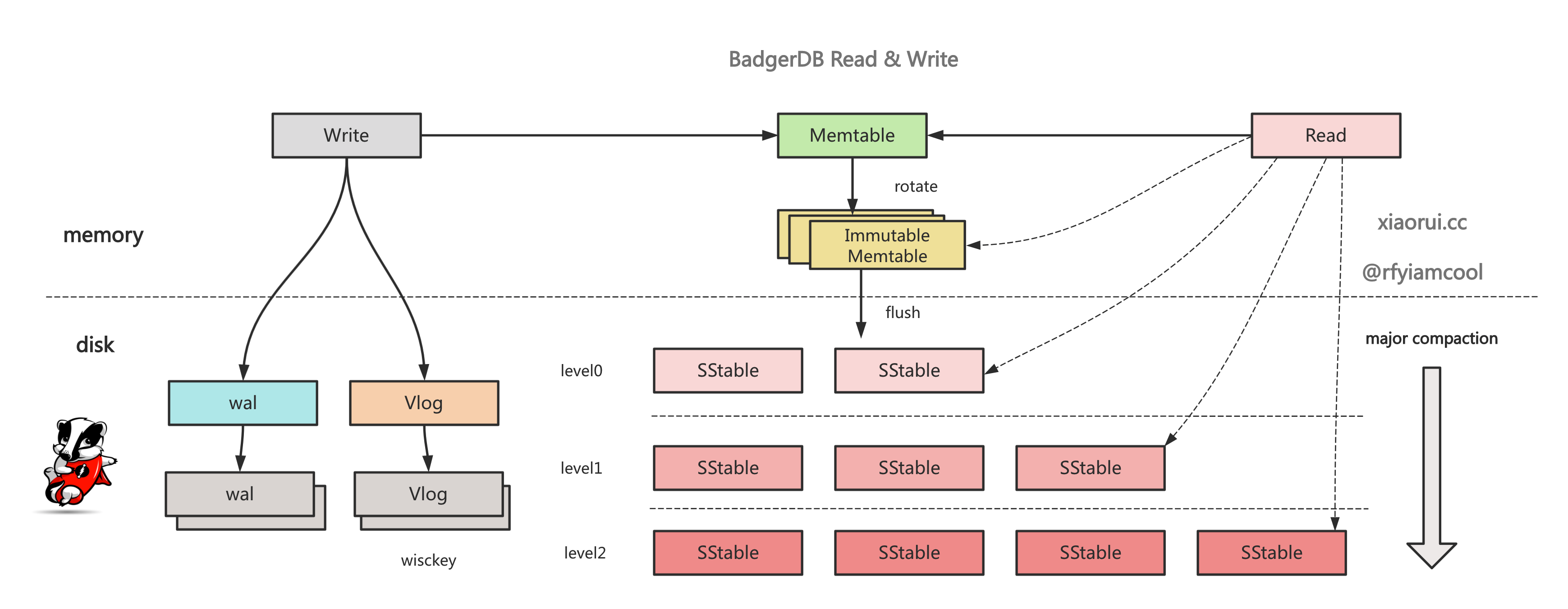
badger 读取的过程跟其他基于 lsm tree 实现的数据库基本一致. 先从 memtable 集合里查找, 然后再从 immutable memtables 集合里查找, 接着从上往下从 levels 各层进行查找.
level 0 层会有 key 范围重叠的情况, 所以要从所有符合条件的 sstable, 进行遍历查找. 到了 level 1 层后, 通过二分查找算法找到符合 key 范围的 sstable, level >= 1 层最多只有一个 sstable 满足 key 范围条件.
sstable 内部的查询是先从 bloomfilter 布隆过滤器中查询, 如果命中说明可能存在, 毕竟 bf 存在假阳的概率, 继续找到对应的 block, block 内部有个有序 offset 集合做二分查找. 只有没找到, 就一直往下面的 level 进行遍历查找, 直到成功.
go badgerdb 的读写流程
golang badger kv 存储引擎实现原理系列的文章地址 (更新中)
https://github.com/rfyiamcool/notes#golang-badger
// Get looks for key and returns corresponding Item.
// If key is not found, ErrKeyNotFound is returned.
func (txn *Txn) Get(key []byte) (item *Item, rerr error) {
// 判空
if len(key) == 0 {
return nil, ErrEmptyKey
} else if txn.discarded {
// 如果事务已销毁, 则没必要读取直接退出.
return nil, ErrDiscardedTxn
}
// 判断是否被 isBanned
if err := txn.db.isBanned(key); err != nil {
return nil, err
}
item = new(Item)
if txn.update {
// 如果事务有开启更新, 则先尝试从 pendingWrites 读取待写入的数据.
if e, has := txn.pendingWrites[string(key)]; has && bytes.Equal(key, e.Key) {
// 如果是删除标签, 则直接报错
if isDeletedOrExpired(e.meta, e.ExpiresAt) {
return nil, ErrKeyNotFound
}
// 拼装数据
item.meta = e.meta
item.val = e.Value
item.userMeta = e.UserMeta
item.key = key
item.status = prefetched
item.version = txn.readTs
item.expiresAt = e.ExpiresAt
return item, nil
}
// 把读取的 key 放到事务的 reads 里.
// 当事务提交时会, 依赖 reads 实现事务冲突检测.
txn.addReadKey(key)
}
// 在查询的 key 后面追加事务版本.
seek := y.KeyWithTs(key, txn.readTs)
// 从 kv 里获取数据
vs, err := txn.db.get(seek)
if err != nil {
return nil, y.Wrapf(err, "DB::Get key: %q", key)
}
if vs.Value == nil && vs.Meta == 0 {
return nil, ErrKeyNotFound
}
// 如果 key 已过期, 则返回 notFound
if isDeletedOrExpired(vs.Meta, vs.ExpiresAt) {
return nil, ErrKeyNotFound
}
// 构建返回给上层的 item
item.key = key
item.version = vs.Version
item.meta = vs.Meta
item.userMeta = vs.UserMeta
item.vptr = y.SafeCopy(item.vptr, vs.Value)
item.txn = txn
item.expiresAt = vs.ExpiresAt
return item, nil
}这里涉及到了 badger ssi 乐观事务隔离的设计. badger ssi 事务冲突检测的方法是如果当前事务中读取过的键key, 在事务执行的期间被其他事务修改过, 那么则会提交失败. 比如多个时间线有重叠的事务, 如果事务 txn1 读取的 key 被其他事务更改, 那么 txn1 提交失败.
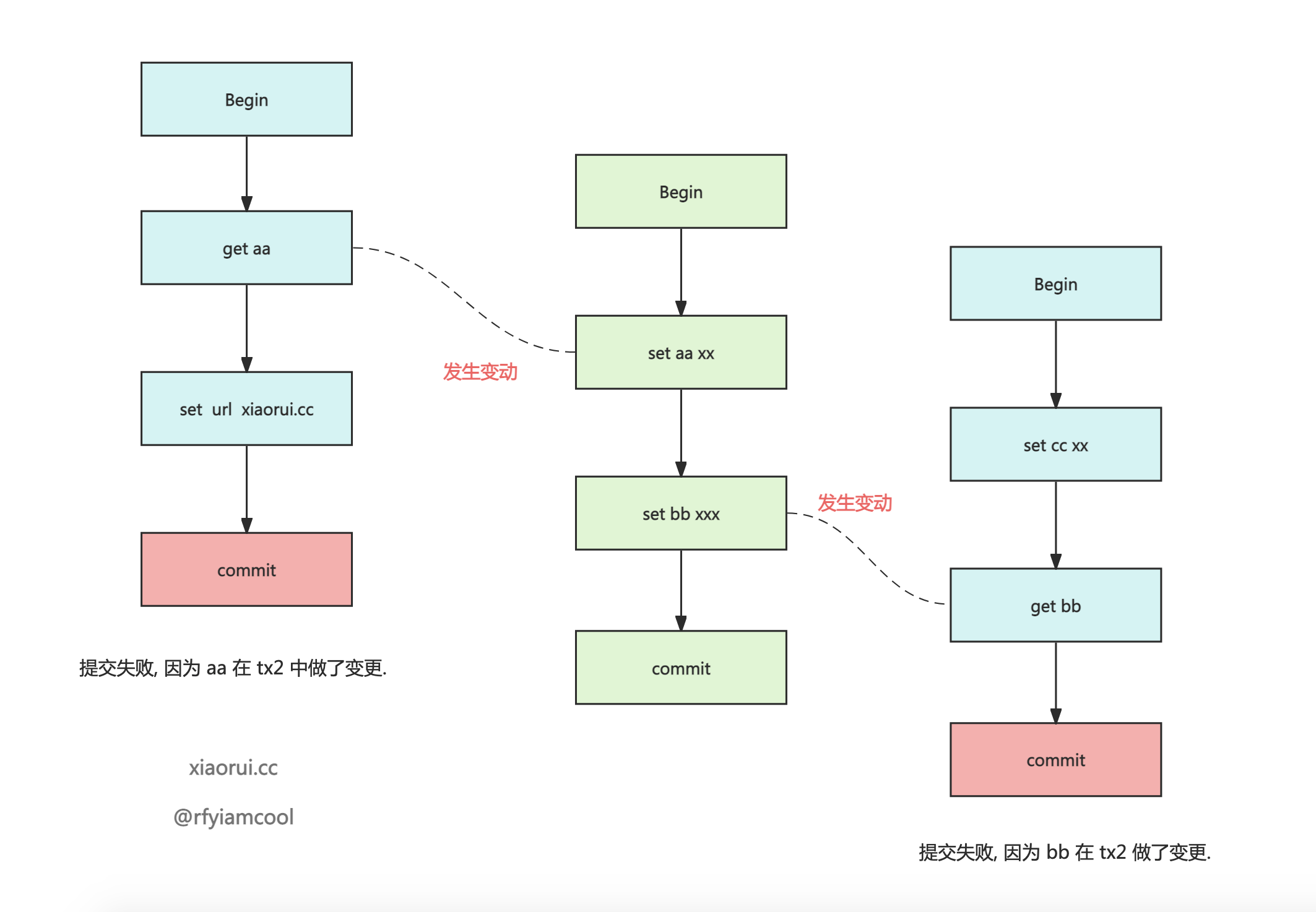
把 key 放到事务的 reads 集合里, 如果事务是 Update 事务模式, 那么在提交时会做事务冲突检测.
func (txn *Txn) addReadKey(key []byte) {
if txn.update {
fp := z.MemHash(key)
txn.readsLock.Lock()
txn.reads = append(txn.reads, fp)
txn.readsLock.Unlock()
}
}在 key 的后面追加事务的版本, 用以实现 mvcc 多版本.
func KeyWithTs(key []byte, ts uint64) []byte {
out := make([]byte, len(key)+8)
copy(out, key)
binary.BigEndian.PutUint64(out[len(key):], math.MaxUint64-ts)
return out
}通过 key 的 meta 判断是否被标记删除, expiresAt 判断是否过期.
func isDeletedOrExpired(meta byte, expiresAt uint64) bool {
// 删除标签
if meta&bitDelete > 0 {
return true
}
// 没有配置过期
if expiresAt == 0 {
return false
}
// 判断是否满足过期
return expiresAt <= uint64(time.Now().Unix())
}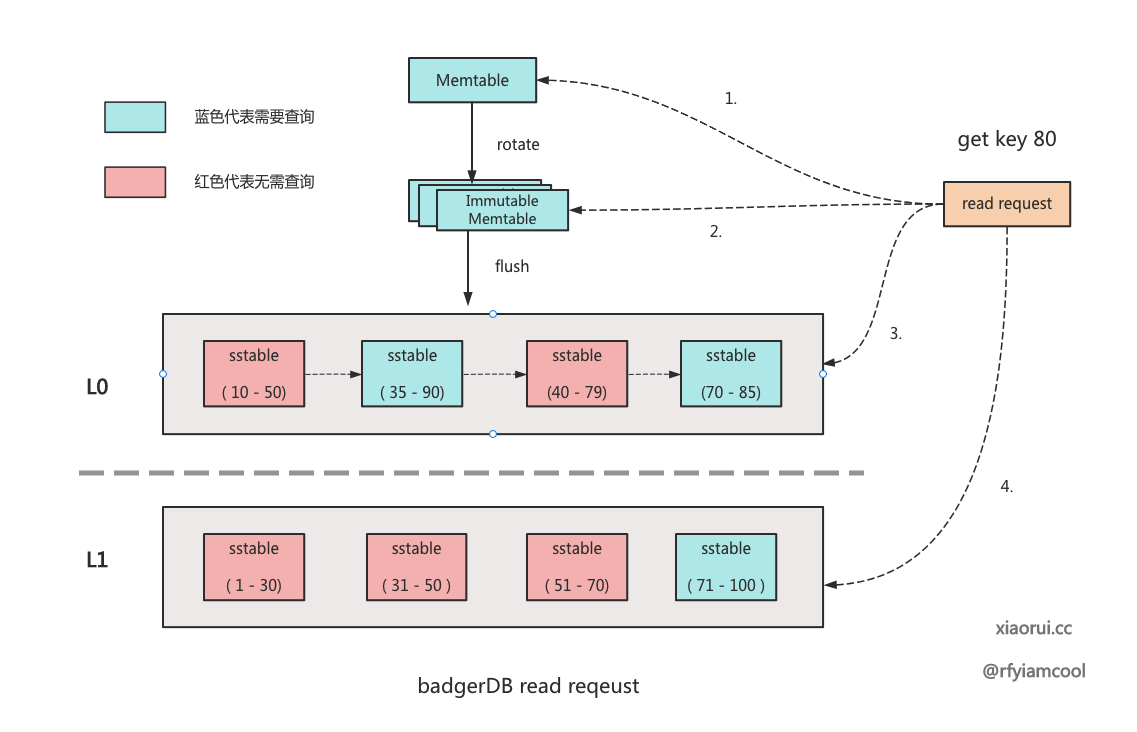
db.get 用来获取数据, 其查询路径是先从 memtable 集合里获取, 如果拿不到再从上往下到 levels 的各级 sstables 里获取.
func (db *DB) get(key []byte) (y.ValueStruct, error) {
if db.IsClosed() {
return y.ValueStruct{}, ErrDBClosed
}
// 获取当前 db 的 memtable.
tables, decr := db.getMemTables() // Lock should be released.
// 减少引用关系, flush 时需要判断对象的引用关系是否为空.
defer decr()
var maxVs y.ValueStruct
// 从 key 中读取 version, 后 8 个字节为大端编码的 verison
version := y.ParseTs(key)
// tables 数组第一个是当前激活的 table, 后面为不可变的 immutable memtable 集合.
for i := 0; i < len(tables); i++ {
// 从 skiplist 跳表中获取 ValueStruct
vs := tables[i].sl.Get(key)
// 该 key 已被标记
if vs.Meta == 0 && vs.Value == nil {
continue
}
if vs.Version == version {
return vs, nil
}
if maxVs.Version < vs.Version {
maxVs = vs
}
}
// 从 levelsController 读取数据, 也就是从各层的 level 读取数据.
return db.lc.get(key, maxVs, 0)
}返回一个 memtable 集合, 先 append 当前可写的 memtable, 再按照时间倒序来 append immutable memtable 集合.
lsm tree 的读取顺序是先 memtable, 然后再按照时间的新旧来读取 immutable memtable.
// getMemtables returns the current memtables and get references.
func (db *DB) getMemTables() ([]*memTable, func()) {
db.lock.RLock()
defer db.lock.RUnlock()
var tables []*memTable
if !db.opt.ReadOnly {
// 添加当前的 memtable
tables = append(tables, db.mt)
db.mt.IncrRef()
}
last := len(db.imm) - 1
for i := range db.imm {
// 按照新旧顺序添加不可变只读的 memtable
tables = append(tables, db.imm[last-i])
db.imm[last-i].IncrRef()
}
return tables, func() {
// 解除引用计数
// badger 内部大量的使用 ref 的概念, 当为 0 时, 那么 badger gc 就会删除.
for _, tbl := range tables {
tbl.DecrRef()
}
}
}get 是从上往下到各级 level 获取数据, badger 每个 level 抽象了 levelHandler 对象, 在 eventHandler 里实现了 tables 的管理及 get 接口.
代码位置: badger/levels.go
func (s *levelsController) get(key []byte, maxVs y.ValueStruct, startLevel int) (
y.ValueStruct, error) {
if s.kv.IsClosed() {
return y.ValueStruct{}, ErrDBClosed
}
// 从 key 后 8 位获取事务的版本.
version := y.ParseTs(key)
for _, h := range s.levels {
// 从 startLevel 开始, 之前的 level 被清理.
if h.level < startLevel {
continue
}
// 从 levelHandler 里获取数据, 其实就是从 level 的 tables 里获取数据.
vs, err := h.get(key)
if err != nil {
return y.ValueStruct{}, y.Wrapf(err, "get key: %q", key)
}
// 空, 则跳过
if vs.Value == nil && vs.Meta == 0 {
continue
}
// 版本过滤, 一致时返回.
if vs.Version == version {
return vs, nil
}
if maxVs.Version < vs.Version {
maxVs = vs
}
}
return maxVs, nil
}levelHandler 实现了 get 接口了, 其内部先获取可能含有该 key 的 sstable 集合, 然后遍历依次 sstables, 先从 bloomfilter 判断是否命中, 如命令则开启 iterator 迭代器获取 kv.
代码位置: badger/level_handler.go
// get returns value for a given key or the key after that. If not found, return nil.
func (s *levelHandler) get(key []byte) (y.ValueStruct, error) {
// 获取可能含有 key 的 tables 集合.
tables, decr := s.getTableForKey(key)
// 原始 key
keyNoTs := y.ParseKey(key)
// 求原始 key 的 hash 值
hash := y.Hash(keyNoTs)
// 定义返回值
var maxVs y.ValueStruct
// L0 层的话, 需要遍历所有符合范围的 table
// 而 L1+N 层通常只有一个 table 满足需求.
for _, th := range tables {
// 从 table 的 bloomfilter 里判断是否有数据, 存在假真的可能
// 但 bf false 就是没有.
if th.DoesNotHave(hash) {
continue
}
// 创建 table 的 iterator 迭代器
it := th.NewIterator(0)
defer it.Close()
// 这里的 seek 的实现有些复杂, 不是 file seek 定位逻辑.
// 直接从 sstable 里找到符合条件的 block, 继而再从 block 找到 entry.
it.Seek(key)
// 有异常则跳过
if !it.Valid() {
continue
}
// 如果迭代器拿到的 key 跟传入 key 相同, 且版本更小则赋值到 maxVs.
if y.SameKey(key, it.Key()) {
if version := y.ParseTs(it.Key()); maxVs.Version < version {
// 赋值 valueStruct
maxVs = it.ValueCopy()
// 赋值版本
maxVs.Version = version
}
}
}
// 返回获取的 valueStruct 和减少引用的回调方法.
return maxVs, decr()
}getTableForKey 用来获取覆盖 key 范围的 sstable 集合. 按照 lsm tree 的设计, 在 Level 0 层的 sstable 会有 key 重叠, 但 Level1+N 层的 sstable 会跟他的上层 sstable 做 compact 合并, 所以 Level1+N 层的 sstable 的 key 范围是不会重叠的, 这些 sstable 是可以通过二分查找算法找到 key 对应的 sstable.
所以, 参照上面所述的 lsm tree 的设计原理, 很容易理解 getTableForKey 的逻辑.
- 如果 levelHandler 是 Level 0 层, 则返回所有符合 key 范围的 table, 可能就一个 table, 也可能是所有的 sstable.
- 如果 levelHandler 是 Level 1 + N 层, 则使用二分查找算法找到对应的 sstable, 只有一个 table, 也必须是一个.
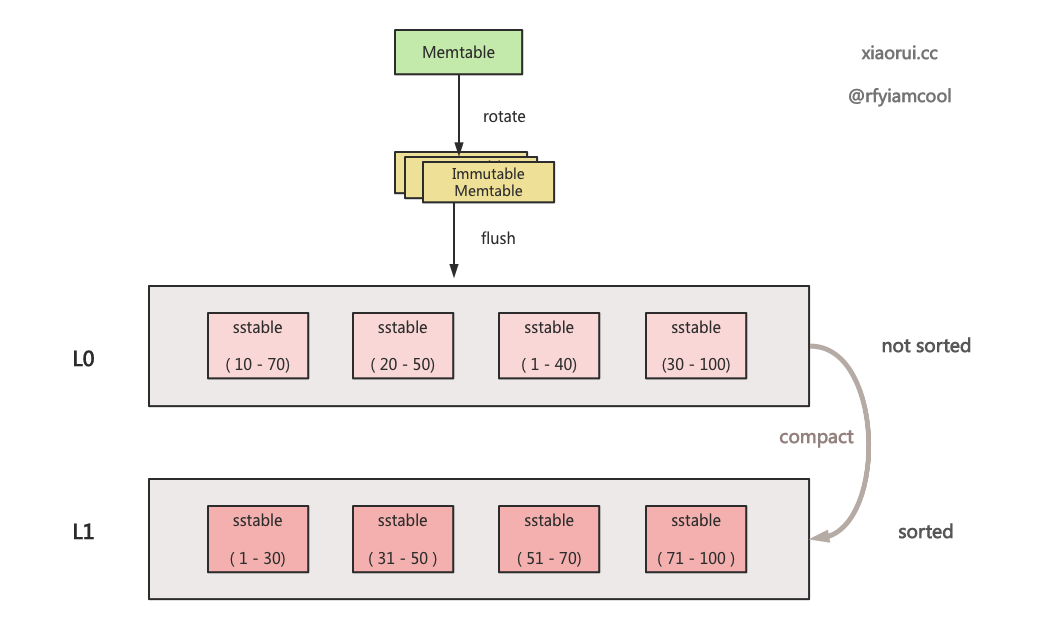
badger 的实现相比 rocksdb 还是差点, rocksdb 不是简单的二分查找, 而是有层级关系的二分查找.
// getTableForKey acquires a read-lock to access s.tables. It returns a list of tableHandlers.
func (s *levelHandler) getTableForKey(key []byte) ([]*table.Table, func() error) {
// 加读锁, 安全操作
s.RLock()
defer s.RUnlock()
if s.level == 0 {
// 对于 level 0 层来说, 由于 sstable 未进行 compact, key 的范围会有重叠, 所有需要检查每个表. 返回的 tables 需要分配一个新的, 另外 tables 需要倒序 append.
out := make([]*table.Table, 0, len(s.tables))
for i := len(s.tables) - 1; i >= 0; i-- {
out = append(out, s.tables[i])
// 添加 table 的引用
s.tables[i].IncrRef()
}
return out, func() error {
// 返回一个回调方法, 递减 tables 的引用值.
for _, t := range out {
if err := t.DecrRef(); err != nil {
return err
}
}
return nil
}
}
// 当 Level >= 0, 我们可以进行二分搜索, 因为键范围不重叠
idx := sort.Search(len(s.tables), func(i int) bool {
// 求出覆盖 key 范围内的 sstable, 每个 table 有个 key 的最大值.
return y.CompareKeys(s.tables[i].Biggest(), key) >= 0
})
// 判断溢出的可能
if idx >= len(s.tables) {
return nil, func() error { return nil }
}
// 拿到符合 key 范围的 table, 对 table 递增引用值
tbl := s.tables[idx]
tbl.IncrRef()
// 返回 table 和解除引用回调方法.
return []*table.Table{tbl}, tbl.DecrRef
}func (t *Table) DoesNotHave(hash uint32) bool {
if !t.hasBloomFilter {
return false
}
// 获取 bf 的 []byte, 新从 indexCache 里拿, 如果没有则从 sstable 里捞.
index := t.fetchIndex()
bf := index.BloomFilterBytes()
// bloomfilter 判断方法, 内部会进行 k := f[len(f)-1] 次计算, 只要有一个 false,那么就不存在.
mayContain := y.Filter(bf).MayContain(hash)
// 取反值, true 为 不含有, false 为含有.
return !mayContain
}fetchIndex 用来获取该 table 对应的 bloomfilter 的数据, 先尝试从缓存里拿, 没有则从 sstable 里面获取, 拿到后重新赋值到缓存中. 这里的缓存是使用 badger 自家的 ristretto 高性能缓存库实现, 内部使用 mmap 和大块 []byte 索引分配来避免 golang 的 gc 的开销.
func (t *Table) fetchIndex() *fb.TableIndex {
// 先尝试从cache里面获取
if val, ok := t.opt.IndexCache.Get(t.indexKey()); ok && val != nil {
return val.(*fb.TableIndex)
}
// 缓存没有则从 sstable 文件里获取.
index, err := t.readTableIndex()
y.Check(err)
t.opt.IndexCache.Set(t.indexKey(), index, int64(t.indexLen))
return index
}至于 bloomfilter 的原理没什么可说的, badger bf 内部会进行 k := f[len(f)-1] 次计算, 只要有一个 false,那么就说明 key 绝对不存在, 如果都命中, 根据 bf 的设计必然会有假阳性的存在, key 可能存在, 也可能不存在.
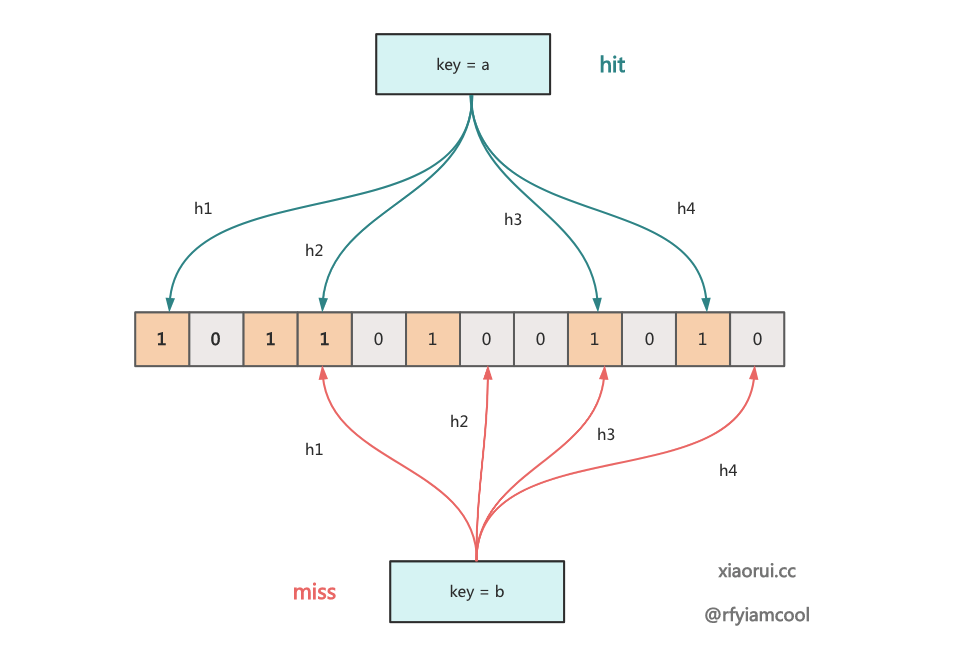
seekFrom 方法用来在 sstable 里获取 entry. 其内部先使用二分查找算法在 sstable 里找到 block, 然后依然使用二分算法从对应的 block 中找到对应的 entry.
代码位置: badger/iterator.go:seekFrom()
// seekFrom brings us to a key that is >= input key.
func (itr *Iterator) seekFrom(key []byte, whence int) {
itr.err = nil
switch whence {
case origin:
itr.reset()
case current:
}
// 从 sstable 中找到符合 key 范围的 block 数据块.
var ko fb.BlockOffset
idx := sort.Search(itr.t.offsetsLength(), func(idx int) bool {
// table 的 offsets 保存了各个 block 的位置
y.AssertTrue(itr.t.offsets(&ko, idx))
// 拿 block 的第一个值, 也就是 smallest 最小值跟传入的 key 对比.
// 如果比 key 大, 则 compare 值大于 0.
return y.CompareKeys(ko.KeyBytes(), key) > 0
})
if idx == 0 {
itr.seekHelper(0, key)
return
}
// 由于使用 block smallest 对比, 所以要前挪动一位.
itr.seekHelper(idx-1, key)
if itr.err == io.EOF {
// 处理异常
itr.seekHelper(idx, key)
}
}seekHelper 根据 blockIdx 获取 block 数据块, 并使用 block 的 seek 进行数据查找.
代码位置: badger/iterator.go:seekHelper()
func (itr *Iterator) seekHelper(blockIdx int, key []byte) {
itr.bpos = blockIdx
block, err := itr.t.block(blockIdx, itr.useCache())
if err != nil {
itr.err = err
return
}
itr.bi.tableID = itr.t.id
itr.bi.blockID = itr.bpos
itr.bi.setBlock(block)
itr.bi.seek(key, origin)
itr.err = itr.bi.Error()
}blockIterator.seek 用来从 sstable 的 block 中找到具体的 entry index, entryOffsets 保存了 block 中的各个 entry 的索引位置, 该 entryOffsets 必然是有序的, 通过二分查找算法找到 entry 对应的 offset, 在 setIdx 里实现数据编解码和读取.
代码位置: badger/iterator.go:seek()
// seek brings us to the first block element that is >= input key.
func (itr *blockIterator) seek(key []byte, whence int) {
itr.err = nil
startIndex := 0 // This tells from which index we should start binary search.
switch whence {
case origin:
// We don't need to do anything. startIndex is already at 0
case current:
startIndex = itr.idx
}
foundEntryIdx := sort.Search(len(itr.entryOffsets), func(idx int) bool {
// If idx is less than start index then just return false.
if idx < startIndex {
return false
}
// 配置迭代器的位置, 把获取的 value 放到 iter 的 value
itr.setIdx(idx)
return y.CompareKeys(itr.key, key) >= 0
})
// 配置迭代器的位置, 把获取的 value 放到 iter 的 value
itr.setIdx(foundEntryIdx)
}badger 的内部大量在使用 ref 引用计数的概念, 每次使用前原子加一, 完成后解除引用. 只要不为空, 那么 badger 内部就不会删除, 反之当 ref 为 0 时, badger 会发起删除操作.
badger 内部的 table 和 memtable.skiplist 都有引用计数的设计, 其目的在于 badger gc 操作.
type Table struct {
sync.Mutex
*z.MmapFile
// ...
ref atomic.Int32 // For file garbage collection
// ...
}
type Skiplist struct {
height atomic.Int32
head *node
ref atomic.Int32
arena *Arena
OnClose func()
}
func (t *Table) DecrRef() error {
newRef := t.ref.Add(-1)
if newRef == 0 {
// 当无引用时, 进行删除操作.
for i := 0; i < t.offsetsLength(); i++ {
t.opt.BlockCache.Del(t.blockCacheKey(i))
}
if err := t.Delete(); err != nil {
return err
}
}
return nil
}badger get 读取数据的流程跟 leveldb, rocksdb 大同小异. badger 读取数据时, 先从 memtable 集合里查找, 然后再从 immutable memtables 集合里查找, 接着从上往下从 levels 各层进行查找.
level 0 层会有 key 范围重叠的情况, 所以要从所有符合条件的 sstable, 进行遍历查找. 到了 level 1 层后, 通过二分查找算法找到符合 key 范围的 sstable, level >= 1 层最多只有一个 sstable 满足 key 范围条件.
sstable 内部的查询是先从 bloomfilter 布隆过滤器中查询, 如果命中说明可能存在, 毕竟 bf 存在假阳的概率, 继续找到对应的 block, block 内部有个有序 offset 集合做二分查找. 只有没找到, 就一直往下面的 level 进行遍历查找, 直到成功.